






一.联合索引的存储结构
比方说联合索引 (col1, col2,col3),我知道在逻辑上是先按照col1进行排序再按照col2进行排序最后再按照col3进行排序。
比如col1相等 那就通过col2排序,如果说col2值相等,那就col3排序
假设这是一个多列索引(col1, col2,col3),对于叶子节点,如图所示:
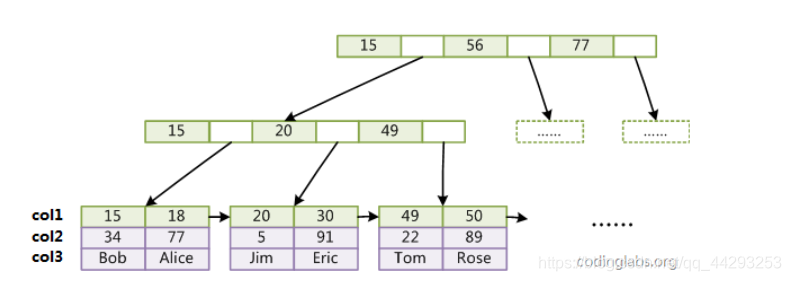
PS:该图改自《MySQL索引背后的数据结构及算法原理》一文的配图。
二、联合索引的查找方式
其实和存存储一样。也是根据顺序查询
列如 :col1, col2,col3 会走索引
col1, col3 ,col2 会走索引(SQL优化器进行优化)最终变成 col1, col2,col3
col1,col3 会走索引 只不过走col1的索引 但是效率比col1, col2,col3 慢
col1,col2 会走索引
col2,col3 不会走索引 因为首先存储通过col1 > col2 <col3 进行排序
这时候就要遵守最左原则 必须有col1列的存在














 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









