






目录
ETL是指 Extract、Transfrom 和 Load 的简称。
用来描述将数据从数据源经过抽取、转换、加载至终端的一系列处理过程。
认识资料单元格式
在 MovieLens | GroupLens 下载一个精简示例数据集 ml-latest-small.zip
【
README.txt 查看一下,看看都保存什么数据
- ratings.csv 电影评分记录
- userId 用户ID
- movieId 电影ID
- rating 用户给电影的打分
- timestamp 用户给出评价的时间戳
】
下载在windows

在python文件目录下打开cmd,使用 pyhon 文件名.py 运行python文件
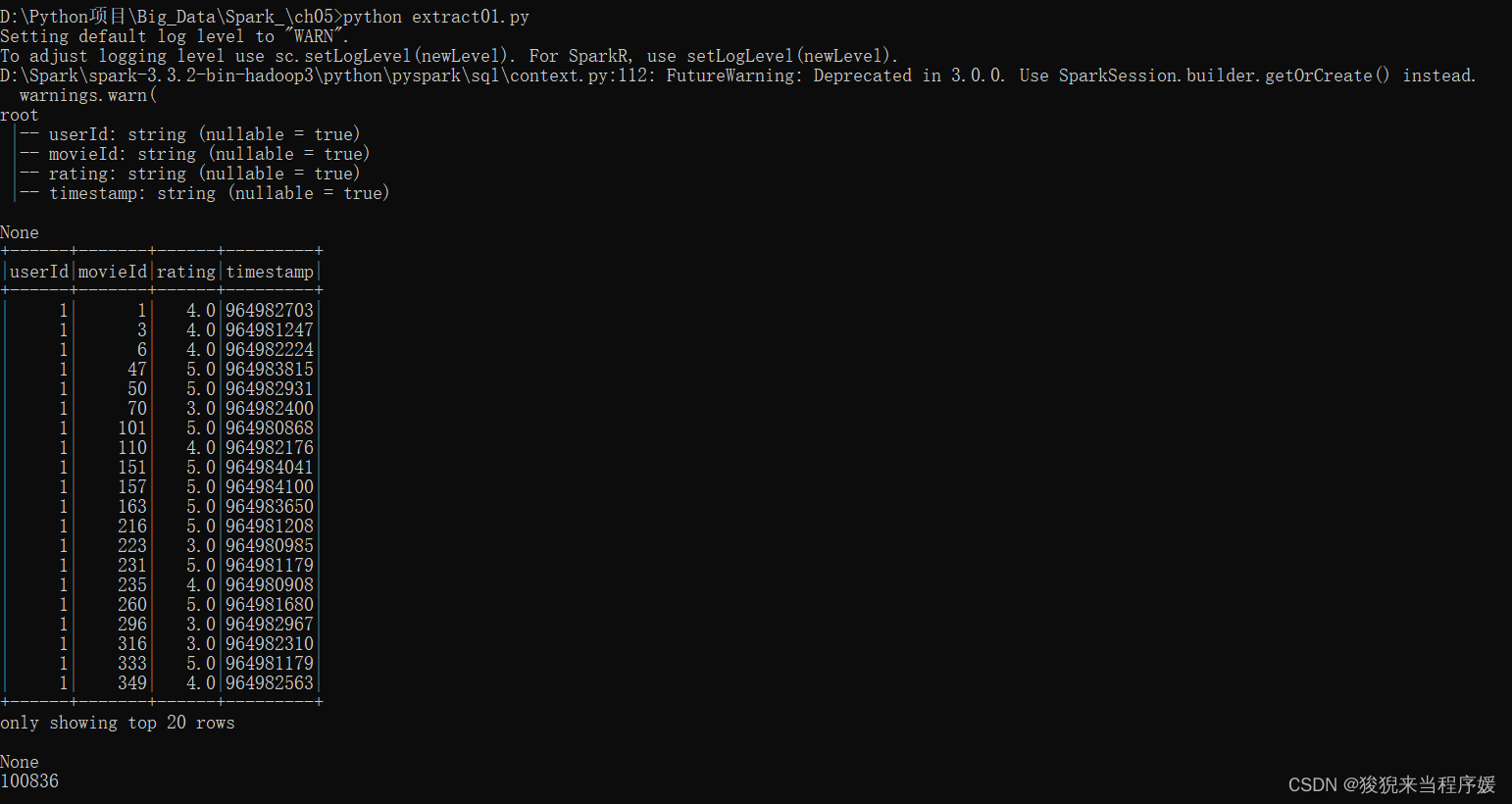
extract01.py
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import to_timestamp
# 创建 sc 对象
spark = SparkSession.builder \
.master('local[*]') \
.appName('PySpark ETL') \
.getOrCreate()
sc = spark.sparkContext
#
sqlContext = SQLContext(sc)
# 相对路径,文件包含标题行
# header=True 表示第一行是标题行
df = spark.read.csv('/export/data/PySpark_ETL/ml-latest-small/ratings.csv', header=True)
# 打印默认的字段类型信息
# 具体内容 & 资料单元格格式
print(df.printSchema())
# 打印前20条数据
# 观察数据
print(df.show())
# 打印总行数
# 了解数据集大小
print(df.count())
自动类型推断的抽取数据 extract02.py
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import to_timestamp
# 创建 sc 对象
spark = SparkSession.builder \
.master('local[*]') \
.appName('PySpark ETL') \
.getOrCreate()
sc = spark.sparkContext
# inferSchema=True 自动推断数据类型
df = spark.read.csv('C:/Users/Administrator/Downloads/ml-latest-small/ml-latest-small/ratings.csv', header=True, inferSchema=True)
print(df.printSchema())
print(df.show(5))
print(df.count())
print('\n')
df2 = spark.read.csv('C:/Users/Administrator/Downloads/ml-latest-small/ml-latest-small/tags.csv', header=True, inferSchema=True)
print(df2.printSchema())
print(df2.show(5))
print(df2.count())
print('\n')
df3 = spark.read.csv('C:/Users/Administrator/Downloads/ml-latest-small/ml-latest-small/movies.csv', header=True, inferSchema=True)
print(df3.printSchema())
print(df3.show(5))
print(df3.count())
print('\n')
df4 = spark.read.csv('C:/Users/Administrator/Downloads/ml-latest-small/ml-latest-small/links.csv', header=True, inferSchema=True)
print(df4.printSchema())
print(df4.show(5))
print(df4.count())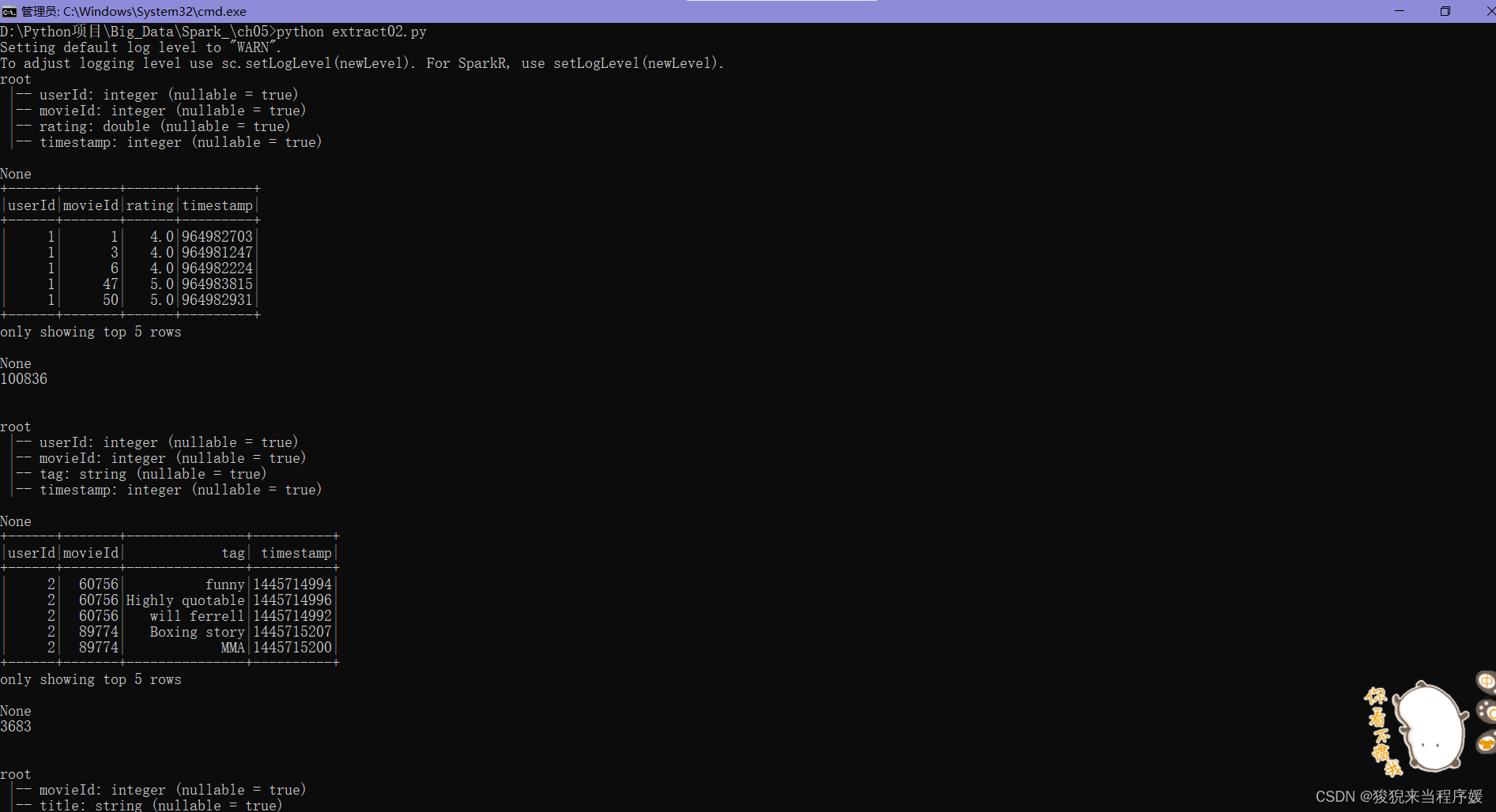
观察资料
主要用到三个库
numpy、matplotlib、Pandas
折线图
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
# 设置支持中文格式
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 准备数据
t = np.arange(0.0, 2.0, 0.01)
s = 1 + np.sin(2*np.pi*t)
fig, ax = plt.subplots()
# 设置窗口标题
fig.canvas.setWindowTitle('折线图示例')
# 绘图,折线图
ax.plot(t, s)
# 坐标轴设置
ax.set(xlabel='时间(s)', ylabel='电压(mv)', title='折线图')
ax.grid()
# 当前目录下保存图片
fig.savefig('line.png')
# 显示图片
plt.show()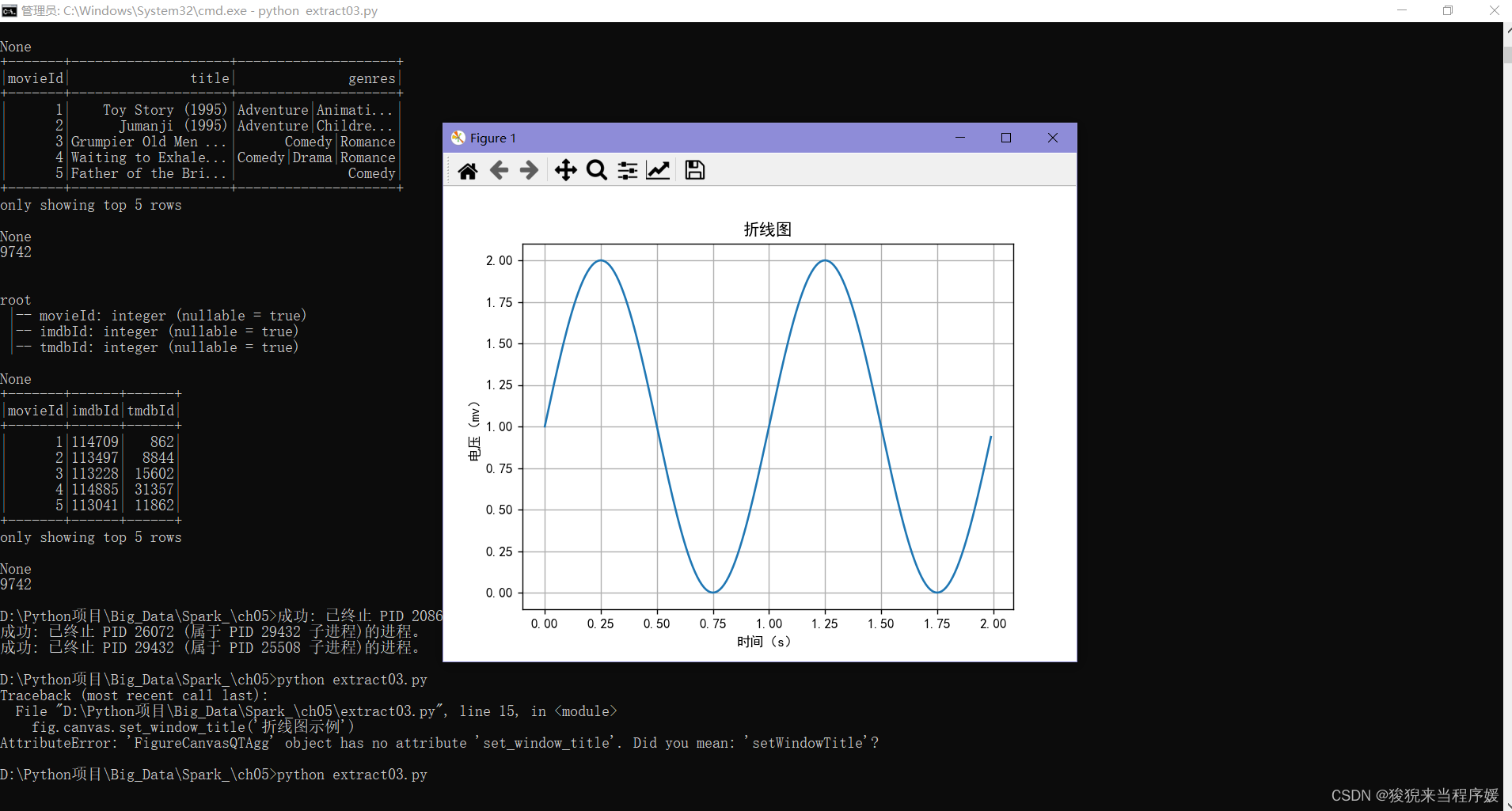
直方图
由一系列的高度不等的纵向条纹或线段表示 数据分布情况
一般横轴表示数据类型,纵轴表示分布情况
是数值数据分布的精确图形表示,是一个连续变量的概率分布估计
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
# 设置支持中文格式
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置随机数生成器种子参数
np.random.seed(20170907)
# 准备数据
mu = 100 # 均值
sigma = 15 # 标准差
# 随机生成 1024 个范围在[0,1]之间的数据
x = mu + sigma * np.random.randn(1024)
num_bins = 50
# 从plt上创建一个图形对象fig
fig, ax = plt.subplots()
# 设置格式
# 设置窗口标题
fig.canvas.setWindowTitle('直方图示例')
# 直方图数据
n, bins, patches = ax.hist(x, num_bins, density=1)
# 添加'best fit'线
y = ((1/(np.sqrt(2 * np.pi) * sigma)) *
np.exp(-0.5 * (1/sigma * (bins - mu)) ** 2))
# 绘图
ax.plot(bins, y, '--')
# 坐标轴设置
ax.set_xlabel('人数')
ax.set_ylabel('概率密度')
ax.set_title(r'$\mu=100$, $\sigma=15$')
# 调整间距防止ylabel剪切
fig.tight_layout()
# 当前目录下保存
fig.savefig('histogram.png')
# 显示图片
fig.show()
多图示例
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.gridspec as gridspec
# 设置支持中文
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像时负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# plt.rcParams['savefig.dpi'] 参数用来设置图片质量高低
# plt.rcParams['savefig.dpi'] = 300
# plt.rcParams['figure.dpi'] = 300
# 分配 2×2 个区域进行绘图
fig, ((ax1, ax2), (ax3,ax4)) = plt.subplots(2, 2)
# 设置窗口标题
fig.canvas.setWindowTitle('多图示例')
# 第一个图绘制
delta = 0.025
x = np.arange(-3.0, 3.0, delta)
y = np.arange(-2.0, 2.0, delta)
X, Y = np.meshgrid(x, y)
z1 = np.exp(-X**2 - Y**2)
z2 = np.exp(-(X-1)**2 - (Y-1)**2)
z = (z1-z2) * 2
CS = ax1.contour(X, Y, z)
ax1.clabel(CS, inline=1, fontsize=10)
ax1.set(title='等高线')
# 第二个图绘制
x = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
y1 = [6, 5, 8, 5, 6, 6, 8, 9, 8, 10]
y2 = [5, 3, 6, 4, 3, 4, 7, 4, 4, 6]
y3 = [4, 1, 2, 1, 2, 1, 6, 2, 3, 2]
# 柱状图
ax2.bar(x, y1, label='label11', color='red')
ax2.bar(x, y2, label='label12', color='orange')
ax2.bar(x, y3, label='label13', color='green')
ax2.set(title='柱状图', ylabel='数量', xlabel='类型')
# 第三个图绘制
w = 3
Y, X = np.mgrid[-w:w:100j, -w:w:100j]
U = -1 - X**2 + Y
V = 1 + X - Y**2
speed = np.sqrt(U**2 + V**2)
gs = gridspec.GridSpec(nrows=3, ncols=2, height_ratios=[1, 1, 2])
# streamplot
ax3.streamplot(X, Y, U, V, density=[0.5, 1])
ax3.set_title('密度')
# 第四个图绘制
np.random.seed(20170907)
N = 100
r0 = 0.6
x = 0.9 * np.random.rand(N)
y = 0.9 * np.random.rand(N)
area = (20 * np.random.rand(N)) ** 2
c = np.sqrt(area)
r = np.sqrt(x**2 + y**2)
area1 = np.ma.masked_where(r < r0, area)
area2 = np.ma.masked_where(r >= r0, area)
ax4.scatter(x, y, s=area1, marker='^', c=c)
ax4.scatter(x, y, s=area2, marker='o', c=c)
theta = np.arange(0, np.pi/2, 0.01)
ax4.plot(r0 * np.cos(theta), r0 * np.sin(theta))
ax4.set_title('分类示例')
fig.tight_layout()
fig.savefig('mulPlot.png')
plt.show()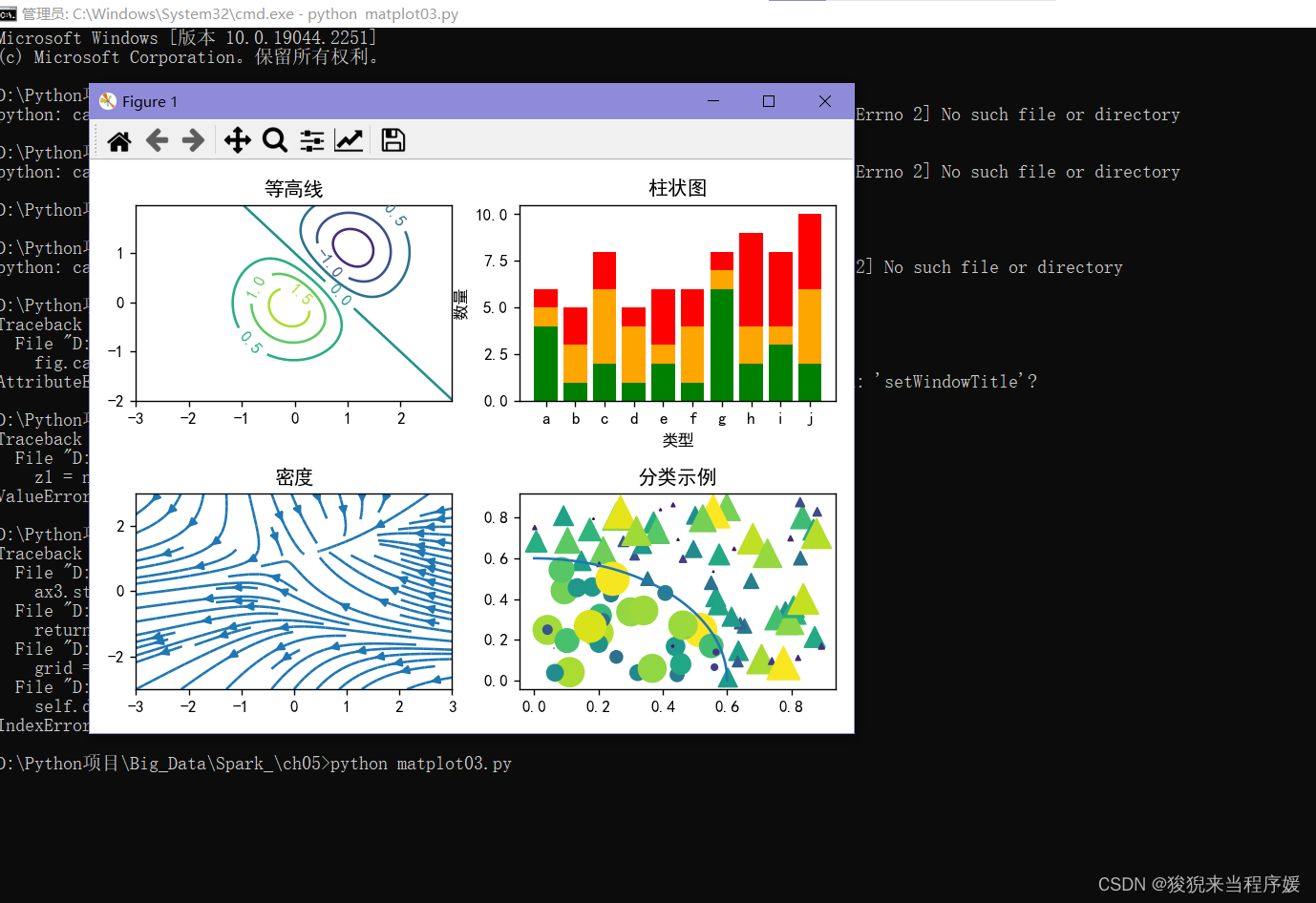
绘制3D图形
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.gridspec as gridspec
# 支持中文,避免乱码
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像时负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# 洛伦兹吸引子(Lorenz attractor)用于混沌现象 —— 蝴蝶效应
def lorenz(x, y, z, s=10, r=28, b=2.667):
x_dot = s*(y-x)
y_dot = r*x - y - x*z
z_dot = x*y - b*z
return x_dot, y_dot, z_dot
dt = 0.01
num_steps = 20000
xs = np.empty(num_steps + 1)
ys = np.empty(num_steps + 1)
zs = np.empty(num_steps + 1)
# 初始值
xs[0], ys[0], zs[0] = (0., 1., 1.05)
for i in range(num_steps):
x_dot, y_dot, z_dot = lorenz(xs[i], ys[i], zs[i])
xs[i + 1] = xs[i] + (x_dot*dt)
ys[i + 1] = ys[i] + (y_dot * dt)
zs[i + 1] = zs[i] + (z_dot * dt)
# 绘制
fig = plt.figure()
plt.subplot()
# 设置窗口标题
fig.canvas.setWindowTitle('3D图')
# ax = fig.gca(projection='3d')
ax = fig.add_axes(Axes3D(fig))
# lw是linewidth缩写,线条宽度
ax.plot(xs, ys, zs, lw=1, color='purple')
ax.set_xlabel('X轴')
ax.set_ylabel('Y轴')
ax.set_zlabel('Z轴')
ax.set_title('3D图形')
fig.tight_layout()
# 当前目录下保存
fig.savefig('3d.png')
plt.show()
观察资料示例
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import to_timestamp
# 创建 sc 对象
spark = SparkSession.builder \
.master('local[*]') \
.appName('PySpark ETL') \
.getOrCreate()
sc = spark.sparkContext
#
sqlContext = SQLContext(sc)
# 读取csv文件
df = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/ratings.csv', header=True, inferSchema=True)
print(df.show(10))
# 观察字段数据类型
print(df.printSchema())
# 将df对象中的数据进行统计分析
print(df.summary().show())
# df.select('rating').summary().show()
# 打印资料的行数量和列数量
print(df.count(), len(df.columns))
# 删除所有列的空值
dfNotNull = df.na.drop()
print(dfNotNull.count(), len(dfNotNull.columns))
# 创建视图movie
df.createOrReplaceTempView('movie')
#spark sql
# 按用户评分分组,并统计每个分组的用户评价记录数量
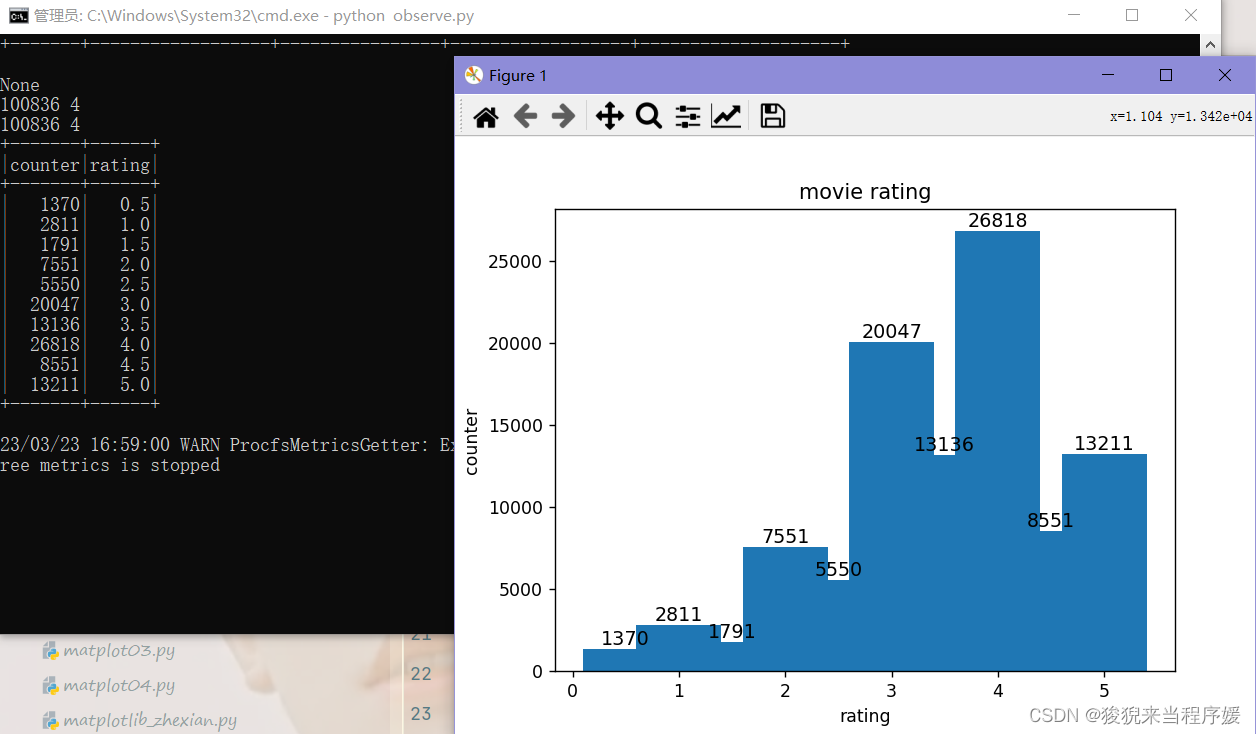
df2 = spark.sql('select count(*) as counter, rating from movie group by rating order by rating asc')
df2.show()
from matplotlib import pyplot as plt
# Pandas >= 0.19.2 must be installed
# 将DataFrames对象转换成Pandas对象格式
pdf = df2.toPandas()
x = pdf['rating']
y = pdf['counter']
plt.xlabel('rating')
plt.ylabel('counter')
plt.title('movie rating')
plt.bar(x, y)
# 显示数值标签
for x1, y1 in zip(x,y):
plt.text(x1, y1+0.05, '%.0f' % y1, ha='center', va='bottom', fontsize=11)
plt.show()
sc.stop()开启Hadoop
去/export/servers/hadoop-3.3.3/sbin(hadoop的sbin目录下)
输入 start-all.sh
上传数据文件至HDFS
cd /export/data/PySpark_ETL
hdfs dfs -put ml-latest-small
hdfs dfs -copyFromLocal /local/data /hdfs/data:将本地文件上传到 hdfs
上(原路径只能是一个文件)
hdfs dfs -put /tmp/ /hdfs/ :和 copyFromLocal 区别是,put 原路径可以是文件夹等
hadoop fs -ls / :查看根目录文件
hadoop fs -ls /tmp/data:查看/tmp/data目录
hadoop fs -cat /tmp/a.txt :查看 a.txt,与 -text 一样
hadoop fs -mkdir dir:创建目录dir
hadoop fs -rmr dir:删除目录dir

选择、筛选与聚合
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import from_unixtime, to_timestamp
spark = SparkSession.builder \
.master('local[*]') \
.appName('PySpark ETL') \
.getOrCreate()
# 相对路径,文件包含标题行
df = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/ratings.csv', header=True)
# 转换rating类型
# 读取数据时,没有类型推断,使用df.rating.cast('double')进行类型转换
df = df.withColumn('rating', df.rating.cast('double'))
# 新增一列
df = df.withColumn('date', from_unixtime(df.timestamp.cast('bigint'), 'yyyy-MM-dd'))
df = df.withColumn('date', df.date.cast('date'))
# 删除 timestamp 列
df = df.drop('timestamp')
df2 = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/movies.csv', header=True)
# 'movieId'不明确,需要指定
df3 = df.join(df2, df.movieId == df2.movieId, 'inner') \
.select('userId', df.movieId, 'title', 'date', 'rating')
from pyspark.sql.functions import udf
# 定义一个普通函数
def isLike(v):
if v > 4:
return True
else:
return False
# 创建udf函数
from pyspark.sql.types import BooleanType
# 创建了一个自定义函数,将普通函数 isLike 封装成 udf 函数,返回类型为 BooleanType
udf_isLike = udf(isLike, BooleanType())
# 利用函数isLike对rating值进行计算,保存到新列isLike中
df3 = df3.withColumn('isLike', udf_isLike(df3['rating']))
print(df3.show())
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types import StringType
# 定义pandas udf函数,用于Grouped data
# 对函数fmerge进行修饰,表示定义了一个Pandas UDf函数
@ pandas_udf(StringType(), PandasUDFType.GROUPED_AGG)
def fmerge(v):
return ','.join(v)
df5 = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/tags.csv', header=True)
df5 = df5.drop('timestamp')
# groupBy聚合
df7 = df5.groupBy(['userId', 'movieId']).agg(fmerge(df5['tag']))
df7 = df7.withColumnRenamed('fmerge(tag)', 'tags')
# select选择
df6 = df3.join(df7, (df3.movieId == df7.movieId) & (df3.userId == df7.userId)) \
.select(df3.userId, df3.movieId, 'title', 'date', 'tags', 'rating', 'isLike') \
.orderBy(['date'], acending=[0])
#filter筛选
df6 = df6.filter(df.date>'2015-10-25')
df6.show(20)
# df6.show(20, False)
spark.stop()存储数据
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import from_unixtime, to_timestamp
spark = SparkSession.builder \
.master('local[*]') \
.appName('PySpark ETL') \
.getOrCreate()
# 相对路径,文件包含标题行
df = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/ratings.csv', header=True).cache()
# 转换rating类型
# 读取数据时,没有类型推断,使用df.rating.cast('double')进行类型转换
df = df.withColumn('rating', df.rating.cast('double'))
# 新增一列
df = df.withColumn('date', from_unixtime(df.timestamp.cast('bigint'), 'yyyy-MM-dd'))
df = df.withColumn('date', df.date.cast('date'))
# 删除 timestamp 列
df = df.drop('timestamp')
df2 = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/movies.csv', header=True).cache()
# 'movieId'不明确,需要指定
df3 = df.join(df2, df.movieId == df2.movieId, 'inner') \
.select('userId', df.movieId, 'title', 'date', 'rating').cache()
from pyspark.sql.functions import udf
# 定义一个普通函数
def isLike(v):
if v > 4:
return True
else:
return False
# 创建udf函数
from pyspark.sql.types import BooleanType
# 创建了一个自定义函数,将普通函数 isLike 封装成 udf 函数,返回类型为 BooleanType
udf_isLike = udf(isLike, BooleanType())
# 利用函数isLike对rating值进行计算,保存到新列isLike中
df3 = df3.withColumn('isLike', udf_isLike(df3['rating']))
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types import StringType
# 定义pandas udf函数,用于Grouped data
# 对函数fmerge进行修饰,表示定义了一个Pandas UDf函数
@pandas_udf(StringType(), PandasUDFType.GROUPED_AGG)
def fmerge(v):
return ','.join(v)
df5 = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/tags.csv', header=True).cache()
df5 = df5.drop('timestamp')
print('aaaa')
# groupBy聚合
df7 = df5.groupBy(['userId', 'movieId']).agg(fmerge(df5['tag'])).cache()
df7 = df7.withColumnRenamed('fmerge(tag)', 'tags')
# select选择
df6 = df3.join(df7, (df3.movieId == df7.movieId) & (df3.userId == df7.userId)) \
.select(df3.userId, df3.movieId, 'title', 'date', 'tags', 'rating', 'isLike') \
.orderBy(['date'], acending=[0]).cache()
#filter筛选
df6 = df6.filter(df.date>'2015-10-25').cache()
df6.show(20)
# df6.show(20, False)
######################################################################################
# 存储数据
# saveAsTextFile 进行数据存储时,如果目录存在,会报错
# 数据量大时,应该存在 HDFS 系统上
# 存在过多的小任务的时候,可以通过 RDD.coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本,避免Shuffle导致
df6.rdd.coalesce(1).saveAsTextFile('movie-out')
# 存储数据CSV格式
# write.format,指定基础输出数据源,字符串,数据源的名称,例如‘json’, ‘parquet’
df6.coalesce(1).write.format('csv') \
.option('header', 'true').save('movie-out-csv')
# parquet格式
df6.write.format('parquet').save('movie-out-parquet')
# json格式
df6.coalesce(1).write.format('json').save('movie-out-json')
spark.stop()
Spark存储数据到SQL Server
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.context import SQLContext
from pyspark.sql.functions import from_unixtime, to_timestamp
spark = SparkSession.builder \
.master('local[*]') \
.appName('PySpark ETL') \
.getOrCreate()
# 相对路径,文件包含标题行
df = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/ratings.csv', header=True).cache()
# 转换rating类型
# 读取数据时,没有类型推断,使用df.rating.cast('double')进行类型转换
df = df.withColumn('rating', df.rating.cast('double'))
# 新增一列
df = df.withColumn('date', from_unixtime(df.timestamp.cast('bigint'), 'yyyy-MM-dd'))
df = df.withColumn('date', df.date.cast('date'))
# 删除 timestamp 列
df = df.drop('timestamp')
df2 = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/movies.csv', header=True).cache()
# 'movieId'不明确,需要指定
df3 = df.join(df2, df.movieId == df2.movieId, 'inner') \
.select('userId', df.movieId, 'title', 'date', 'rating').cache()
from pyspark.sql.functions import udf
# 定义一个普通函数
def isLike(v):
if v > 4:
return True
else:
return False
# 创建udf函数
from pyspark.sql.types import BooleanType
# 创建了一个自定义函数,将普通函数 isLike 封装成 udf 函数,返回类型为 BooleanType
udf_isLike = udf(isLike, BooleanType())
# 利用函数isLike对rating值进行计算,保存到新列isLike中
df3 = df3.withColumn('isLike', udf_isLike(df3['rating']))
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types import StringType
# 定义pandas udf函数,用于Grouped data
# 对函数fmerge进行修饰,表示定义了一个Pandas UDf函数
@pandas_udf(StringType(), PandasUDFType.GROUPED_AGG)
def fmerge(v):
return ','.join(v)
df5 = spark.read.csv('D:/Python项目/Big_Data/Spark_/ch05/ml-latest-small/ml-latest-small/tags.csv', header=True).cache()
df5 = df5.drop('timestamp')
print('aaaa')
# groupBy聚合
df7 = df5.groupBy(['userId', 'movieId']).agg(fmerge(df5['tag'])).cache()
df7 = df7.withColumnRenamed('fmerge(tag)', 'tags')
# select选择
df6 = df3.join(df7, (df3.movieId == df7.movieId) & (df3.userId == df7.userId)) \
.select(df3.userId, df3.movieId, 'title', 'date', 'tags', 'rating', 'isLike') \
.orderBy(['date'], acending=[0]).cache()
#filter筛选
df6 = df6.filter(df.date>'2015-10-25').cache()
df6.show(20)
# df6.show(20, False)
######################################################################################
# 存储数据
# 在对应的数据库中建表,表结构如下图所示
db_url = 'odbc:Mysql://localhost:3306;databaseName=数据库名;user=用户名;password=连接密码'
db_table = 'mm'
# overwrie重新生成表
df6.write.mode('overwrite').jdbc(db_url, db_table)
















 2473
2473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









