



 Decoder通过交互注意力机制工作,结合Encoder的输出和自身输入生成概率分布。在训练中,使用TeacherForcing策略,用真实标签作为Decoder输入。但在测试时,这种做法可能导致曝光偏误,解决方法是在训练中采用ScheduledSampling,加入一定噪声。
Decoder通过交互注意力机制工作,结合Encoder的输出和自身输入生成概率分布。在训练中,使用TeacherForcing策略,用真实标签作为Decoder输入。但在测试时,这种做法可能导致曝光偏误,解决方法是在训练中采用ScheduledSampling,加入一定噪声。
一、Decoder工作部分(以一个例子介绍工作流程,以及Decoder输出结果是什么样的)
Decoder是如何工作的(这也是Decoder与Encoder之间的连接)?
Decoder的工作主要涉及到交互注意力,所谓交互注意力是指:使用Encode的输出结果a(i)生成k(i)、v(i),然后Decode根据输入生成q(i),如此q、k、v都得到了,从而计算注意力,由于q k v一部分来自encode一部分来自decode,所以叫交互注意力。
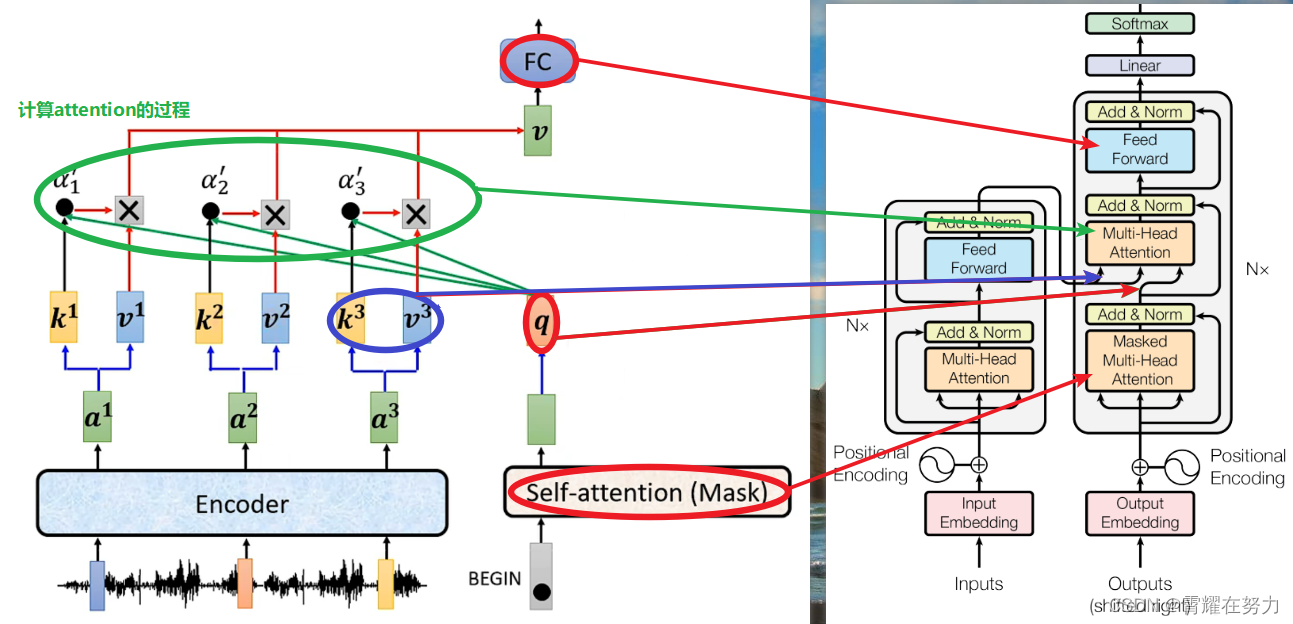
左图为输入一个单词,计算交互注意力的过程,,,右图是transformer的架构,本文章借助左图,简要说明一下右图Decoder部分的各个模块具体是什么,,,当然这只是简要对比,比如FC对应于Feed Forward,他们不是对等关系,可以认为Feed Forward是FC的升级版,Masked的作用就是让self-attention只能看到当前词汇之前的输入,不能看到之后的输入。
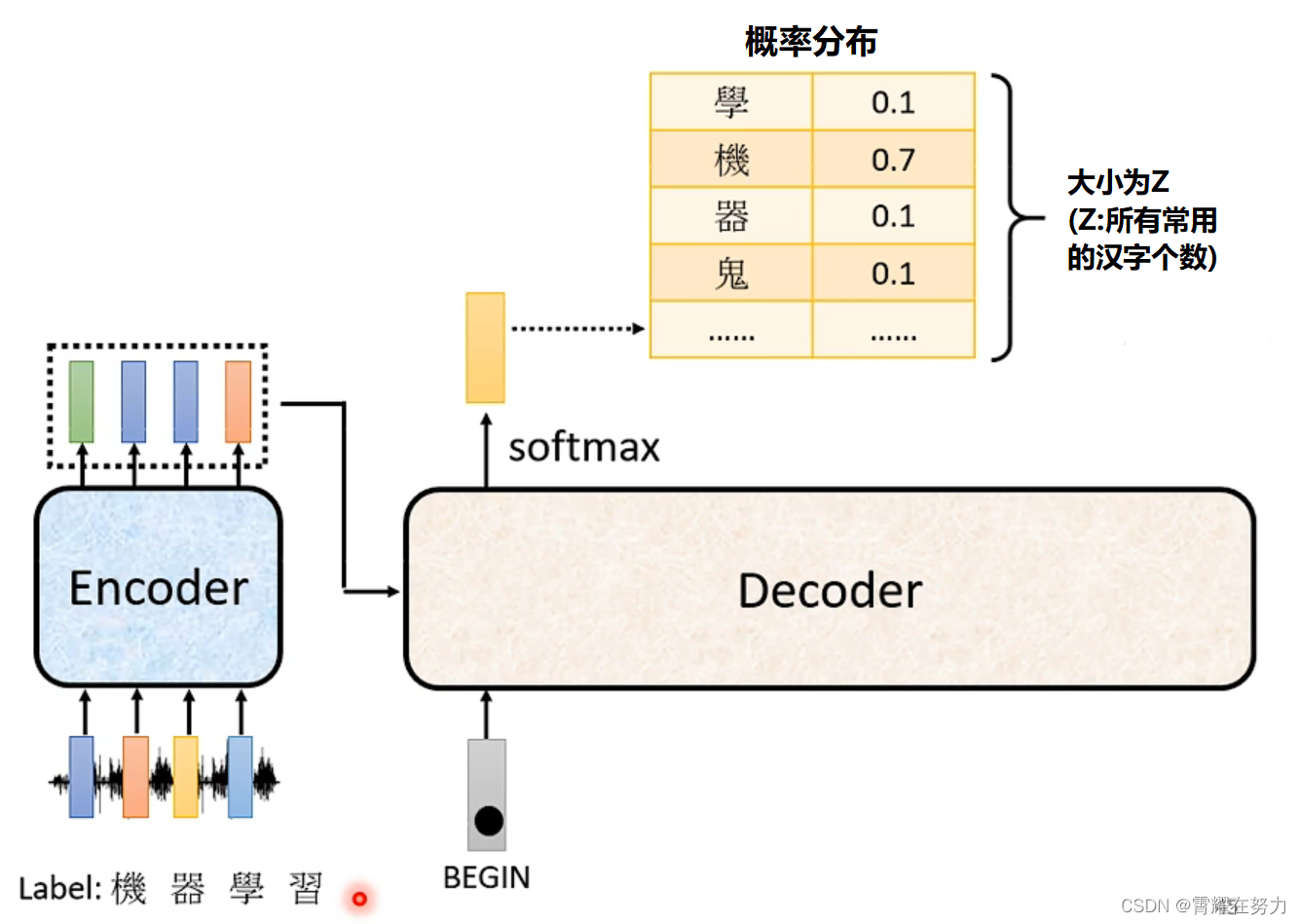
2.Decoder的输出是什么样的呢?
decoder的输出是一个包含全部汉字的概率分布,根据每个汉字对应的概率确定输出那个汉字,如下图所示:“机”对应的概率最高为0.7,我们就认为本次输出的为“机”字。
二、Transformer是如何训练的
1.以单个词为例:考虑语音识别这个例子,
Encoder的输入为“机器学习”这段语音,Decoder先输入一个开始词begin(规定第一个词为begin,代表开始),然后通过结合Encoder的输出计算交互注意力,得到一个输出向量1,之后用1与真实标签对应的one-hot2求loss,进而优化模型的参数:

2.考虑多个词时,以sentence为输入:
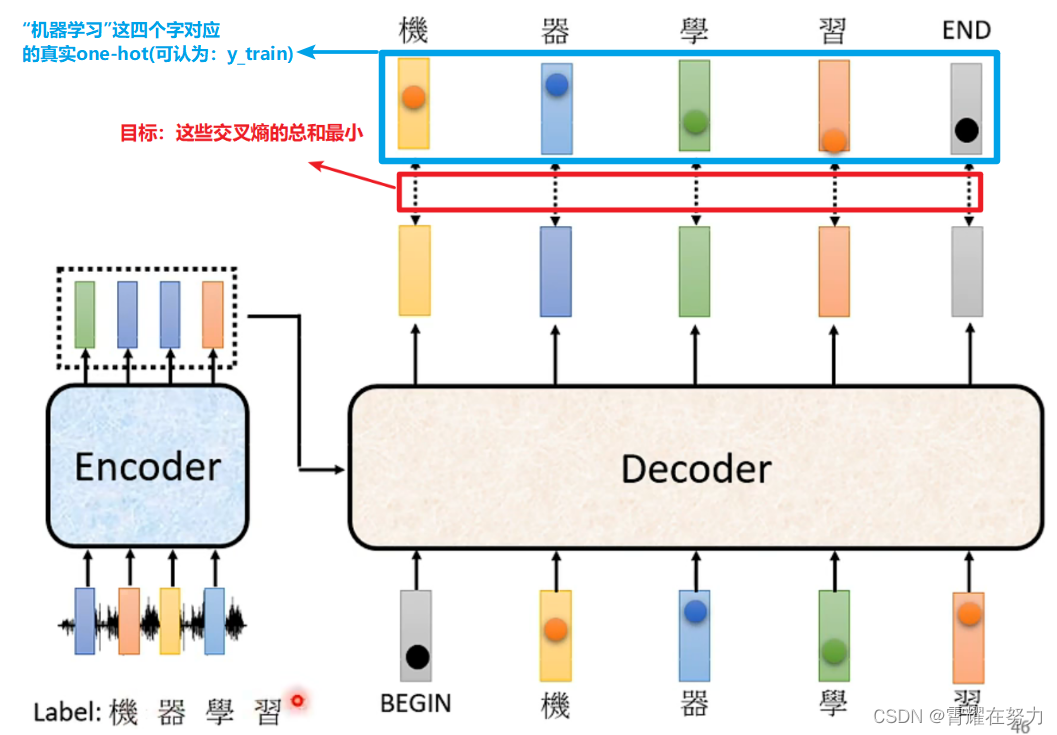
相信细心的同学能发现这一点,这个Decoder的输入怎么是真实标签啊?说的有点绕,看这个例子就知道了:
1.训练数据集:x_train = [......], y_train = [.....]
2.建立模型预测: model()
3.预测:pre_data = model(x_train)
4.计算预测pre_data与真实数据y_train的残差,进行这就是我们经常使用的神经网络模型的训练过程对吧,使用x_train去训练模型,得到预测结果,让预测结果与真实结果求残差,,,但是这个Decoder的训练,有没有x_train与y_train是一样的,这就是Teacher Forcing:useing the ground truth as input(可以理解为教学:我教给你某个答案,希望你也能输出某个答案)
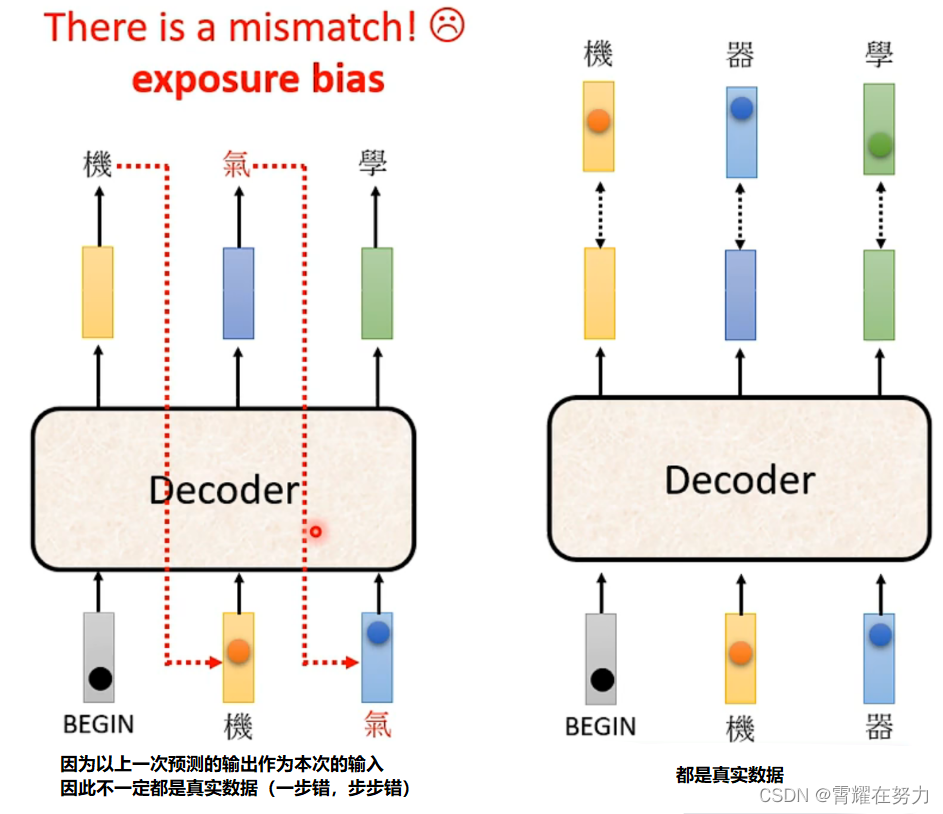
三、模型工作于测试阶段时会形成一定的问题(exposure bias):
1.造成问题的原因:还是以语言生成为例
在测试阶段时:由于Decoder工作的特性(循环预测),将上一次预测的输出,作为本次的输入,如果在预测过程中某一次预测错位,那么接下来的预测都会是错误的(因为输入就是错的),也就是一步错,步步错。
在训练阶段时:正如前面所说,在训练阶段模型的输入为真实标签,都是正确的,这与测试阶段不同。
由于两者的不对等性,使模型的建立存在一定的问题,也就是“exposure bias”(因为训练的时候把答案告诉了模型)。
2.解决方法:
在训练阶段向Decoder输入时,不要全输入正确的标签,也就是输入“机器学习”,可以人为适当的添加一些噪声“机奇学习”,这一招叫“Scheduled Sampling”,,,这样训练出来的模型效果更好。

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









