









from pyspark.sql import SparkSession
from random import random
from operator import add
spark = SparkSession.builder \
.master('local[*]') \
.appName('Pi Demo') \
.getOrCreate();
sc = spark.sparkContext
# 利用蒙特卡洛模拟方法计算
n = 100000 * 20
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = sc.parallelize(range(1, n+1), 20).map(f).reduce(add)
print('Pi is roughly %f' % (4.0 * count / n))
提交运行
【在搭建的虚拟集群内,开启Hadoop,提交py文件运行】
【去文件所在目录下,进入cmd,输以下命令】
# 1
spark-submit first_pyspark_pi.py --master yarn --deploy-mode client
# 2
spark-submit first_pyspark_pi.py --master local
# 3
spark-submit first_pyspark_pi.py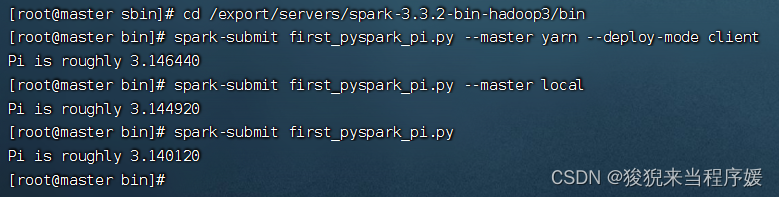
















 2818
2818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









