







一、Flume

(一)概述
1、Flume最早是Cloudera提供的日志收集系统,后贡献给Apache
2、Flume是一个高可用的,高可靠的、健壮性,分布式的海量日志采集、聚合和传输的系统
3、Flume支持在日志系统中定制各类数据发送方,用于收集数据(source)
4、Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力(sink).
(二)版本
1、Flume0.9X:又称Flume-og,老版本的flume,需要引入zookeeper集群管理,性能也较低(单线程工作)
2、Flume1.X:又称Flume-ng。新版本需要引入zookeeper,和flume-og不兼容
三、Flume的特性
1、可靠性:事务型的数据传递,保证数据的可靠性。一个日志交给fume来处理,不会出现此日志丢失或未被处理的情况
2、可恢复性:通道可以以内存或文件的方式实现,内存更快,但不可恢复。文件较慢但提供了可恢复性
(三)Flume总体架构图

(四)event事件
1、event的相关概念:Flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
2、 在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。简而言之,在Flume中,每一条日志就会封装成一个event对象
3、 一个完整的event包括:event headers、event body、event信息(即文本文件中的单行记录),如下所以:

其中event信息就是flume收集到的日记记录。
(五)Flume运行机制
1、flume运行的核心就是agent,agent本身是一个Java进程
2、agent里面包含3个核心的组件:source—>channel—>sink,类似生产者、仓库、消费者的架构
3、source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义等
4、channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等
5、sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
6、一个完整的工作流程:source不断的接收数据,将数据封装成一个一个的event,然后将event发送给channel,channel作为一个缓冲区会临时存放这些event数据,随后sink会将channel中的event数据发送到指定的地方—-例如HDFS等
7、注:只有在sink将channel中的数据成功发送出去之后,channel才会将临时event数据进行删除,这种机制保证了数据传输的可靠性与安全性
(六)Flume的复杂流动
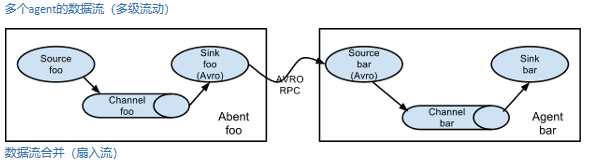
在做日志收集的时候一个常见的场景就是,大量的生产日志的客户端发送数据到少量的附属于存储子系统的消费者agent。例如,从数百个web服务器中收集日志,它们发送数据到十几个负责将数据写入HDFS集群的agent。

这个可在Flume中可以实现,需要配置大量第一层的agent,每一个agent都有一个avro sink,让它们都指向同一个agent的avro source(强调一下,在这样一个场景下你也可以使用thrift source/sink/client)。在第二层agent上的source将收到的event合并到一个channel中,event被一个sink消费到它的最终的目的地。

Flume支持多路输出event流到一个或多个目的地。这是靠定义一个多路数据流实现的,它可以实现复制和选择性路由一个event到一个或者多个channel。

上面的例子展示了agent foo中source扇出数据流到三个不同的channel,这个扇出可以是复制或者多路输出。在复制数据流的情况下,每一个event被发送所有的三个channel;在多路输出的情况下,一个event被发送到一部分可用的channel中,它们是根据event的属性和预先配置的值选择channel的。 这些映射关系应该被填写在agent的配置文件中。
二、Flume的安装
1、上传flume安装包

2、解压并重命名
[root@hadoop01 flume]# tar -zxvf apache-flume-1.6.0-bin.tar.gz
[root@hadoop01 flume]# mv apache-flume-1.6.0-bin flume
三、Source
(一)NetCat Source
(Ⅰ)概述
1、一个NetCat Source用来监听一个指定端口,并接收监听到的数据
2、接收的数据是字符串形式
(Ⅱ)可配置选项说明
| 配置项 | 说明 |
|---|---|
| channels | 绑定通道 |
| type | netcat |
| port | 指定要绑定到的端口号 |
| selector.* | 选择器配置 |
| interceptors.* | 拦截器配置 |
(Ⅲ)示例demo.conf
1、编写
(1)在conf目录下,创建一个配置文件,并进行编写
[root@hadoop01 flume]# cd /home/software/flume/conf/
[root@hadoop01 conf]# vim demo.conf
#定义agent,配置Agent a1 的组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source,描述/配置a1的r1
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=4444
#定义channel,描述a1的c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink,描述a1的k1
a1.sinks.k1.type=logger
#绑定agent,为channel 绑定 source和sink
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
(2)一些点
一个sink只能和一个channel进行绑定
一个source可以与多个channel进行绑定
2、 运行
(1)在当前窗口1进入flume的bin目录执行
[root@hadoop01 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/demo.conf -Dflume.root.logger=INFO,console
(2)新开一个窗口2,通过nc来访问,执行(或者通过外部http请求访问对应的ip和端口,比如:http://192.168.232.129:44444/hello
[root@hadoop01 ~]# nc 0.0.0.0 4444
nihao
OK
ok
OK
(3)在窗口1可以看的如下内容
2021-08-21 08:48:49,217 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 6E 69 68 61 6F nihao }
2021-08-21 08:49:43,229 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 6F 6B ok }
3、启动命令
| 参数 | 描述 |
|---|---|
| agent | 运行一个Flume Agent |
| –conf,-c | 指定配置文件放在什么目录 |
| –conf-file,-f | 指定配置文件,这个配置文件必须在全局选项的–conf参数定义的目录下 |
| –name,-n | Agent的名称,注意:要和配置文件里的名字一致 |
| -Dproperty=value | 设置一个JAVA系统属性值。常见的:-Dflume.root.logger=INFO,console |
(二)Spooling Directory Source
(Ⅰ)概述
1、flume会持续监听指定的目录,把放入这个目录中的文件当做source来处理
2、注意:一旦文件被放到“自动收集”目录中后,便不能修改,如果修改,flume会报错
3、此外,也不能有重名的文件,如果有,flume也会报错。
(Ⅱ)可配置选项说明
| 配置项 | 说明 |
|---|---|
| channels | 绑定通道 |
| type | spooldir |
| spoolDir | 读取文件的路径,即"搜集目录" |
| selector.* | 选择器配置 |
| interceptors.* | 拦截器配置 |
(Ⅲ)示例Spooling.conf
1、编写
(1)命令及代码
[root@hadoop01 bin]# Source stop
[root@hadoop01 bin]# cd /home/software/flume/conf/
[root@hadoop01 conf]# vim spooling.conf
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/home/spoolingDir
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、运行
(1)在窗口1启动
[root@hadoop01 conf]# cd /home
[root@hadoop01 home]# mkdir spoolingDir
[root@hadoop01 home]# cd /home/software/flume/bin/
[root@hadoop01 bin]# sh flume -ng agent -n a1 -c ../conf/ -f ../conf/spooling.conf -Dflume.root.logger=INFO,console
(2)在窗口2进行如下命令
[root@hadoop01 ~]# cd /home/
[root@hadoop01 home]# ll
总用量 20
-rw-r--r--. 1 root root 8 8月 19 10:05 bok
-rw-r--r--. 1 root root 3400 8月 20 10:07 CharactersCount.jar
drwxr-xr-x. 6 root root 4096 8月 21 08:29 software
drwxr-xr-x. 3 root root 4096 8月 21 09:19 spoolingDir
-rw-r--r--. 1 root root 3397 8月 20 09:38 WordCount.jar
[root@hadoop01 home]# cp bok spoolingDir/
[root@hadoop01 home]# touch demo
[root@hadoop01 home]# vim demo
[root@hadoop01 home]# cp demo spoolingDir/
[root@hadoop01 home]#
(3)在窗口1可以看到如下结果
2021-08-21 09:20:31,189 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 73 68 75 69 68 75 60 shuihu` }
2021-08-21 09:22:08,789 (pool-3-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:258)] Last read took us just up to a file boundary. Rolling to the next file, if there is one.
2021-08-21 09:22:08,789 (pool-3-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:348)] Preparing to move file /home/spoolingDir/demo to /home/spoolingDir/demo.COMPLETED
2021-08-21 09:22:13,209 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 67 68 6B 61 6B 62 61 6A ghkakbaj }
(三)Exec Source
(Ⅰ)概述
1. 可以将命令产生的输出作为源来进行传递
(Ⅱ)可配置选项说明
| 配置项 | 说明 |
|---|---|
| channels | 绑定的通道 |
| type | exec |
| command | 要执行的命令 |
| selector.* | 选择器配置 |
| interceptors.* | 拦截器列表配置 |
(Ⅲ)示例:exec.conf
1、编写
(1)修改配置文件,source的type属性为exec)
[root@hadoop01 ~]# cd /home/software/flume/conf/
[root@hadoop01 conf]# vim exec.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=exec
a1.sources.r1.command=ping 192.168.232.129
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、运行
在窗口1进入到bin目录执行指令
sh flume-ng agent -n a1 -c ../conf/ -f ../conf/exec.conf -Dflume.root.logger=INFO,console
(四)HTTP Source
(Ⅰ)概述
1、此Source接受HTTP的GET和POST请求作为Flume的事件
2、GET方式只用于试验,所以实际使用过程中以POST请求居多
3、如果想让flume正确解析Http协议信息,比如解析出请求头、请求体等信息,需要提供一个可插拔的"处理器"来将请求转换为事件对象,这个处理器必须实现HTTPSourceHandler接口。
4、这个处理器接受一个 HttpServletRequest对象,并返回一个Flume Envent对象集合。
(Ⅱ)常用Handler
JSONHandler
1、可以处理JSON格式的数据,并支持UTF-8 UTF-16 UTF-32字符集
2、 该handler接受Event数组,并根据请求头中指定的编码将其转换为Flume Event
3、如果没有指定编码,默认编码为UTF-8
4、格式:
[
{
"headers" : {
"timestamp" : "434324343",
"host" : "random_host.example.com"
}
"body" : "random_body"
},
{
"headers" : {
"namenode" : "namenode.example.com",
"datanode" : "random_datanode.example.com"
},
"body" : "really_random_body"
}
]
BlobHandler
1、BlobHandler是一种将请求中上传文件信息转化为event的处理器
2、BlobHandler适合大文件的传输
(Ⅲ)可配置选项说明
| 配置项 | 说明 |
|---|---|
| channels | 绑定的通道 |
| type | http |
| selector.* | 选择器配置 |
| interceptors.* | 拦截器配置 |
| port | 端口 |
(Ⅳ)示例http.conf
1.编写
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=http
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、运行
(1)在窗口1上执行启动命令
[root@hadoop01 conf]# cd /home/software/flume/bin/
[root@hadoop01 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/http.conf -Dflume.root.logger=INFO,console
(2)在窗口2上执行curl 命令,模拟一次http的Post请求
[root@hadoop01 home]# curl -X POST -d '[{"headers":{"name":"zhangsan","age":"19"},"body":"nihao http flume"}]' http://0.0.0.0:44444
(3)在窗口1中执行结果如下
2021-08-21 09:37:10,692 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{name=zhangsan, age=19} body: 6E 69 68 61 6F 20 68 74 74 70 20 66 6C 75 6D 65 nihao http flume }
(五)Avro Source
(Ⅰ)概述
1、监听Avro 端口来接收外部avro客户端的事件流
2、avro-source接收到的是经过avro序列化后的数据,然后反序列化数据继续传输。
3、源数据必须是经过avro序列化后的数据
4、利用Avro source可以实现多级流动、扇出流、扇入流等效果
5、可以接收通过flume提供的avro客户端发送的日志信息
(Ⅱ)可配选项说明
| 配置项 | 说明 |
|---|---|
| channels | 绑定通道 |
| type | avro |
| bind | 需要监听的主机名或IP |
| port | 要监听的端口 |
| threads | 工作线程最大线程数 |
| selector.* | 选择器配置 |
| interceptors.* | 拦截器配置 |
(Ⅲ)示例avro.conf
1 、编写
(1) 修改配置文件,source的type属性为avro
[root@hadoop01 conf]# cd /home/software/flume/conf/
[root@hadoop01 conf]# vim avro.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、运行
(1)在窗口1执行启动指令
[root@hadoop01 ~]# cd /home/software/flume/bin/
[root@hadoop01 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/avro.conf -Dflume.root.logger=INFO,console
(2)在窗口2执行agent-avro客户端指令
[root@hadoop01 bin]# vim /home/demo
ghkakba
aaa
j
[root@hadoop01 bin]# sh flume-ng avro-client -H 0.0.0.0 -p 44444 -F /home/demo -c ../conf/
(3)在窗口3执行结果如下
2021-08-21 15:43:38,598 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 67 68 6B 61 6B 62 61 ghkakba }
2021-08-21 15:43:38,598 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 61 61 61 aaa }
2021-08-21 15:43:38,598 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 6A j }
四、Channel
(一)Memory Channel
(Ⅰ)概述
1. 事件将被存储在内存中(指定大小的队列里)
2. 非常适合那些需要高吞吐量且允许数据丢失的场景下
(Ⅱ)可配置选项说明
| 配置项 | 说明 |
|---|---|
| type | memory |
| capacity | 100 事件存储在信道中的最大数量; 建议实际工作调节:10万; 首先估算出每个event的大小,然后再服务的内存来调节 |
| transactionCapacity | 100 每个事务中的最大事件数; 建议实际工作调节:1000~3000 |
(二)File Channel
(Ⅰ)概述
1、将数据临时存储到计算机的磁盘的文件中
2、性能比较低,但是即使程序出错数据不会丢失
(Ⅱ)可配置选项说明
| 配置项 | 说明 |
|---|---|
| type | file |
| dataDirs | 指定存放的目录,逗号分隔的目录列表,用以存放日志文件。使用单独的磁盘上的多个目录可以提高文件通道效率。 |
(Ⅲ)示例:filechannel.conf
1、代码
[root@hadoop01 bin]# cd /home/software/flume/conf/
[root@hadoop01 conf]# vim filechannel.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=4444
#定义channel
a1.channels.c1.type=file
a1.channels.c1.dataDirs=/home/filechannel
#定义sink
a1.sinks.k1.type=logger
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、运行
(1)在窗口1执行启动指令
[root@hadoop01 home]# cd /home/software/flume/bin/
[root@hadoop01 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/filechannel.conf -Dflume.root.logger=INFO,console
(2)窗口2
[root@hadoop01 conf]# nc 0.0.0.0 4444
nihao ch
OK
hello xiaom
OK
hello may
OK
(3)窗口1
2021-08-21 16:04:28,889 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 6E 69 68 61 6F 20 63 68 nihao ch }
2021-08-21 16:04:28,890 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 20 78 69 61 6F 6D 20 hello xiaom }
2021-08-21 16:04:34,894 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 20 6D 61 79 hello may }
(4)文件
[root@hadoop01 conf]# cd /home/filechannel/
[root@hadoop01 filechannel]# ll
总用量 1028
-rw-r--r--. 1 root root 1048576 8月 21 16:04 log-1
-rw-r--r--. 1 root root 47 8月 21 16:05 log-1.meta
[root@hadoop01 filechannel]# vim log-1
^?^@^@^@/^W^M^A^@^@^@^Q¹8¼g{^A^@^@^Y 8¼g{^A^@^@^U
^R^Hnihao ch^Q§Ç)¨^@^@^@^@^@^?^@^@^@^_^W^M^D^@^@^@^Q¹8¼g{^A^@^@^Y!8¼g{^A^@^^A^@^@^@^@^?^@^@^@3^W^M^A^@^@^@^Qº8¼g{^A^@^@^Y"8¼g{^A^@^@^Y
^N^R^Lhello xiaom ^QïH<8d><9b>^@^@^@^@^@^?^@^@^@^_^W^M^D^@^@^@^Qº8¼g{^A^@^@^Y#g{^A^@^@^E^M^A^@^@^@^@^?^@^@^@$^W^M^B^@^@^@^Q»8¼g{^A^@^@^Y$8¼g{^A^@^@
^M^A^@^@^@^U^@^@^@^@^@^?^@^@^@^_^W^M^D^@^@^@^Q»8¼g{^A^@^@^Y%8¼g{^A^@^@^E^M^B^@^@^@^?^@^@^@$^W^M^B^@^@^@^Q¼8¼g{^A^@^@^Y&8¼g{^A^@^@
^M^A^@^@^@^UX^@^@^@^@^?^@^@^@^_^W^M^D^@^@^@^Q¼8¼g{^A^@^@^Y'8¼g{^A^@^@^E^M^B^@@^@^?^@^@^@0^W^M^A^@^@^@^QÀ8¼g{^A^@^@^Y(8¼g{^A^@^@^V
^K^R hello may^QÒôù^D^@^@^@^@^@^?^@^@^@^_^W^M^D^@^@^@^QÀ8¼g{^A^@^@^Y)8¼g{^^@^E^M^A^@^@^@^@^?^@^@^@$^W^M^B^@^@^@^QÁ8¼g{^A^@^@^Y*8¼g{^A^@^@
(三)其他Channel
(Ⅰ)JDBC Channel
1、 事件会被持久化(存储)到可靠的数据库里
2、目前只支持嵌入式Derby数据库。但是Derby数据库不太好用,所以JDBC Channel目前仅用于测试,不能用于生产环境。
(Ⅱ)内存溢出通道
1、优先把Event存到内存中,如果存不下,在溢出到文件中
2、目前处于测试阶段,还未能用于生产环境
五、Sink
(一)File_roll Sink
(Ⅰ)概述
1、在本地系统中存储事件
2、每隔指定时长生成文件保存这段时间内收集到的日志信息
(Ⅱ)配置选项说明
| 配置项 | 说明 |
|---|---|
| channel | 绑定通道 |
| type | file_roll |
| sink.directory | 文件被存储的目录 |
| sink.rollInterval | 30 记录日志到文件里,每隔30秒生成一个新日志文件。如果设置为0,则禁止滚动,从而导致所有数据被写入到一个文件中。 |
(Ⅲ)示例:Fileroll.conf
1、编写
[root@hadoop01 filechannel]# cd /home/software/flume/conf/
[root@hadoop01 conf]# vim fileroll.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=file_roll
a1.sinks.k1.sink.directory=/home/fileroll
a1.sinks.k1.sink.rollInterval=30
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、运行
(1)窗口1
[root@hadoop01 conf]# cd /home/software/flume/bin/
[root@hadoop01 bin]# mkdir /home/fileroll
[root@hadoop01 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/fileroll.conf -Dflume.root.logger=INFO,console
(2)窗口2
[root@hadoop01 ~]# nc 0.0.0.0 44444
a;hf
OK
kljao
OK
niaho
OK
......
(3)文件:每隔30s会生成一个新文件
[root@hadoop01 home]# cd /home/fileroll/
[root@hadoop01 fileroll]# ll
总用量 12
-rw-r--r--. 1 root root 0 8月 21 16:13 1629533604773-1
-rw-r--r--. 1 root root 46 8月 21 16:14 1629533604773-2
-rw-r--r--. 1 root root 49 8月 21 16:14 1629533604773-3
-rw-r--r--. 1 root root 14 8月 21 16:15 1629533604773-4
[root@hadoop01 fileroll]# cat 1629533604773-1
[root@hadoop01 fileroll]# cat 1629533604773-3
af
af
af
gr
...
(二)HDFS Sink
(Ⅰ)概述
1、此Sink将事件写入到Hadoop分布式文件系统HDFS中
2、目前它支持创建文本文件和序列化文件,并且对这两种格式都支持压缩
3、这些文件可以分卷,按照指定的时间或数据量或事件的数量为基础
4、它还通过类似时间戳或机器属性对数据进行 buckets/partitions 操作
5、HDFS的目录路径可以包含将要由HDFS替换格式的转移序列用以生成存储事件的目录/文件名
6、 使用这个Sink要求haddop必须已经安装好,以便Flume可以通过hadoop提供的jar包与HDFS进行通信
(Ⅱ)可配置选项说明
| 配置项 | 说明 |
|---|---|
| channel | 绑定的通道 |
| type | hdfs |
| hdfs.path | HDFS 目录路径 (hdfs://namenode/flume/webdata/) |
| hdfs.inUseSuffix | .tmp Flume正在处理的文件所加的后缀 |
| hdfs.rollInterval | 文件生成的间隔事件,默认是30,单位是秒 |
| hdfs.rollSize | 生成的文件大小,默认是1024个字节 ,0表示不开启此项 |
| hdfs.rollCount | 每写几条数据就生成一个新文件,默认数量为10 ; 每写几条数据就生成一个新文件 |
| hdfs.fileType | SequenceFile/DataStream/CompressedStream |
| hdfs.retryInterval | 80 Time in seconds between consecutive attempts to close a file. Each close call costs multiple RPC round-trips to the Namenode, so setting this too low can cause a lot of load on the name node. If set to 0 or less, the sink will not attempt to close the file if the first attempt fails, and may leave the file open or with a ”.tmp” extension. |
(Ⅲ)示例:hdfs.conf
1、编写
[root@hadoop01 bin]# cd /home/software/flume/conf/
[root@hadoop01 conf]# cp demo.conf hdfs.conf
[root@hadoop01 conf]# vim hdfs.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://hadoop01:9000/flume
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.rollCount=20
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、运行
(1)窗口1
[root@hadoop01 bin]# cd /home/software/flume/bin/
[root@hadoop01 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/hdfs.conf -Dflume.root.logger=INFO,console
(2)窗口2
[root@hadoop01 ~]# nc 0.0.0.0 44444
nihao
OK
hal;f
OK
......
(3)hfs上的文件结果如下;
hdfs.rollCount:每写几条数据就生成一个新文件,默认数量为10 ; 每写几条数据就生成一个新文件

(三)Avro sink
(Ⅰ)概述
1、将源数据进行利用avro进行序列化之后写到指定的节点上
2、是实现多级流动、扇出流(1到多) 扇入流(多到1) 的基础。
(Ⅱ)配置选项说明
| 配置项 | 说明 |
|---|---|
| channel | 绑定的通道 |
| type | avro |
| hostname | 要发送的主机 |
| port | 要发往的端口号 |
(Ⅲ)跨服务器多级流动:
概述
1、让01机的flume通过netcat source源接收数据,然后通过avro sink 发给02机
2、02机的flume利用avro source源收数据,然后通过avro sink 传给03机
3、03机通过avro source源收数据,通过logger sink 输出到控制台上
最终实现第一台给第三台发送数据
实现步骤
1、准备三个节点,并安装好flume(关闭每台机器的防火墙)
2、配置每台flume的配置文件
3、启动测试
示例
1、配置其余两台服务器的环境
拷贝
[root@hadoop01 ~]# scp -r flume 192.168.232.130:/home/software
[root@hadoop01 ~]# scp -r flume 192.168.232.131:/home/software
2、编写
(1)hadoop01
[root@hadoop01 conf]# cp demo.conf duoji.conf
[root@hadoop01 conf]# vim duoji.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop02
a1.sinks.k1.port=55555
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
(2)hadoop02
[root@hadoop02 ~]# cd /home/software/flume/conf/
[root@hadoop02 conf]# cp demo.conf duoji.conf
[root@hadoop02 conf]# vim duoji.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=55555
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=hadoop03
a1.sinks.k1.port=55555
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
(3)hadoop03
[root@hadoop03 conf]# cp demo.conf duoji.conf
[root@hadoop03 conf]# vim duoji.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=55555
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
3、运行
(1)分别启动hadoop03、hadoop02、hadoop01上的duoji.conf
[root@hadoop03 conf]# cd /home/software/flume/bin/
[root@hadoop03 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/duoji.conf -Dflume.root.logger=INFO,console
(2)出现
2021-08-21 17:30:57,070 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x922951aa, /192.168.232.130:58236 => /192.168.232.131:55555] BOUND: /192.168.232.131:55555
2021-08-21 17:30:57,070 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x922951aa, /192.168.232.130:58236 => /192.168.232.131:55555] CONNECTED: /192.168.232.130:58236
(3)发送
[root@hadoop01 ~]# nc 0.0.0.0 44444
b^Hniaho
OK
在hadoop03出现(会较慢)
2021-08-21 17:35:06,204 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 62 08 6E 69 61 68 6F b.niaho }
(Ⅳ)扇入
第一二台给第三台发送数据
1、编写
(1)hadoop01
[root@hadoop01 conf]# cp demo.conf shanru.conf
[root@hadoop01 conf]# vim shanru.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.232.131
a1.sinks.k1.port=55555
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
(2)hadoop02(直接由hadoop01中拷贝
[root@hadoop01 conf]# scp shanru.conf hadoop02:/home/software/flume/conf/
shanru.conf 100% 412 0.4KB/s 00:00
[root@hadoop01 conf]#
(3)hadoop03
[root@hadoop03 ~]# cd /home/software/flume/conf/
[root@hadoop03 conf]# cp demo.conf shanru.conf
[root@hadoop03 conf]# vim shanru.conf
#定义agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义source
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=55555
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定agent
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
3、运行
(1)分别启动hadoop03、hadoop02、hadoop01上的shanru.conf
[root@hadoop03 conf]# cd /home/software/flume/bin/
[root@hadoop03 bin]# sh flume-ng agent -n a1 -c ../conf/ -f ../conf/shanru.conf -Dflume.root.logger=INFO,console
(2)在hadoop03出现
2021-08-21 17:48:11,014 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xdf83cdf2, /192.168.232.130:58237 => /192.168.232.131:55555] CONNECTED: /192.168.232.130:58237
2021-08-21 17:48:36,205 (New I/O server boss #1 ([id: 0x9268d819, /0:0:0:0:0:0:0:0:55555])) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xf6702ffe, /192.168.232.129:51624 => /192.168.232.131:55555] OPEN
2021-08-21 17:48:36,206 (New I/O worker #2) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xf6702ffe, /192.168.232.129:51624 => /192.168.232.131:55555] BOUND: /192.168.232.131:55555
2021-08-21 17:48:36,206 (New I/O worker #2) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xf6702ffe, /192.168.232.129:51624 => /192.168.232.131:55555] CONNECTED: /192.168.232.129:51624
(3)发送
[root@hadoop01 ~]# nc 0.0.0.0 44444
hello 2222
OK
[root@hadoop02 software]# nc 0.0.0.0 44444
helo^Hlo 1111
OK
在hadoop03出现(会较慢)
2021-08-21 17:53:32,022 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 20 32 32 32 32 hello 2222 }
2021-08-21 17:53:32,259 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6F 08 6C 6F 20 31 31 31 31 helo.lo 1111 }
(Ⅴ)扇出流
1、01机的配置文件
#配置Agent a1 的组件
a1.sources=r1
a1.sinks=s1 s2
a1.channels=c1 c2
#描述/配置a1的source1
a1.sources.r1.type=netcat
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=8888
#描述sink
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=192.168.234.212
a1.sinks.s1.port=9999
a1.sinks.s2.type=avro
a1.sinks.s2.hostname=192.168.234.213
a1.sinks.s2.port=9999
#描述内存channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
#为channel 绑定 source和sink
a1.sources.r1.channels=c1 c2
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
2、 02,03配置示例:
#配置Agent a1 的组件
a1.sources=r1
a1.sinks=s1
a1.channels=c1
#描述/配置a1的source1
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=9999
#描述sink
a1.sinks.s1.type=logger
#描述内存channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#为channel 绑定 source和sink
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
六、一些点

数据仓库
ods:数据原始层
DW:数据清洗,根据业务数据计算
DM/res/app:数据集市















 2549
2549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









