







第十五(十四)天:网站流量统计项目
一、概述
(一)业务背景
网站流量统计是改进网站服务的重要手段之一,通过获取用户在网站的行为数据,进行分析,得到有价值的信息。可以基于这些数据对网站进行改进。
按照在线情况分析:
来访时间、访客地域、来路页面、当前停留页面等,这些功能对企业实时掌握自身网站流量有很大的帮助。
按照时段分析:
按照任意的时间段 和任意的时间粒度来进行分析,比如小时段分布,日访问量分布,对于企业了解用户浏览网页的的时间段有一个很好的分析。
按来源分析
来源分析提供来路域名带来的来访次数、IP、独立访客、新访客、新访客浏览次数、站内总浏览次数等数据。这个数据可以直接让企业了解推广成效的来路,从而分析出那些网站投放的广告效果更明显。
(二)业务需求
a. PV
PV(page view),访问量 也叫 点击量,即一天之内整个网站中的页面被访问的次数。对同一个页面的重复访问记为不同的PV。
b. UV
UV(unique visitor),独立访客数,即一天之内访问网站的人数。同一个人在一天之内访问网站多次,也只能计算一个UV。
c. VV
VV (Visit View),会话总数,即一天之内会话的总的数量。所谓的一次会话,指的是为了实现某些功能,浏览器开发网站网站,从访问第一个页面开始,会话开始,直到访问最后一个页面结束,关闭所有页面,会话结束。会话可以认为在访问第一个页面时开始,访问所有页面完成并关闭,或,超过指定时长没有后续访问 都认为会话结束。
d. BR
BR(Bounce Rate)跳出率,一天之内跳出的会话总数占所有会话总数的比率。所谓跳出只的是一个会话中只访问过一个页面会话就结束了,这就称之为该会话跳出了。跳出的会话占全部会话的比率,称之为跳出率。这个指标在评价行推广活动的效果时非常的有用。
e. NewIP
NewIp,新增ip总数,一天之内访问网站的所有IP去重后,检查有多少是在历史数据中从未出现过的,这些IP计数,就是新增的IP总数,这个指标可以一定程度上体现网站新用户增长的情况。
f. NewCust
NewCust,新增独立访客数,一天之内访问网站的人中,有多少人是在历史记录中从来没有出现过的。这个指标可以从另一个角度体现网站用户增长的情况。
g. AvgTime
AvgTime,平均访问时长,所谓一个会话的访问时长,是指,一个会话结束的时间减取一个会话开始时间得到的会话经历的时长。将一天之内所有会话的访问时长求平均值 就是 平均访问时长。这个指标可以体现出网站对用户的粘性大小。
h. AvgDeep
AvgDeep,平均访问深度,所谓一个会话的访问深度,是指,一个会话中访问的所有资源地址去重后计数得到的指标。将一天之内所有会话的访问深度求平均值 就是 平均访问深度。这个指标可以体现出网站对用户的粘性大小。
(三)技术架构
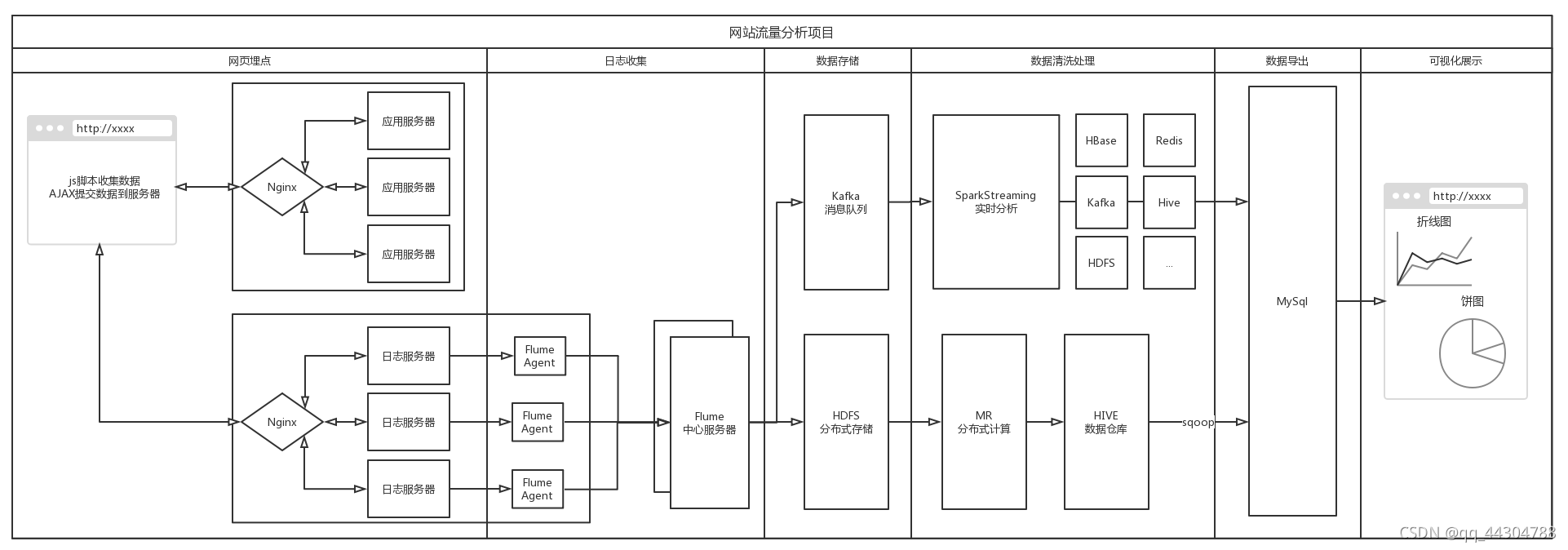
二、实时流处理
(一)SparkStreaming 与 kafka整合实现步骤
1、启动虚拟机(2台或者3台)
2、启动zookeeper集群 sh /home/software/zookeeper-3.4.7/bin/zkServer.sh start
3、启动伪分布式hadoop
完全分布式
在三台节点启动JournalNode:hadoop-daemon.sh start journalnode
在第一、二台节点上启动NameNode:hadoop-daemon.sh start namenode
在三台节点上启动DataNode:hadoop-daemon.sh start datanode
在第一台节点和第二节点上启动zkfc(FailoverController):hadoop-daemon.sh start zkfc
在第三个节点上启动Yarn:start-yarn.sh
在第一个节点上启动ResourceManager:yarn-daemon.sh start resourcemanager
4、启动kafka集群
sh /home/software/kafka/bin/kafka-server-start.sh /home/software/kafka/config/server.properties
5、创建kafka指定的主题
[root@hadoop01 ~]# cd /home/software/kafka/bin/
[root@hadoop01 bin]#
6、编写并启动flume
flume weblog.conf编写
[root@hadoop01 conf]# vim weblog.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop01:9000/weblog/reportTime=%Y-%m-%d
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 30
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.brokerList=hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sinks.k2.topic=logdata
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
[root@hadoop01 conf]# cd /home/software/flume/bin/
[root@hadoop01 bin]# sh flume-ng agent --conf ../conf --conf-file ../conf/weblog.conf --name a1 -Dflume.root.logger=INFO,console
7、启动tomcat(埋点服务器和日志服务器)
8、编写SparkStreaming与Kafka的整合代码,从kafka消费数据
①启动scala-eclipse
②创建scalaProject
③导入spark依赖jar包
添加如下两个目录下的内容为依赖包
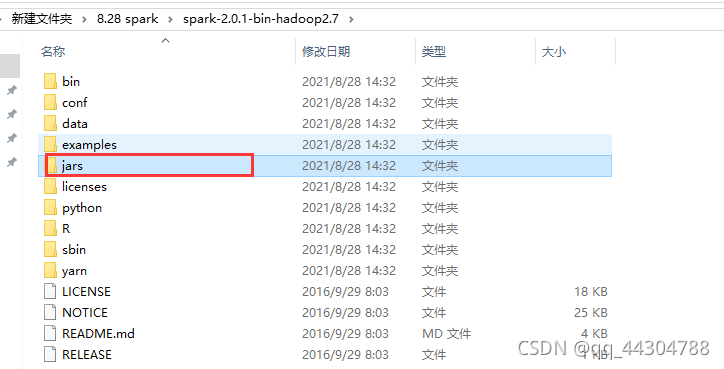
④导入kafka依赖jar包
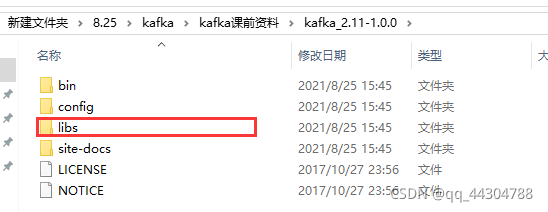
⑤导入spark与kafka整合包
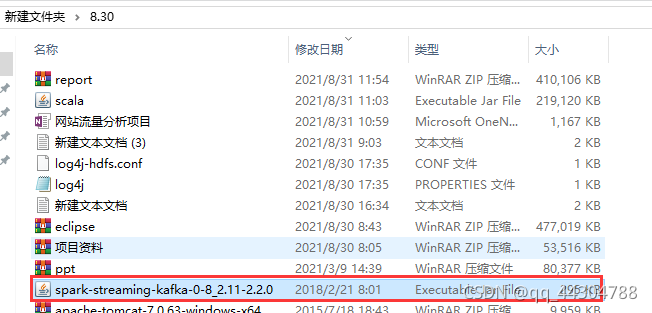
⑥创建scala Object类Driver
package cn.edu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.KafkaUtils
object Driver {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[3]").setAppName("kafkasource")
val sc = new SparkContext(conf)
//SparkStreaming做实时流处理,将连续不断的实时流数据离散化成一批一批的数据进行处理。
//下面的Seconds(5)表示每5秒进行一次处理
val ssc = new StreamingContext(sc,Seconds(5))
//指定zookeeper集群地址,有几台写几个。注意:如果写主机名,前提是windows的hosts文件中需要进行配置
//配置主机名:C://windows/System32/driver/etc下的hosts文件
val zkHosts = "hadoop01:2181,hadoop02:2181,hadoop03:2181"
//指定消费组名(组内竞争消费,组间共享消费)
val group="gp2021"
//指定消费的主题信息。通过Map封装。key是消费的主题名。value是消费的线程数。至少是1个,也可以是多个
val topics = Map("logdata"→1)
//通过SparkStreaming和Kafka整合包提供的工具类,从kafka指定主题消费数据
val kafkaSource=KafkaUtils.createStream(ssc, zkHosts, group, topics)
kafkaSource.print()
ssc.start()
//保持Sparkstreaming一致开启。直到用户主动退出为止。
ssc.awaitTermination()
}
}
9、启动SparkStreaming,访问埋点服务器,测试sparkStreaming是否能够从kafka接收到数据
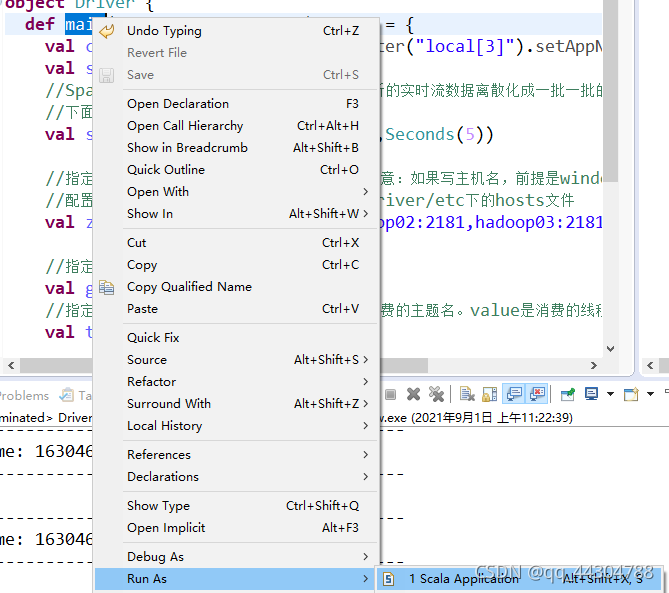
访问localhost:8080/FluxAppServer/a.jsp出现
(二)Spark与Hbase整合 实现步骤:
(Ⅰ)写数据
1、导入Hbase依赖包
2、编写spark与Hbase整合代码
package cn.edu.hbase
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.fs.shell.find.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.client.Put
object WriteDriver {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("writer")
val sc = new SparkContext(conf)
//指定zookeeper集群地址
sc.hadoopConfiguration.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")
//指定zookeeper通信端口
sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort","2181")
//import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
//指定写出的Hbase表名
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, "tbh")
//创建job
val job = new Job(sc.hadoopConfiguration)
//指定输出Key类型
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
//import org.apache.hadoop.fs.shell.find.Result
//指定输出的value类型
job.setOutputValueClass(classOf[Result])
//指定输出的表类型
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val rdd = sc.parallelize(List("1 tom 23","2 rose 18","3 jim 25","4 jsry 20"))
//为了能够将RDD数据写出到HBase表中,需要完成转换RDD[String]→RDD[(输出key,输出value)]
val hbaseRDD = rdd.map { line =>
val arr = line.split(" ")
val id = arr(0)
val name = arr(1)
val age = arr(2)
//import org.apache.hadoop.hbase.client.Put
//创建HBase的行对象并指定行键
val row = new Put(id.getBytes)
//①参:列族名 ② ③ row.add("cf1".getBytes,"name".getBytes,name.getBytes)
row.add("cf1".getBytes,"name".getBytes,name.getBytes)
row.add("cf1".getBytes,"age".getBytes,age.getBytes)
(new ImmutableBytesWritable,row)
}
//下一步要做的工作:
hbaseRDD.saveAsNewAPIHadoopDataset(job.getConfiguration)
}
}
3、启动多台虚拟机
4、启动zookeeper集群
5、启动伪分布式Hadoop
6、启动hbase集群
[root@hadoop01 bin]# cd /home/software/hbase/bin/
[root@hadoop01 bin]# sh start-hbase.sh
7、进入Hbase客户端,建表
[root@hadoop01 bin]# sh hbase shell
hbase(main):001:0> create 'tbh','cf1'
hbase(main):002:0> scan 'tbh'
ROW COLUMN+CELL
0 row(s) in 0.0870 seconds
8、启动spark,执行测试
hbase(main):003:0> scan 'tbh'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=1630481015736, value=23
1 column=cf1:name, timestamp=1630481015736, value=tom
2 column=cf1:age, timestamp=1630481015736, value=18
2 column=cf1:name, timestamp=1630481015736, value=rose
3 column=cf1:age, timestamp=1630481015736, value=25
3 column=cf1:name, timestamp=1630481015736, value=jim
4 column=cf1:age, timestamp=1630481015736, value=20
4 column=cf1:name, timestamp=1630481015736, value=jsry
4 row(s) in 0.0880 seconds
hbase(main):004:0>
(Ⅱ)读数据:
1、ReadDriver
package cn.edu.hbase
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.client.Result
/**
* 通过spark和Hbase整合,从指定的HBase表中读取数据
*/
object ReadDriver {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("read")
val sc = new SparkContext(conf)
// 创建Hbase的环境参数对象
val hbaseConf = HBaseConfiguration.create()
//设定zookeeper集群地址
hbaseConf.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")
//设定zookeeper通信端口
hbaseConf.set("hbase.zookeeper.property.clientPort","2181")
// 指定读取的HBase表名
hbaseConf.set(TableInputFormat.INPUT_TABLE,"tbh")
//执行读取
val resultRDD = sc.newAPIHadoopRDD(
hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result])
resultRDD.foreach{case(key,value) =>
val name = value.getValue("cf1".getBytes(),"name".getBytes())
val age = value.getValue("cf1".getBytes(),"age".getBytes())
println(new String(name) + ":" +new String(age))
}
}
}
2、ScanDriver
package cn.edu.hbase
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.Base64
import org.apache.spark.{SparkConf, SparkContext}
object ScanDriver {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("read")
val sc = new SparkContext(conf)
// 创建Hbase的环境参数对象
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")
hbaseConf.set("hbase.zookeeper.property.clientPort","2181")
// 指定读取的表名
hbaseConf.set(TableInputFormat.INPUT_TABLE,"tbh")
// 创建扫描对象
val scan = new Scan()
// 设置扫描起始的行健
scan.setStartRow("2".getBytes())
// 设定搜秒的终止行健(含头不含尾)
scan.setStopRow("4".getBytes())
// 设置Scan对象
hbaseConf.set(TableInputFormat.SCAN,
//org.apache.hadoop.hbase.util.Base64
Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray()))
// 执行读取,将整表的数据返回到数据集上
// data[(key,value)]
val data = sc.newAPIHadoopRDD(hbaseConf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result]);
data.foreach{case(key,value) =>
val name = value.getValue("cf1".getBytes(),"name".getBytes())
val age = value.getValue("cf1".getBytes(),"age".getBytes())
println(new String(name) + ":" +new String(age))
}
}
}
(三)对(一)进一步处理
1、新建logBean与TongjiBean
package cn.edu.pojo
case class logBean (url:String,
urlname:String,
uvid:String,
ssid:String,
sscount:String,
sstime:String,
cip:String
) {
}
package cn.edu.pojo
case class TongjiBean (sstime:String,
pv:Int,
uv:Int,
vv:Int,
newip:Int,
newcust:Int){
}
2、新建HbaseUtil
package cn.edu.dao
import org.apache.spark.SparkContext
import cn.edu.pojo.LogBean
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.fs.shell.find.Result
import org.apache.hadoop.hbase.client.Put
import scala.util.Random
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.client.Scan
import org.apache.hadoop.hbase.filter.RowFilter
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp
import org.apache.hadoop.hbase.filter.RegexStringComparator
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.Base64
object HBaseUtil {
/*
* 将封装的日志数据插入到指定的HBase表中
*/
def saveToHBase(sc: SparkContext, logbean: LogBean) = {
sc.hadoopConfiguration.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03")
sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort", "2181")
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE,"logtable")
//org.apache.hadoop.mapreduce.Job
val job=new Job(sc.hadoopConfiguration)
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
//org.apache.hadoop.fs.shell.find.Result
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val rdd=sc.parallelize(List(logbean))
val hbaseRDD=rdd.map { bean =>
//org.apache.hadoop.hbase.client.Put
//创建HBase的行对象并指定行键。本项目行键设计为:sstime_uvid_ssid_cip_随机数字
//这样设计行键的目的:
//1.因为HBase底层会对行键做升序排序,所以如果以时间戳开头,即意味着按时间戳做升序排序,即时间有序,便于后续按时间段范围进行查询
//2.行键中还包含了用户id,会话id和cip信息,便于后续统计对应的指标,uv,vv,newip等
//3.最后拼接一个随机数字,满足行键的散列原则
//scala.util.Random
val rowKey=bean.sstime+"_"+bean.uvid+"_"+bean.ssid+"_"+bean.cip+"_"+Random.nextInt(100)
val row=new Put(rowKey.getBytes)
row.add("cf1".getBytes,"url".getBytes, bean.url.getBytes)
row.add("cf1".getBytes,"urlname".getBytes, bean.urlname.getBytes)
row.add("cf1".getBytes,"uvid".getBytes, bean.uvid.getBytes)
row.add("cf1".getBytes,"ssid".getBytes, bean.ssid.getBytes)
row.add("cf1".getBytes,"sscount".getBytes, bean.sscount.getBytes)
row.add("cf1".getBytes,"sstime".getBytes, bean.sstime.getBytes)
row.add("cf1".getBytes,"cip".getBytes, bean.cip.getBytes)
(new ImmutableBytesWritable,row)
}
//执行插入到HBase表中
hbaseRDD.saveAsNewAPIHadoopDataset(job.getConfiguration)
}
/*
* 根据时间戳范围并结合正则表达式对HBase表进行范围扫描查询
*/
def queryHBase(sc: SparkContext, startTime: Long, endTime: Long, regex: String) = {
val hbaseConf=HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03")
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181")
hbaseConf.set(TableInputFormat.INPUT_TABLE,"logtable")
//org.apache.hadoop.hbase.client.Scan
val scan=new Scan
//设定扫描的起始和终止行键
scan.setStartRow(startTime.toString().getBytes)
scan.setStopRow(endTime.toString().getBytes)
//org.apache.hadoop.hbase.filter.RowFilter
//org.apache.hadoop.hbase.filter.RegexStringComparator
//创建HBase的行键正则过滤器
val filter=new RowFilter(CompareOp.EQUAL,new RegexStringComparator(regex))
//绑定过滤器
scan.setFilter(filter)
//设置scan对象使其生效
hbaseConf.set(TableInputFormat.SCAN,
//org.apache.hadoop.hbase.util.Base64
Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray()))
//执行读取并返回结果集RDD
val resultRDD=sc.newAPIHadoopRDD(
hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
resultRDD
}
}
3、修改Driver
package cn.edu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.KafkaUtils
import cn.edu.pojo.LogBean
import cn.edu.dao.HBaseUtil
import java.util.Calendar
import cn.edu.pojo.TongjiBean
import cn.edu.dao.MysqlUtil
object Driver {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local[3]").setAppName("kafkasource")
val sc=new SparkContext(conf)
//SparkStreaming做实时流处理,将连续不断的实时流数据离散化成一批一批的数据进行处理。
//下面的Seconds(5)表示每5s一个批次进行处理
val ssc=new StreamingContext(sc,Seconds(5))
//指定zookeeper集群地址。有几台写几个。注意:如果写主机名,前提是window的hosts文件中需要进行配置
//编辑:C:\Windows\System32\drivers\etc\hosts
val zkHosts="hadoop01:2181,hadoop02:2181,hadoop03:2181"
//指定消费组名(组内是竞争消费,组间是共享消费)
val group="gp"
//指定消费的主题信息。通过Map封装。key是消费的主题名。value是消费的线程数。至少是1个,也可以是多个。
val topics=Map("logdata"->1)
//通过SparkStreaming和Kafka整合包提供的工具类,从kafka指定主题消费数据
val kafkaSource=KafkaUtils.createStream(ssc, zkHosts, group, topics)
.map{x=>x._2}
//对实时流数据进行处理。
//DStream的foreachRDD方法的作用:将当前批次内的数据直接封装为RDD
kafkaSource.foreachRDD{rdd=>
//将RDD数据转换为迭代器
val lines=rdd.toLocalIterator
//遍历迭代器,获取每条数据进行处理
while(lines.hasNext){
//获取一条数据
val line=lines.next()
//第一步:做字段清洗。所需的字段:url urlname uvid ssid sscount sstime cip
val arr=line.split("\\|")
val url=arr(0)
val urlname=arr(1)
val uvid=arr(13)
val ssid=arr(14).split("_")(0)
val sscount=arr(14).split("_")(1)
val sstime=arr(14).split("_")(2)
val cip=arr(15)
//第二步:将字段封装到bean中
val logbean=LogBean(url,urlname,uvid,ssid,sscount,sstime,cip)
//第三步:统计实时流指标:pv uv vv newip newcust
//每有一条数据到达后,统计此数据的5个指标。指标的取值1 或 0
//3.1 pv:页面访问量。用户点击一次页面就算作一个PV,包括刷新操作也算。
val pv=1
//3.2 uv:独立用户数。按独立用户来统计。UV=1或UV=0,处理逻辑:
//①获取当前记录中的uvid(因为uvid标识了一个用户)
//②用此uvid去HBase表查询当天的数据
//③如果此uvid在HBase表当天的数据已经出现过,则uv=0(说明这个用户今天已经访问过了)
//反之,uv=1(说明此用户今天是第一次访问)
//难点1:如何查询HBase表'当天'的数据? 可以根据时间戳进行范围扫描查询。
//查询的起始时间戳 startTime=当天凌晨零点的时间戳
//查询的终止时间戳 endTime=当前记录中的sstime
//难点2:如何判断当前记录中的uvid是否在HBase表出现过呢?可以根据HBase的行键进行正则匹配查询
val endTime=sstime.toLong
val calendar=Calendar.getInstance
//以endTime时间戳为基准
calendar.setTimeInMillis(endTime)
calendar.set(Calendar.HOUR, 0)
calendar.set(Calendar.MINUTE, 0)
calendar.set(Calendar.SECOND, 0)
calendar.set(Calendar.MILLISECOND, 0)
//获取当天凌晨零点的时间戳
val startTime=calendar.getTimeInMillis
val uvRegex="^\\d+_"+uvid+".*$"
val uvResult=HBaseUtil.queryHBase(sc,startTime,endTime,uvRegex)
val uv=if(uvResult.count()==0) 1 else 0
//3.3 vv:独立会话数据。VV=1 或 VV=0,处理思路同UV。判断指标更换为当前记录的ssid去判断。
val vvRegex="^\\d+_\\d+_"+ssid+".*$"
val vvResult=HBaseUtil.queryHBase(sc, startTime, endTime, vvRegex)
val vv=if(vvResult.count()==0)1 else 0
//3.4 newip:新增ip。newip=1 或 newip=0。根据当前记录中的ip,去HBase表查询历史(当天及以往的)数据。
//如果在历史数据中从未出现过,则newip=1。反之newip=0
val ipRegex="^\\d+_\\d+_\\d+_"+cip+".*$"
val ipResult=HBaseUtil.queryHBase(sc, 0, endTime, ipRegex)
val newip=if(ipResult.count()==0)1 else 0
//3.5 newcust:新增用户。newcust=1 或newcust=0,处理思路同newip。判断指标更换为uvid
val custResult=HBaseUtil.queryHBase(sc, 0, endTime, uvRegex)
val newcust=if(custResult.count()==0)1 else 0
//第四步:将统计好的业务指标封装到bean,后续在插入更新到mysql表中
val tongjibean=TongjiBean(sstime,pv,uv,vv,newip,newcust)
MysqlUtil.saveToMysql(tongjibean)
//将bean数据插入到HBase表中
HBaseUtil.saveToHBase(sc,logbean)
println("pv="+pv+" uv="+uv+" vv="+vv+" newip="+newip+" newcust="+newcust)
}
}
ssc.start()
//保持SparkStreaming一致开启。直到用户主动退出为止。
ssc.awaitTermination()
}
}
hbase(main):002:0> create 'logtable','cf1'
0 row(s) in 0.9790 seconds
=> Hbase::Table - logtable
hbase(main):003:0> scan 'logtable'
ROW COLUMN+CELL
0 row(s) in 0.0880 seconds
4、项目与Mysql整合步骤
1、引入mysql和c3p0相关的jar包以及cp30的配置文件
将下面目录下的两个内容其放于工程目录下,并将mysql-lib中的jar build path

2、进入mysql,创建weblog库
[root@hadoop01 ~]# mysql -uroot -proot
......
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> create database weblog;
Query OK, 1 row affected (0.00 sec)
3、切到weblog,创建tongji2表
mysql> use weblog;
Database changed
mysql> create table tongji2(reporttime date,pv int,uv int,vv int,newip int,newcust int);
Query OK, 0 rows affected (0.02 sec)
4、编写代码,将实时流处理的指标插入或更新到tongji2表中
package cn.edu.dao
import cn.edu.pojo.TongjiBean
import com.mchange.v2.c3p0.ComboPooledDataSource
import java.sql.Connection
import java.text.SimpleDateFormat
import java.sql.PreparedStatement
import java.sql.ResultSet
object MysqlUtil {
//获取数据库连接池
val c3p0=new ComboPooledDataSource
def saveToMysql(tongjibean: TongjiBean) = {
var conn:Connection=null
var ps1:PreparedStatement=null
var rs:ResultSet=null
var ps2:PreparedStatement=null
var ps3:PreparedStatement=null
try{
conn=c3p0.getConnection
//去查询mysql weblog库下的tongji2表。查询当天数据,如果当天还没有数据,则做新增插入操作
//如果当天已经有数据,则做更新累加
ps1=conn.prepareStatement("select * from tongji2 where reporttime=?")
val sdf=new SimpleDateFormat("YYYY-MM-dd")
//解析出当天的日期。
val todayTime=sdf.format(tongjibean.sstime.toLong)
//传入当天日期到sql语句中
ps1.setString(1, todayTime)
//执行查询并得到结果集
rs=ps1.executeQuery()
if(rs.next()){
//说明当天已经有数据了,则做更新累加
ps2=conn.prepareStatement(
"update tongji2 set pv=pv+?,uv=uv+?,vv=vv+?,newip=newip+?,newcust=newcust+? where reporttime=?")
ps2.setInt(1, tongjibean.pv)
ps2.setInt(2, tongjibean.uv)
ps2.setInt(3, tongjibean.vv)
ps2.setInt(4, tongjibean.newip)
ps2.setInt(5, tongjibean.newcust)
ps2.setString(6,todayTime)
ps2.executeUpdate()
}else{
//说明当天还没有数据,则新增插入
ps3=conn.prepareStatement("insert into tongji2 values(?,?,?,?,?,?)")
ps3.setString(1, todayTime)
ps3.setInt(2, tongjibean.pv)
ps3.setInt(3, tongjibean.uv)
ps3.setInt(4, tongjibean.vv)
ps3.setInt(5, tongjibean.newip)
ps3.setInt(6, tongjibean.newcust)
ps3.executeUpdate()
}
}catch{
case t:Exception=>t.printStackTrace()
}finally{
if(ps3!=null)ps3.close()
if(ps2!=null)ps2.close()
if(rs!=null)rs.close()
if(ps1!=null)ps1.close()
if(conn!=null)conn.close()
}
}
}
三、项目运行步骤总结
1、启动虚拟机
2、启动Zookeeper集群
sh /home/software/zookeeper-3.4.8/bin/zkServer. sh start
3、启动伪分布式Hadoop
完全分布式
在三台节点启动JournalNode:hadoop-daemon.sh start journalnode
在第一、二台节点上启动NameNode:hadoop-daemon.sh start namenode
在三台节点上启动DataNode:hadoop-daemon.sh start datanode
在第一台节点和第二节点上启动zkfc(FailoverController):hadoop-daemon.sh start zkfc
在第三个节点上启动Yarn:start-yarn.sh
在第一个节点上启动ResourceManager:yarn-daemon.sh start resourcemanager
4、启动HBase集群
进入01服务器的 hbase的 bin目录,执行︰sh start-hbase.sh
[root@hadoop01 ~]# sh /home/software/hbase/bin/start-hbase.sh start
5、启动Kafka集群
进入kafka的bin目录,执行∶
sh kafka-server-start.sh …/config/server. properties
[root@hadoop03 ~]# sh /home/software/kafka/bin/kafka-server-start.sh /home/software/kafka/config/server.properties
6、启动F1ume
进入f1ume 的配置文件目录,执行︰
…/bin/flume-ng agent -n al -c ./ -f ./web1og.conf-Df1ume.root.1ogger=INFO, console
[root@hadoop01 ~]# cd /home/software/flume/bin/
[root@hadoop01 bin]# sh flume-ng agent --conf ../conf --conf-file ../conf/weblog.conf --name a1 -Dflume.root.logger=INFO,console
7、启动Tomcat
8、启动SparkStreaming
9、访问埋点服务器进行测试,测试数据
四、遇到问题及解决方法
(一)运行flume时出错
2021-09-01 11:01:08,307 (conf-file-poller-0) [ERROR - org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:427)] Sink k2 has been removed due to an error during configuration
org.apache.flume.conf.ConfigurationException: brokerList must contain at least one Kafka broker
at org.apache.flume.sink.kafka.KafkaSinkUtil.addDocumentedKafkaProps(KafkaSinkUtil.java:55)
原因:配置文件写错,a1.sinks.k1.brokerList写成了a1.sinks.brokeList
(二)ReadDriver出错
[2021-09-01 16:07:56,949] WARN Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect (org.apache.zookeeper.ClientCnxn:1102)
java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
原因 设定zookeeper集群地址与通信端口出错,不能直接复制WriteDrive
应为
//设定zookeeper集群地址
hbaseConf.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")
//设定zookeeper通信端口
hbaseConf.set("hbase.zookeeper.property.clientPort","2181")
而非
sc.hadoopConfiguration.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")
//指定zookeeper通信端口
sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort","2181")














 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









