







文章目录
一、前置工作
请确认已经完成前置准备中的服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等操作。本篇文章基于上一篇文章《虚拟机上搭建Hadoop运行环境》。
二、HDFS集群环境部署
1.查看Hadoop安装包目录结构
cd /opt/module/hadoop-3.1.3
ls
或 ll
效果如图

通过可视化查看效果如下:
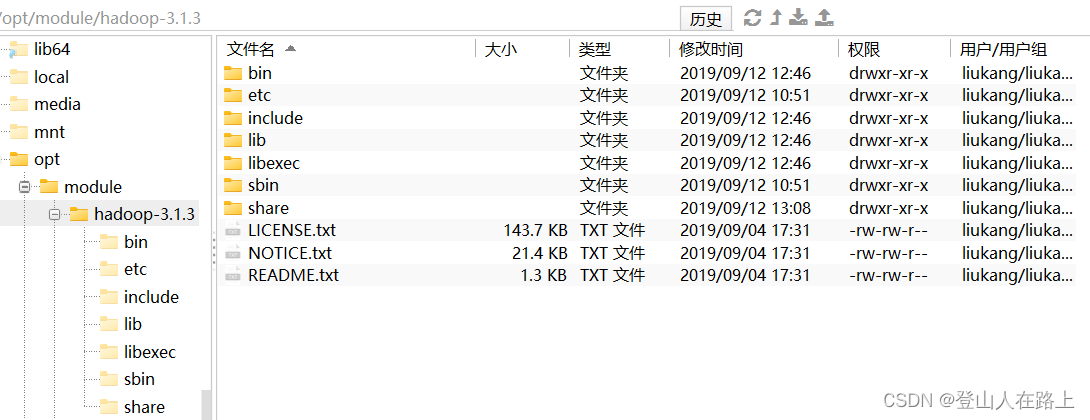
各个文件夹含义如下:
bin,存放Hadoop的各类程序(命令)
etc,存放Hadoop的配置文件
include,C语言的一些头文件
lib,存放Linux系统的动态链接库(.so文件)
libexec,存放配置Hadoop系统的脚本文件(.sh和.cmd)
licenses-binary,存放许可证文件
sbin,管理员程序(super bin)
share,存放二进制源码(Java jar包)
为了方便下次打开hadoop-3.1.3这个文件夹,我们可以给hadoop-3.1.3构建一个软链接
ln -s /opt/module/hadoop-3.1.3 hadoop
上述命令,就是建立了一个指向/opt/module/hadoop-3.1.3 的软链接 hadoop
此时,我们在软链接的目录下使用cd hadoop 打开的目录就是 /opt/module/hadoop-3.1.3 hadoop目录了
这里稍微扩展一下:
连接类型
分为硬连接和符号连接(软连接)两种,无论哪种,文件都保持同步变化
硬连接(默认):没有参数-s,它会在你选定的位置上生成一个和源文件大小相同的文件
软连接( -sf ):它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间
建立连接的命令格式:
ln [参数] [源文件或目录] [目标文件或目录]
命令参数:
-b 删除,覆盖以前建立的链接
-d 允许超级用户制作目录的硬链接
-f 强制执行
-i 交互模式,文件存在则提示用户是否覆盖
-n 把符号链接视为一般目录
-s 软链接(符号链接)
-v 显示详细的处理过程
2.修改配置文件,应用自定义设置
配置HDFS集群,我们主要涉及到如下文件的修改:
workers: 配置从节点(DataNode)有哪些
hadoop-env.sh: 配置Hadoop的相关环境变量
core-site.xml: Hadoop核心配置文件
hdfs-site.xml: HDFS核心配置文件
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
ps:$HADOOP_HOME是后续我们设置的环境变量,其指代Hadoop安装目录
2.1 配置workers文件
1.首先进入Hadoop目录
cd /opt/module/hadoop-3.1.3
 2.进入配置文件
2.进入配置文件
cd etc/hadoop
编辑workers文件
vim workers
填入下面的内容:
# 填入如下内容
hadoop100
hadoop102
hadoop103
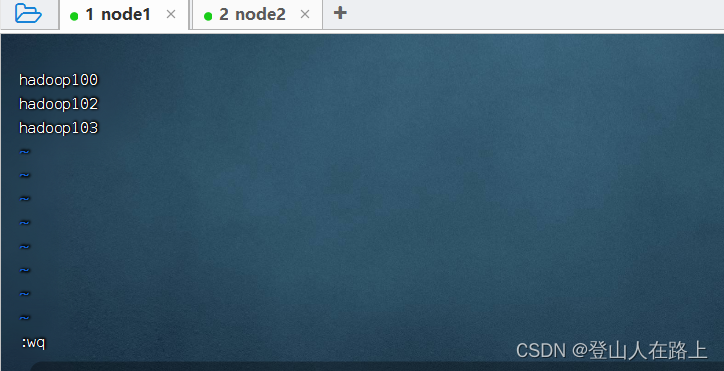
表明集群记录了三个从节点(DataNode)
2.2 配置hadoop-env.sh文件
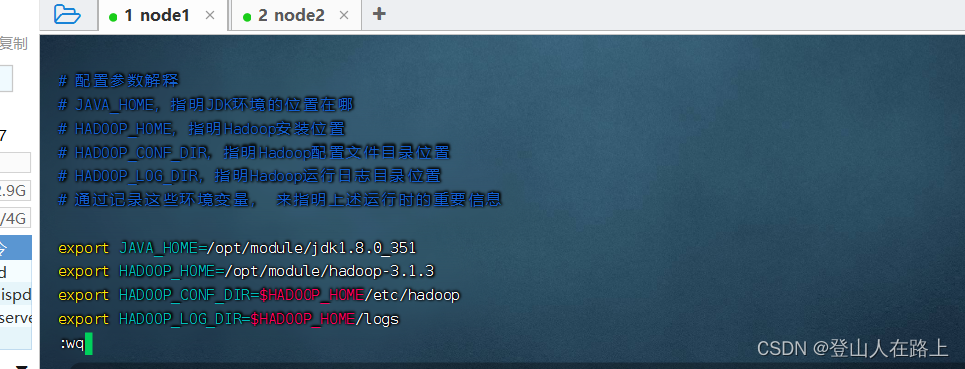
vim hadoop-env.sh
# 填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
JAVA_HOME,指明JDK环境的位置在哪
HADOOP_HOME,指明Hadoop安装位置
HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
通过记录这些环境变量, 来指明上述运行时的重要信息
在文件末尾填入如下内容并保存
2.3 配置core-site.xml文件
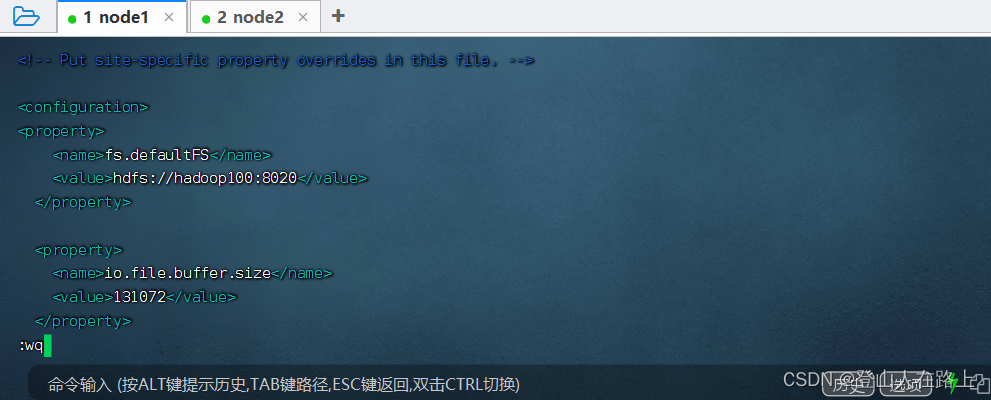
vim core-site.xml
在文件内部填入如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
key:fs.defaultFS
含义:HDFS文件系统的网络通讯路径
值:hdfs://hadoop100:8020
协议为hdfs://
namenode为hadoop100
namenode通讯端口为8020key:io.file.buffer.size
含义:io操作文件缓冲区大小
值:131072 bit
hdfs://hadoop100:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
表明DataNode将和Hadoop100的8020端口通讯,Hadoop100是NameNode所在机器
此配置固定了Hadoop100必须启动NameNode进程
2.4 配置hdfs-site.xml文件
vim hdfs-site.xml
添加如下内容:
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>hadoop100,hadoop102,hadoop103</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
key:dfs.datanode.data.dir.perm
含义:hdfs文件系统,默认创建的文件权限设置
值:700,即:rwx------
key:dfs.namenode.name.dir
含义:NameNode元数据的存储位置
值:/data/nn,在node1节点的/data/nn目录下
key:dfs.namenode.hosts
含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)
值:Hadoop100、Hadoop102、Hadoop103,这三台服务器被授权
key:dfs.blocksize
含义:hdfs默认块大小
值:268435456(256MB)
key:dfs.namenode.handler.count
含义:namenode处理的并发线程数
值:100,以100个并行度处理文件系统的管理任务
key:dfs.datanode.data.dir
含义:从节点DataNode的数据存储目录
值:/data/dn,即数据存放在Hadoop100、Hadoop102、Hadoop103,三台机器的/data/dn内
3. 准备数据目录
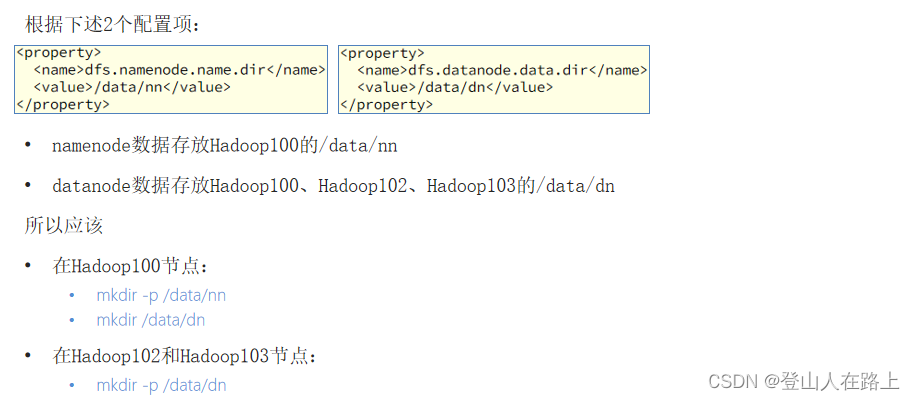
hadoop100节点:
mkdir -p /data/nn
mkdir /data/dn
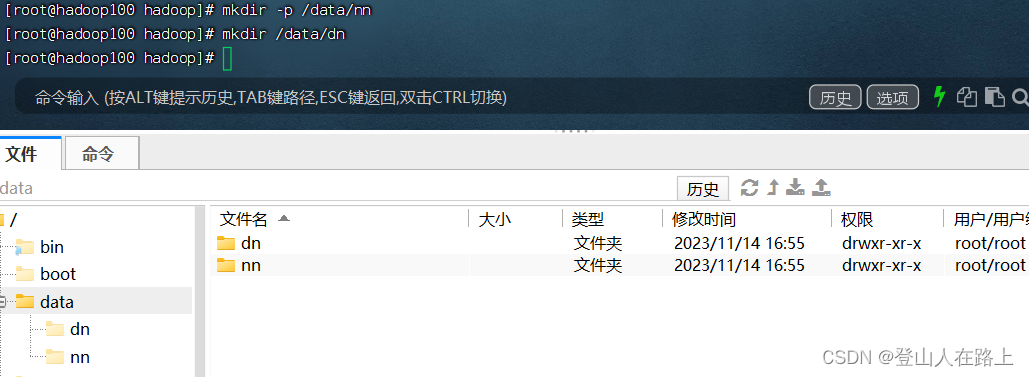
Hadoop102和 Hadoop103
mkdir -p /data/dn
4.配置SSH免密登录
在每一台机器都执行:ssh-keygen -t rsa -b 4096,一路回车到底即可
ssh-keygen -t rsa -b 4096
在每台机器执行以下三个命令
ssh-copy-id hadoop100
ssh-copy-id hadoop102
ssh-copy-id hadoop103
5.授权
为了确保安全,hadoop系统不以root用户启动,我们以普通用户来启动整个Hadoop服务。所以,现在需要对文件权限进行授权。
请确保已经提前创建好了启动Hadoop的普通用户,并配置好了hadoop用户之间的免密登录
以root身份,在三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R liukang:liukang /data
chown -R liukang:liukang /opt/module
6.格式化整个文件系统
# 确保以普通用户执行
su - liukang
# 格式化namenode
hadoop namenode -forma
7.启动
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
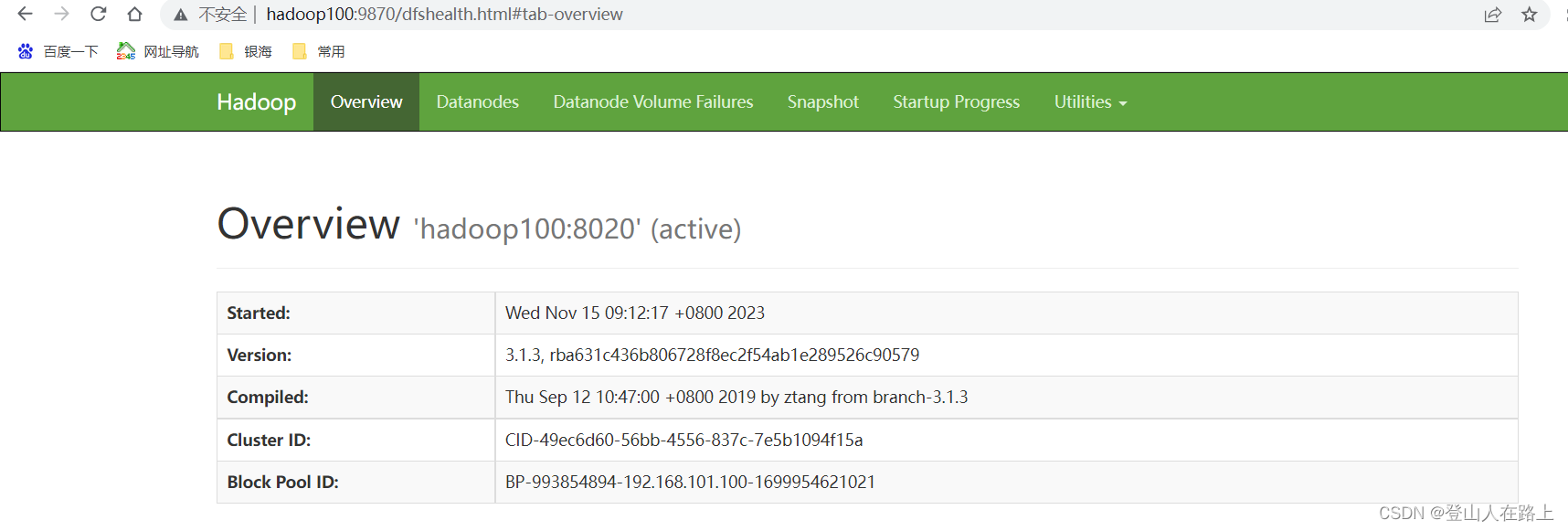
8.查看HDFS WEBUI
启动完成后,可以在浏览器打开:
http://hadoop100公网IP:9870,即可查看到hdfs文件系统的管理网页。















 2949
2949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









