






一、基础知识
1、张量
(1)、张量构建
张量并非是一个仅应用于深度学习框架中的概念,而是一个数学概念。几何代数中定义的张量向量和矩阵的推广,比如我们可以将标量视为零阶张量,矢量可以视为一阶张量,矩阵就是二阶张量,以此类推。

在PyTorch中有多种方式对张量进行构建,大多数类似于Numpy。
(2)、张量操作
张量构建后,便涉及对张量的各种操作,其中包含运算、索引以及维度变换。对于张量运算,此处以相加为例。与Numpy不同的第三种方式称为原值修改,即改变当前张量值,应用当前张量实例的“add_”方法。其中,符号“_”在pyTorch中表示原值修改符。

对于张量的维度变换,常见的方法有torch.view(shape)、torch.squeeze(index)。其中,a = torch.view()只会改变原张量的观察结构,并未进行深拷贝,即对原张量进行元素改变,张量a的元素也会发生变化。若要进行深拷贝,可以先使用函数torch.clone(),再使用torch.view()。
torch.squeeze(index)则用于对多余维度进行压缩。所谓多余,即该函数仅压缩多个维度中维度数为1的维度。若维度索引处的维度不为1,则该函数不会报错也不会改变原张量。
张量的索引操作则类似于Numpy,此处不多赘述。
2、张量自动求导
自动求导的数学基础包含雅克比矩阵和复合函数的链式求导。
(1)、雅克比矩阵
设为m维列向量,
为n维列向量函数。那么,
对
的偏导,也被称为
对
的雅克比,常记为
,即:
(2)、链式求导
那么,以LR的损失函数为例,损失函数对
的导数为:
。那么,损失函数
对参数
的导数便为:
可以看出,雅克比矩阵的向量偏导遵循分子布局,即“标量不变,向量变;前纵向拉伸,后横向拉伸”规则。与分母布局偏导形式互为转置。
(3)、动态计算图(DCG)
DCG即张量和运算结合起来创建的动态计算图,可以较为清晰地体会pytorch官方文档的一些参数说明。
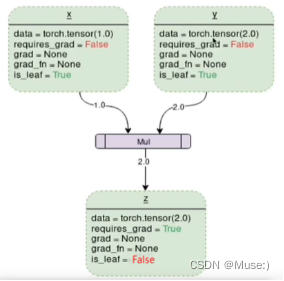
- 其中,z由x与y两个零阶张量相乘得到。此时:
- 参数“requires_grad”控制该张量是否需要被跟踪求导;
- “grad”为梯度值,在未进行反向传播时均为None;
- “grad_fn”为偏导方程,即对构成该复合函数且“requires_grad = True”的张量作偏导后的方程;
- “is_leaf”则判断该张量是否为叶子张量,当“requires_grad = True”且为叶子张量,才能在反向传播时得到相应的梯度值。“requires_grad = False”一定为叶子张量;“requires_grad = True”但由用户创建的张量,也为叶子张量,即网络的初始化参数。
- 通过tensor.retain_grad()能够保留任意非叶子张量的梯度值。
需要注意的是,重复执行反向传播,最终的张量梯度值是累加的,所以一般在反向传播之前需把梯度清零,后续内容将介绍pytorch的optimizer方法处理该问题。除此之外,如果想修改tensor的数值,但是又不希望被自动求导记录(即不会影响反向传播),那么可以对 tensor.data 进行操作,修改tensor.data同样会改变tensor,但不会影响其反向传播。
还需要强调的一点是,pytorch只支持标量对标量、标量对张量的求导,不支持张量对张量、张量对标量的求导,即最终的复合函数要将其转化为标量形式进行反向传播。对于这种框架特性,下面将介绍两种方式对其进行处理。
第一种方法,可以对复合函数张量进行求和操作,即tensor.sum(),在反向传播之前将其转化为标量。下面将以张量对张量求导为例进行说明,代码如下:
import torch
#构建自定义张量
x = torch.tensor(3.0,requires_grad = True)
p = torch.ones(2,2,requires_grad=True)
#复合张量
z = 2*x+p
#将复合张量转化为标量
z = z.sum()
#反向传播
z.backward()
print(p.grad.data)首先,分别构建一个标量以及一个
的张量
,经过一个复合函数得到的复合张量
同样为一个二阶张量:
对张量进行求和进行标量求导,可得:
第二种方法则是采用pytorch的预留参数,即为tensor.backward(tensor)方法传入形如复合张量的全1张量形参。
import torch
#构建自定义张量
x = torch.tensor(3.0,requires_grad = True)
p = torch.ones(2,2,requires_grad=True)
#复合张量
z = 2*x+p
#构建形如复合张量的全1张量
v = torch.ones(p.shape, dtype=torch.float)
#反向传播
z.backward(v)
print(p.grad.data)二、Pytorch模块及实践
如果对深度学习领域有过了解,那么应用该技术实现目标需求大致可以分为如下诸多流程:
- 数据预处理;
- 特征工程(机器学习);
- 模型选择/模型设计;
- 损失函数及优化方法设计;
- 前向及后向传播;
- 参数更新。
笔者认为,对于上述诸多流程,Pytorch、Tensorflow等深度学习框架主要实现的,便是更模块化地构建网络结构、损失函数以及优化方法;更高效化地实现前向及后向传播。因此,想要熟练的应用Pytorch框架解决实际问题,便要尽可能的熟悉其支持的相关模块。
1、Pytorch深度学习模块
(1)、基本配置
首先,需要对模型训练设备进行指定,即使用CPU还是GPU训练模型;若拥有多块GPU,那么使用哪些GPU进行并行训练。
# 若使用CPU进行训练,无需进行下述设置
# 方案一:使用os.environ
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 指明调用索引为0的GPU
# 方案二:使用“torch.device”,后续对要使用GPU的变量使用.to(device)
import torch
devices = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")对于第一种方案,后续需要置于该设备中的模型或张量应采用函数xxx.cuda();对于第二种方案,则采用函数xxx.to_device(devices) 。
除此之外,网络结构训练所需要的超参数同样需要事先定义,诸如学习率、批次训练样本个数、最大训练轮次以及读取数据的线程个数等。
# 超参数字典定义
hyper_params = {'lr':1e-4,
'batch_size':256,
'max_epochs':100,
'num_works':4}(2)、数据自定义读取
对于训练数据,我们需要将不同格式的数据集转化为tensor类型。其中,Pytorch拥有内置的数据集,关于这类数据集的读取和载入是十分方便的,只需借助Pytorch的官方图像处理工具库torchvision。而且这种数据集往往也无需过多的预处理,常用于基础学习与自定义算法的验证,诸如MNIST、CIFAR10等。同时,torchvision也可以对图像数据进行整体翻转、剪裁及格式转换等操作。例如下面的代码,FashionMNIST的图像数据为共有10个类别的服装图片,分辨率为32*32。我们应用torchvision降低了图像数据的分辨率,使其变为28*28。
# 方式一:读取Pytorch内置数据集
from torchvision import datasets
from torchvision import transforms
# 设置图像变化形式
image_size = 28
data_transform = transforms.Compose([transforms.ToPILImage(),
transforms.Resize(image_size),
transforms.ToTensor()])
# Pytorch内置数据集提取
train_data = datasets.FashionMNIST(root='./', train = True,
download = True,
transform = data_transform)
test_data = datasets.FashionMNIST(root='./', train = False,
download = True,
transform = data_transform)
# -----------------------------------------------------------------
# 方式二:自定义Dataset类
# csv数据下载链接: https://www.kaggle.com/zalando-research/fashionmnist
# csv表格数据行为样本项,第一列为标签列,第二列至最后一列为像素值
# 上述csv文件数据分辨率已为28*28
from torch.utils.data import Dataset
import numpy as np
import pandas as pd
class FMDataset(Dataset):
def __init__(self, data_df, transform = None):
self.df = data_df
self.transform = transform
# 此处np.uint8为专门存储像素值的类型
self.images = self.df.iloc[:,1:].values.astype(np.uint8)
self.labels = self.df.iloc[:,0].values
def __len__(self):
return len(self.labels)
def __getitem__(self, index):
# 为图像数据添加一个灰度单通道维度
image = self.images[index].reshape(28,28,1)
label = int(self.labels[index])
# 若存在图像变化,便对归一化图像进行变化
if self.transform:
image = self.transform(image)
else:
image = torch.tensor(image/255.0,dtype = torch.float)
label = torch.tensor(label,dtype = torch.int64)
return image, label
train_df = pd.read_csv(r'./FashionMNIST/fashion-mnist/train.csv')
test_df = pd.read_csv(r'./FashionMNIST/fashion-mnist/test.csv')
train_data_FM = FMDataset(train_df, data_transform)
test_data_FM = FMDataset(test_df, data_transform) 然而,对于我们自己的csv格式数据集或第三方数据,这种数据载入形式便太过简单了,无法实现所需功能。因此,Datawhale的Pytorch课程提供了一个自定义Datasets类的框架,即构建Pytorch的Datasets子类,该过程将应用到数据分析及机器学习领域常用的三方库Pandas。
将数据加载至内存后,为了便于训练和测试过程中的数据流,可以进一步定义DataLoader类进行数据加载。其中,“shuffle”参数为是否打乱数据顺序;“drop_list”参数为是否删除最后一个样本数不足一个batch_size的数据。
from torch.utils.data import DataLoader
train_data = DataLoader(train_data_FM,
batch_size = hyper_params['batch_size'],
shuffle = True,
num_workers = hyper_params['num_works'],
drop_last = True)
test_data = DataLoader(test_data_FM,
batch_size = hyper_params['batch_size'],
shuffle = False,
num_workers = hyper_params['num_works'])train_data与test_data两个实例均具有“__iter__”方法,即我们可以将其转化为一个迭代器对某个批次的数据进行检查。此处需要注意,如果大家使用jupyter实现上述代码,“num_works”参数应设为默认值0,即串行读取数据,不然该代码块将长时间无响应,其他IDE将不会出现这种情况。
import matplotlib.pyplot as mp
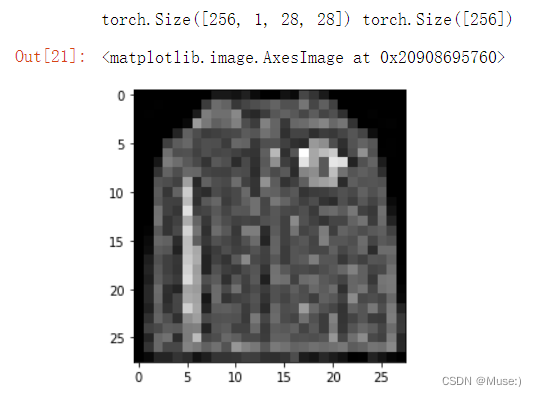
image, label = next(iter(train_data))
print(image.shape, label.shape)
mp.imshow(image[0][0],cmap='gray')从下图结果中可以看到,image为一个batch的单通道二维图像数据集,label则为一个batch图像数据的分类结果。
(3)、模型构建
网络结构的构建主要围绕着两个部分,一个是自定义torch.nn.Module类;另一个是构建前向传播函数。换句话说,网络模型的构建是通过层模块化定义以及层模块传播顺序实现的。其中,Pytorch已经提供了诸如nn.Conv2d、nn.MaxPool2d、nn.Linear、nn.ReLu、nn.Dropout等很多种类的层结构。首先,为fashion-mnist问题构建一个简单的三层多分类神经网络结构作为例子:
import torch
from torch import nn
class ANN(nn.Module):
# 定义两个隐层与输出层的结构
def __init__(self):
# 将ANN对象self转换为父类nn.Module的对象,然后该对象调用init函数进行必要的初始化,
# 即子类ANN对继承自父类的属性进行初始化
super(ANN, self).__init__()
self.hidden1 = nn.Linear(28*28, 256)
self.act1 = nn.ReLU()
self.hidden2 = nn.Linear(256, 256)
self.act2 = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向传播顺序,即如何根据输入x计算模型输出
def forward(self, x):
a1 = self.act1(self.hidden1(x))
a2 = self.act2(self.hidden2(a1))
return self.output(a2)
model = ANN()
model = model.cuda()读者可能在此处产生些许困惑。既然是多分类问题,那么为什么没有为输出层设置Softmax激活函数呢? 其实,这取决于Pytorch的交叉熵损失函数的数学定义。参考Pytorch官方文档中的nn.CrossEntropyLoss()交叉熵损失函数的计算公式可知,Softmax激活函数被整合进了损失函数当中,因此在输出层不需要施加Softmax激活函数。所以,在后续的学习与应用过程中,需要对模型与损失函数进行统筹考虑。
持续更新中...
















 7902
7902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









