







文章目录
1.总体架构

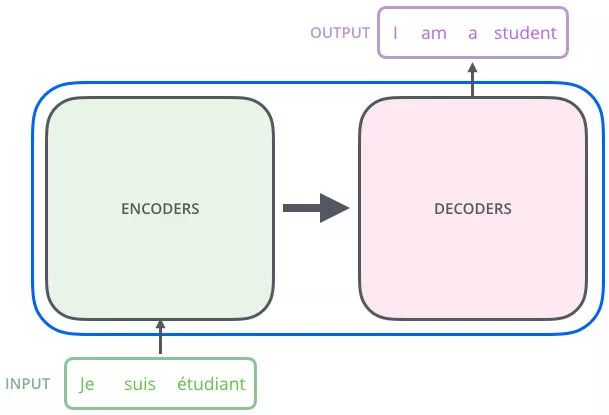
编码器把输入变成一个词向量(Self-Attetion)—对向量集合进行进一步提取
解码器:得到编码器输出的词向量后,生成翻译的结果 – 向量集合对Q进行提取
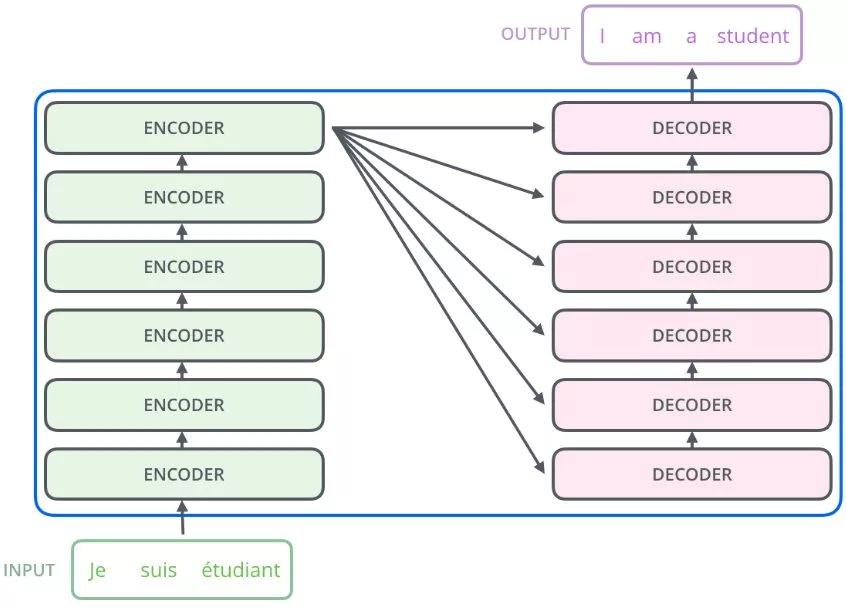
Nx 的意思是,编码器里面又有 N 个小编码器(默认 N=6)
通过 6 个编码器,对词向量一步又一步的强化(增强)
2.编码器-我在做更优秀的词向量
一点感悟:编码器适合将N个特征每一个都获取全局特征进行融合
解码器需要有一个索引Q将编码器得到的N个特征进行融合
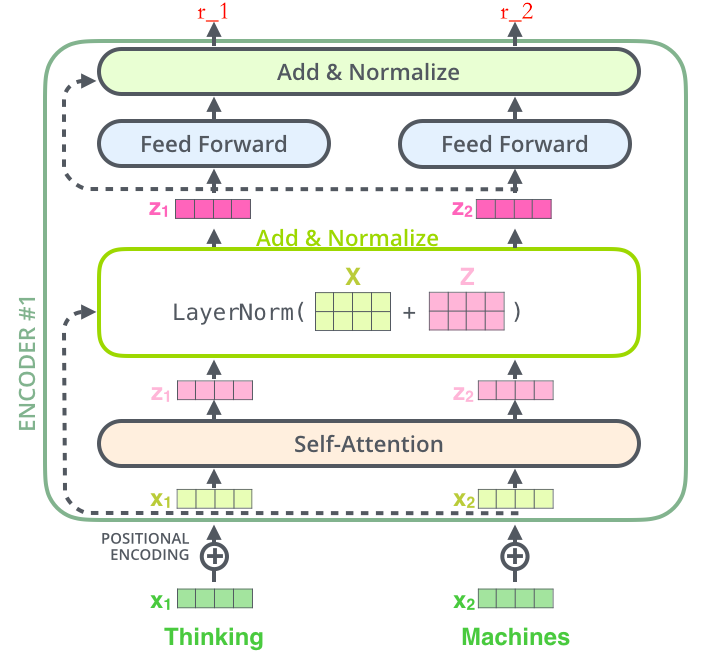
Thinking
–》得到绿色的 x1(词向量,可以通过 one-hot、word2vec 得到)+ 叠加位置编码(给 x1 赋予位置属性)得到黄色的 x1
–》输入到 Self-Attention 子层中,做注意力机制(x1、x2 拼接起来的一句话做),得到 z1(x1 与 x1,x2拼接起来的句子做了自注意力机制的词向量,表征的仍然是 thinking),也就是说 z1 拥有了位置特征、句法特征、语义特征的词向量
–》残差网络(避免梯度消失,w3(w2(w1x+b1)+b2)+b3,如果 w1,w2,w3 特别小,0.0000000000000000……1,x 就没了,【w3(w2(w1x+b1)+b2)+b3+x】),归一化(LayerNorm),做标准化(避免梯度爆炸),得到了深粉色的 z1
–》Feed Forward,Relu(w2(w1x+b1)+b2),(前面每一步都在做线性变换,wx+b,线性变化的叠加永远都是线性变化(线性变化就是空间中平移和扩大缩小),通过 Feed Forward中的 Relu 做一次非线性变换,这样的空间变换可以无限拟合任何一种状态了),得到 r1(是 thinking 的新的表征)
总结下:做词向量,只不过这个词向量更加优秀,让这个词向量能够更加精准的表示这个单词。
3.解码器
解码器会接收编码器生成的词向量,然后通过这个词向量去生成翻译的结果。
编码器将词的特征进行更好的提取
解码器的masked self-attention是对Q进行更好的编码(Q索引的特征进行更好的提取),然后cross-attention是Q对V进行更好的特征提取
解码器的 Self-Attention 在编码已经生成的单词
假如目标词“我是一个学生”---》masked Self-Attention
训练阶段:目标词“我是一个学生”是已知的,然后 Self-Attention 是对“我是一个学生” 做计算
如果不做 masked,每次训练阶段,都会获得全部的信息
如果做 masked,Self-Attention 第一次对“我”做计算
Self-Attention 第二次对“我是”做计算
……
测试阶段:
目标词未知,假设目标词是“我是一个学生”(未知),Self-Attention 第一次对“我”做计算
第二次对“我是”做计算
测试阶段,每生成一点,Self-Attention获得当前的索引信息
3.1 解码器
解码器原始输入通过掩码自注意力编码之后作为Q,与编码器的K,V生成更精确的Q继续放入下一层直到最后一层生成输出。
3.2 生成词
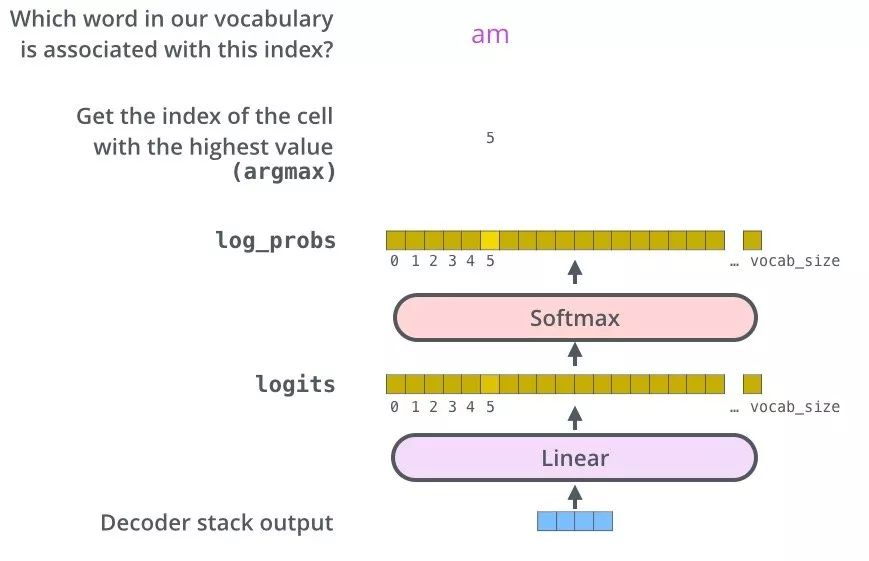
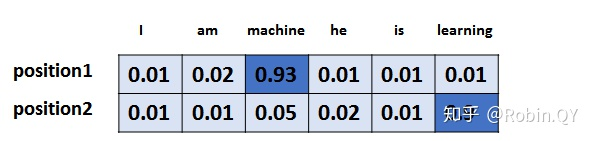
3.3 单词表
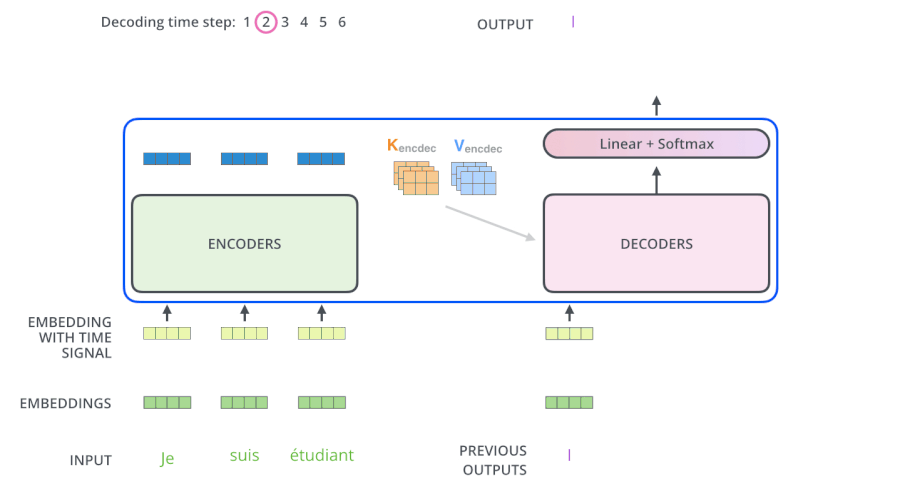
4.动态流程
问题一:为什么 Decoder 需要做 Mask
机器翻译:源语句(我爱中国),目标语句(I love China)
为了解决训练阶段和测试阶段的 gap(不匹配)
训练阶段:解码器会有输入,这个输入是目标语句,就是 I love China,通过已经生成的词,去让解码器更好的生成(每一次都会把所有信息告诉解码器)
测试阶段:解码器也会有输入,但是此时,测试的时候是不知道目标语句是什么的,这个时候,你每生成一个词,就会有多一个词放入目标语句中,每次生成的时候,都是已经生成的词(测试阶段只会把已经生成的词告诉解码器)
为了匹配,为了解决这个 gap,masked Self-Attention 就登场了,我在训练阶段,我就做一个 masked,当你生成第一个词,我啥也不告诉你,当你生成第二个词,我告诉第一个词
问题二:为什么 Encoder 给予 Decoders 的是 K、V 矩阵
通过部分(生成的词)去全部(源语句)的里面挑重点。
若Q 是源语句,K,V 是已经生成的词,源语句去已经生成的词里找重点 ,找信息,已经生成的词里面压根就没有下一个词。















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









