






一、引言
波动率分析是风险管理与策略设计的核心,在上一篇文章中讨论了基本的arch部署情况及表现,详见https://blog.csdn.net/qq_44303044/article/details/146017143?spm=1001.2014.3001.5501,然而,期货数据的特殊性(如合约切换、展期收益)常导致模型失效,现在对GARCH 模型 可解释性不强的情况进一步分析。
一、可能原因
- 数据预处理问题:
- 收益率计算错误(如未对数化、未正确差分)。
- 数据存在大量缺失值或异常值未处理。
- 时间序列非平稳(需单位根检验)。
- 模型参数估计失败:
- 参数未收敛(常见于样本量不足或波动率剧烈波动时)。
- 初始值设置不合理(如 ARCH/GARCH 项初始值为负数)。
- 模型误配:
- 期货数据可能存在高频跳跃、非对称效应(利空 / 利好反应不同),而基础 GARCH 模型无法捕捉。
- 未考虑外生变量(如成交量、持仓量)。
二、数据预处理错误
-
展期收益的本质
新旧合约切换时价差跳空会导致波动率计算失真,之前并未考虑合约切换的影响,展期收益是合约切换时近月与远月价差导致的盈亏,计算公式为:
展期收益=远月合约价格−近月合约价格 -
是否计入波动率的场景选择
- 学术研究:使用指数合约,排除展期收益干扰。
- 实盘策略:需计入展期收益,因其影响实际盈亏。
三、检查模型
1.对原模型进行残差检验(Ljung-Box检验应不显著)
# 残差检验(Ljung-Box检验应不显著)
from statsmodels.stats.diagnostic import acorr_ljungbox
print(acorr_ljungbox(results.resid, lags=10))
结果如下:
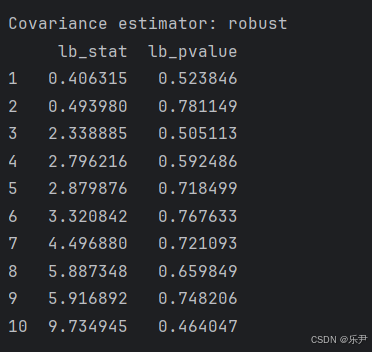
- 原假设:残差序列不存在自相关。
- lb_stat:Ljung - Box 统计量,它衡量了观察到的残差序列与完全随机序列之间的差异程度。该统计量的值越大,越有可能拒绝原假设(即存在自相关)。
- lb_pvalue:与 Ljung - Box 统计量对应的 p 值。如果 p 值大于预先设定的显著性水平(常见的如 0.05),则不能拒绝原假设,意味着残差序列不存在自相关;如果 p 值小于显著性水平,则拒绝原假设,表明残差序列存在自相关。
- 意味着所构建的 GARCH 模型对数据的拟合效果较好,残差中没有明显的自相关结构,模型能够较好地捕捉数据中的波动特征,但R方依然为0,是为什么呢?金融市场数据往往包含大量噪声,这些噪声可能掩盖了模型试图捕捉的真实波动模式。如果数据中的噪声过大,模型难以从中提取有意义的信息,就会导致 R 方表现不佳。例如,交易数据中可能存在大量的微观结构噪声,这些噪声会干扰模型对波动率的估计。
2.EGARCH 模型可以更好地捕捉金融时间序列中的非对称效应,并且加入t分布解决尖峰厚尾的问题
model = garch_model(returns_with_volume.iloc[:,0], p=1, q=1, vol='EGARCH',dist='t')期货波动率分析的核心在于数据质量与模型适配,还可以结合混合模型(如 GARCH+LSTM)提升非线性预测能力,这里不做过多深究。对数差分、平稳性检验是关键,通过以上方法,可显著提升波动率模型的准确性,有兴趣的可以继续研究讨论,在评论区讨论您遇到的波动率模型问题,或分享您的优化经验!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









