







第九(八)天:Kafka
一、Kafka简介
(一)Kafka

(Ⅰ )概述
1、Kafka是由LinkedIn(领英)开发的一个分布式的消息系统,最初是用作LinkedIn的活动流(Activity Stream)和运营数据处理的基础
a. 活动流数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析
b. 运营数据指的是服务器的性能数据(CPU、IO使用率、请求时间、服务日志等等数据)。运营数据的统计方法种类繁多。
2、Kafka是一个分布式的流式处理平台,主要包含三个功能:
a. 发布和订阅数据,类似于消息队列或者企业中的消息传递系统
b. 存储数据的时候有容错(分布式+复本机制)和持久化机制
c. 数据产生的时候处理记录(数据)
3、应用场景:
a. 在系统或者应用程序之间构建可靠的数据传输的实时流管道
b. 在转换或者响应数据流的时候构建实时流程序、
4、Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成
5、Kafla之间传输数据是使用的零拷贝技术
(Ⅱ)消息队列对比
1、RabbitMQ
a. RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发
b. 实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持
2、Redis
a. Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃
b. 虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用
3、ZeroMQ
a. ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景
b. ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战
c. ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter的Storm 0.9.0以前的版本中默认使用ZeroMQ作为数据流的传输(Storm从0.9版本开始同时支持ZeroMQ和Netty(NIO)作为传输模块)
4、ActiveMQ
a. ActiveMQ是Apache下的一个子项目
b. 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列
c. 类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
5、消息队列的优势:
a. 屏蔽生产者和消费者之间的异构型
b. 实现消峰限流
(二)kafka安装
(Ⅰ )上传文件

(Ⅱ)解压文件并重命名
[root@hadoop01 config]# tar -zxvf kafka_2.11-1.0.0.tgz
[root@hadoop01 software]# mv kafka_2.11-1.0.0 kafka
(Ⅲ)修改配置文件,编辑server.properties
[root@hadoop01 software]# cd kafka/config/
[root@hadoop01 config]# vim server.properties
log.dirs=/home/software/kafka/kafka-logs
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
(Ⅳ)拷贝并修改配置文件
scp -r kafka 192.168.232.130:/home/software
scp -r kafka 192.168.232.131:/home/software
更改配置文件的broker.id编号(不重复即可)
[root@hadoop02 software]# cd kafka/config/
[root@hadoop02 config]# vim server.properties
[root@hadoop03 software]# cd kafka/config/
[root@hadoop03 config]# vim server.properties
(Ⅴ)启动zookeeper集群
对hadoop01、hadoop02、hadoop03均执行以下命令
sh /home/software/zookeeper-3.4.7/bin/zkServer.sh start
(Ⅵ)启动kafka
&表示后台启动
sh kafka-server-start.sh ../config/server.properties &
(Ⅶ)进入zookeeper启动zkCli
[root@hadoop01 bin]# cd /home/software/zookeeper-3.4.7/bin/
[root@hadoop01 bin]# sh zkCli.sh
......
[zk: localhost:2181(CONNECTED) 0] ls /
[park01, cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
[zk: localhost:2181(CONNECTED) 1]
(三)基本指令(kafka是面向topic、存储数据基于磁盘进行存储)
(Ⅰ)指令表
| 命令 | 作用 |
|---|---|
| sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic english | 创建主题:在创建的时候,复本数量要小于等于节点数量 |
| sh kafka-topics.sh --list --zookeeper hadoop01:2181 | 查看所有的topic |
| sh kafka-console-producer.sh --broker-list hadoop01:9092 --topic englishbook | 启动生产者 |
| sh kafka-console-consumer.sh --zookeeper hadoop01:2181 --topic englishbook --from-beginning | 启动消费者 |
| sh kafka-topics.sh --delete --zookeeper hadoop01:2181 --topic englishbook | 删除topic |
| ./kafka-topics.sh --describe --zookeeper hadoop01:2181 --topic enbook; | 查看topic情况 |
| sh kafka-topics.sh --delete --zookeeper hadoop01:2181 --topic enbook | 删除topic指令:进入bin目录,执行 |
如果删除topic时,只是marked删除,而没有真正删除。可以通过配置 config目录下的 server.properties文件,加入如下的配置:delete.topic.enable=true
(Ⅱ)具体实现
[root@hadoop01 bin]# sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic englishbook
.......
[root@hadoop01 bin]# sh kafka-topics.sh --list --zookeeper hadoop01:2181
english
englishbook
[root@hadoop01 bin]# sh kafka-topics.sh --zookeeper hadoop01:2181 --list
english
englishbook
在窗口1
[root@hadoop01 bin]# sh kafka-console-consumer.sh --zookeeper hadoop01:2181 --topic englishbook
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
[2021-08-25 09:19:37,129] INFO Updated PartitionLeaderEpoch. New: {epoch:0, offset:0}, Current: {epoch:-1, offset-1} for Partition: englishbook-0. Cache now contains 0 entries. (kafka.server.epoch.LeaderEpochFileCache)
在窗口2
[root@hadoop01 ~]# cd /home/software/kafka/bin/
[root@hadoop01 bin]# sh kafka-console-producer.sh --broker-list hadoop01:9092 --topic englishbook
>hello
>nihao
>afs
>FDGHGJ
在窗口1出现
hello
nihao
afs
FDGHGJ
[root@hadoop01 bin]# cd ..
[root@hadoop01 kafka]# ll kafka-logs/
总用量 24
-rw-r--r--. 1 root root 0 8月 25 08:51 cleaner-offset-checkpoint
drwxr-xr-x. 2 root root 4096 8月 25 09:12 english-0
drwxr-xr-x. 2 root root 4096 8月 25 09:19 englishbook-0
-rw-r--r--. 1 root root 4 8月 25 09:23 log-start-offset-checkpoint
-rw-r--r--. 1 root root 54 8月 25 08:51 meta.properties
-rw-r--r--. 1 root root 32 8月 25 09:23 recovery-point-offset-checkpoint
-rw-r--r--. 1 root root 32 8月 25 09:24 replication-offset-checkpoint
[root@hadoop01 kafka]# cd /home/software/kafka/bin/
[root@hadoop01 bin]# sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 2 --topic chinabook
如果同时启动两个kafka会在两台机器上各一个
[root@hadoop01 bin]# ls ../kafka-logs/
chinabook-0 log-start-offset-checkpoint
chinabook-1 meta.properties
cleaner-offset-checkpoint recovery-point-offset-checkpoint
english-0 replication-offset-checkpoint
englishbook-0
[root@hadoop01 bin]# sh kafka-topics.sh --zookeeper hadoop01:2181 --list
chinabook
englishbook
[root@hadoop01 bin]# sh kafka-topics.sh --delete --zookeeper hadoop01:2181 --topic chinabook
......
[root@hadoop01 bin]# sh kafka-topics.sh --zookeeper hadoop01:2181 --list
englishbook
(四)消息系统语义
(Ⅰ)概述
1、在一个分布式发布订阅消息系统中,组成系统的计算机总会由于各自的故障而不能工作。在Kafka中,一个单独的broker,可能会在生产者发送消息到一个topic的时候宕机,或者出现网络故障,从而导致生产者发送消息失败。根据生产者如何处理这样的失败,产生了不同的语义:
a. 至少一次语义(At least once semantics):如果生产者收到了Kafka broker的确认(acknowledgement,ack),并且生产者的acks配置项设置为all(或-1),这就意味着消息已经被精确一次写入Kafka topic了。然而,如果生产者接收ack超时或者收到了错误,它就会认为消息没有写入Kafka topic而尝试重新发送消息。如果broker恰好在消息已经成功写入Kafka topic后,发送ack前,出了故障,生产者的重试机制就会导致这条消息被写入Kafka两次,从而导致同样的消息会被消费者消费不止一次。每个人都喜欢一个兴高采烈的给予者,但是这种方式会导致重复的工作和错误的结果
b. 至多一次语义(At most once semantics):如果生产者在ack超时或者返回错误的时候不重试发送消息,那么消息有可能最终并没有写入Kafka topic中,因此也就不会被消费者消费到。但是为了避免重复处理的可能性,导致接受有些消息可能被遗漏处理
c. 精确一次语义(Exactly once semantics):即使生产者重试发送消息,也只会让消息被发送给消费者一次。精确一次语义是最令人满意的保证,但也是最难理解的。因为它需要消息系统本身和生产消息的应用程序还有消费消息的应用程序一起合作。比如,在成功消费一条消息后,又把消费的offset重置到之前的某个offset位置,那么将收到从那个offset到最新的offset之间的所有消息。这解释了为什么消息系统和客户端程序必须合作来保证精确一次语义
(Ⅱ)新版本Kafka的幂等性实现
1、一个幂等性的操作就是一种被执行多次造成的影响和只执行一次造成的影响一样的操作。现在生产者发送的操作是幂等的了。如果出现导致生产者重试的错误,同样的消息,仍由同样的生产者发送多次,将只被写到kafka broker的日志中一次
2、对于单个分区,幂等生产者不会因为生产者或broker故障而发送多条重复消息。想要开启这个特性,获得每个分区内的精确一次语义,需要设置producer配置中的”enable.idempotence=true”
3、在底层,它和TCP的工作原理有点像:每发送到Kafka的消息都将包含一个序列号,broker将使用这个序列号来删除重复的发送。和只能在瞬态内存中的连接中保证不重复的TCP不同,这个序列号被持久化到副本日志,所以,即使分区的leader挂了,其他的broker接管了leader,新leader仍可以判断重新发送的是否重复了。这种机制的开销非常低:每批消息只有几个额外的字段
4、此外,Kafka除了构建于生产者—>broker的幂等性之外,从broker->消费者的精确一次流处理现在可以通过Apache Kafka的流处理API实现,仅需要设置配置:“processing.guarantee = exact_once”。 这可以保证消费者的所有处理恰好发生一次。这就是为什么Kafka的Streams API提供的精确一次性保证是迄今为止任何流处理系统提供的最强保证
5、Kafka为流处理应用程序提供端到端的一次性保证,从Kafka读取的数据,Streams应用程序物化到Kafka的任何状态,到写回Kafka的最终输出。 仅依靠外部数据系统来实现状态支持的流处理系统对于精确一次的流处理提供了较少的保证。 即使他们使用Kafka作为流处理的源并需要从失败中恢复,他们也只能倒回他们的Kafka偏移量来重建和重新处理消息,但是不能回滚外部系统中的关联状态,导致状态不正确,更新不是幂等的。
(Ⅲ)通过代码来设置消息系统语义
Producer
@Test
public void producer() throws ExecutionException {
Properties props = new Properties();
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.150.137:9092,192.168.150.138:9092");
// 至多一次
props.put("acks", 0);
// 至少一次
props.put("acks", all);
// 精确一次
props.put("acks", "all");
props.put("enable.idempotence", "true");
Producer<Integer, String> kafkaProducer = new KafkaProducer<Integer, String>(props);
for (int i = 0; i < 100; i++) {
ProducerRecord<Integer, String> message = new ProducerRecord<Integer, String>("jpbook", "" + i);
kafkaProducer.send(message);
}
while (true) ;
}
Consumer的至多一次
概述
kafka consumer是默认至多一次,consumer的配置是:
1. 设置enable.auto.commit 为 true
2. 设置 auto.commit.interval.ms为一个较小的值默认101毫秒指的是消费者拿到消息后101毫秒自动提交offset
3. consumer不去执行 consumer.commitSync(), 这样, Kafka 会每隔一段时间自动提交offset
代码
@Test
public void consumer_2() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.150.137:9092,192.168.150.138:9092");
props.put("group.id", "g1");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "101");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("enbook", "t2"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records)
System.out.println("g1组c2消费者,分区编号:" + record.partition() + "offset:" + record.offset() + ":" + record.value());
}
} catch (Exception e) {
} finally {
consumer.close();
}
}
Consumer的至少一次
概述
1. 设置enable.auto.commit 为 false 或者
2. 处理完后consumer调用 consumer.commitSync()
代码
@Test
public void consumer_2() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.150.137:9092,192.168.150.138:9092");
props.put("group.id", "g1");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
props.put("enable.auto.commit", "false");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("enbook", "t2"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records)
// Process……
// 处理完成后,用户自己手动提交offset
consumer.commitAsync();
}
} catch (Exception e) {
} finally {
consumer.close();
}
}
Consumer的精确一次
@Test
public void consumer_2() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.150.137:9092,192.168.150.138:9092");
props.put("group.id", "g1");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
props.put("enable.auto.commit", "false");
props.put("processing.guarantee", "exact_once");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("enbook", "t2"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records)
consumer.commitAsync();
}
} catch (Exception e) {
} finally {
consumer.close();
}
}
(五)参数配置

二、基本概念
(一)Kafka拓扑结构

1、producer:消息的生产者,可送消息到kafka
2、broker:kafka集群的角色
3、topic;每一条发送到kafka上的消息都应该有自己的类别,也就是说kafka是面向topic的
4、partition:每一个topic都会有多个partition。kafka分配的单位就是partition,是一个物理概念
5、replication:partition的复本。保障partition的高可用
6、consumer:从kafka集群中去消费数据
7、consumer group:每一个consumer都属于一个consumer-group,每一条消息只能被消费者组中的一个消费者消费,但是消费者组之间是可以一起消费的
8、leader;复本的一个角色,生产者与消费者只能和leader进行交互
9、follower;复本的一个角色,从leader中复制数据
10、controller;kafka集群其中的一个服务器,用来进行leader的选举,和失败恢复
11、zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息
(二)Topic和Partition
(Ⅰ)示意图


(Ⅱ)说明1
1、Topic在逻辑上可以被认为是一个queue,每条消息都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。
2、为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理(磁盘)上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件
3、因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)
4、 对于传统的消息队列而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。配置如下所示
# 日志删除间隔时间
log.retention.hours=168
# 日志文件大小,达到这个大小会产生一个新的日志文件
log.segment.bytes=1073741824
# 设置是否启用日志清理
log.cleaner.enable=false
(Ⅲ)说明2
1、partition可以被看成是一个queue,每一条消息都应该指定topic。相当于指定消息放到哪一个queue中。每一条数据都是被append进queue中的,数据顺序写磁盘
2、经验证,顺序写磁盘效率要比顺序写内存还要高,这也是kafka吞吐率高的原因
(Ⅳ)演示
组间共享,组内竞争
在窗口1
[root@hadoop01 bin]# sh kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic englishbook --group group1
在窗口2
[root@hadoop01 bin]# sh kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic englishbook --group group2
在窗口3
[root@hadoop01 bin]# ./kafka-console-producer.sh --broker-list hadoop01:9092 --topic englishbook
>hia
>agkj
在窗口1 2 均出现
hia
agkj
在窗口2停掉再启动
[root@hadoop01 bin]# sh kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic englishbook --group group1
在窗口3输入
>asyg
只在窗口1出现
asyg
(三)Kafka消息流处理
(Ⅰ)图

(Ⅱ)说明1
1、producer回想kafka集群写入消息,本质上就是写入到topic的分区中,但是分区可能有多个复本,这样就需要将数据写入到leader的分区中
2、proceducer会先从zookeeper(get /brokers/topics/chinabook/partitions/state)获取该partition的leader所在的服务器
3、producer 将数据发送给该 leader
4、leader 就会将消息写入本地 log中
5、followers 从 leader中去 pull 消息,写入本地 log中并向leader 发送一个 ACK消息
6、leader 收到所有 ISR中的复本发送 的 ACK 后, 如果全部收到就会向 producer 发送一个 ACK
7、ISR:假设有五个复本a b c d e ,其中a 是Leader b c d e是Follower。假设在数据同步过程中,b c d跟上了同步的过程,但是由于e可能存在磁盘损坏,或者磁盘已满的情况,导致同步不成功,那么abcd就是ISR成员,而e不是ISR成员。将来如果leader宕机了,会触发选举,优先选举ISR列表中的成员当Leader
(Ⅲ)说明2
1、producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
{“controller_epoch”:17,“leader”:1,“version”:1,“leader_epoch”:0,“isr”:[1,0]}其中leader:1(1代表副本所在的broker id)
2、producer 将消息发送给该 leader
3、leader 将消息写入本地 log
4、followers 从 leader pull 消息,写入本地 log后,给leader 发送 ACK
5、leader 收到所有 ISR中的 replica 的 ACK 后, 并向 producer 发送 ACK
ISR指的是:比如有三个副本 ,编号是① ② ③ ,其中② 是Leader ① ③是Follower。假设在数据同步过程中,①跟上Leader,但是③出现故障或没有及时同步,则① ②是一个ISR,而③不是ISR成员。后期在Leader选举时,会用到ISR机制。会优先从ISR中选择Leader
(四)Kafka HA
(Ⅰ)概述1
1、同一个 partition 可能会有多个 replication(对应 server.properties 配置中的 default.replication.factor=N)(N表示任意数)
2、没有 replication(复本) 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition(producer 也不能向此topic生产数据)
3、引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据
(Ⅱ)概述2
1、同一个partition有多个replication (server.properties default.replication.factor=3)
2、如果没有复本。这个时候一旦broker宕机,那么此partition所有的数据都不可能被消费到。producer也不能再向此topic生产数据
3、引入多个复本,这个时候可以在复本中间选择一个leader,producer和consumer都和leader进行交互。
4、如果leader宕机,需要从follower中重新选举一个leader,选举的原则:新的leader必须拥有旧的leader commit过的所有的消息;因为有ISR列表,所以默认会从ISR列表中进行选择,其中的一个replication当leader。因为ISR列表中的复本都是能够跟上leader同步的数据的复本,所以默认会选择ISR列表中的复本当leader
5、所有的replication全部宕机。两种方案可供选择
a. 等待ISR列表中任何一个replication复活过来,并将其选择成为leader,可保证数据不丢失,但是可能花费邈时间长
b. 选择任何一个活过来的复本,但是可能会存在数据丢失的风险,但是时间较快
(Ⅱ)leader failover
1、当 partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader
2、在选举新leader时,一个基本的原则是,新的 leader 必须拥有旧 leader commit 过的所有消息
3、由写入流程可知 ISR 里面的所有 replica 都跟上了 leader,只有 ISR 里面的成员才能选为 leader。对于n个 replica,一个 partition 可以在容忍 n-1个 replica 失效的情况下保证消息不丢失。例如 一个分区 有5个副本,挂了4个,剩一个副本,依然可以工作
4、kafka的选举不同于zookeeper,用的不是过半选举
5、当所有 replica 都不工作时,有两种可行的方案:
a. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长
b. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短,kafka 0.8.* 使用第二种方式
6、kafka 通过 Controller 来选举 leade
三、机制
(一)Kafka offset机制(没跟上见视频上午3,35分-43分)
1、Consumer在从broker读取消息后,可以选择commit,该操作会在Kakfa中保存该Consumer在该Partition中读取的消息的offset
2、该Consumer下一次再读该Partition时会从下一条开始读取
3、通过这一特性可以保证同一消费者从Kafka中不会重复消费数据
4、执行过程:
a. 在创建消费者的时候产生消费者组:执行:sh kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic enbook --from-beginning --new-consumer
b. 获取消费者组的名字,执行:sh kafka-consumer-groups.sh --bootstrap-server hadoop01:9092 --list --new-consumer
5、进入kafka-logs目录查看,会发现多个很多目录,这是因为kafka默认会生成50个__consumer_offsets 的目录,用于存储消费者消费的offset位置
6、 Kafka在计算offset存储在哪一个目录中时,用:Math.abs(groupID.hashCode()) % 50计算
(二)安装kafka-eagle-web
启动前启动了:
1、 zookeeper:sh zkServer.sh start
2、kafka: sh kafka-server-start.sh …/config/server.properties &
(1)解压文件并重命名
[root@hadoop01 bin]# cd /home/software/
[root@hadoop01 software]# tar -zxvf kafka-eagle-web-1.3.3-bin.tar.gz
[root@hadoop01 software]# rm kafka-eagle-web-1.3.3-bin.tar.gz
rm:是否删除普通文件 "kafka-eagle-web-1.3.3-bin.tar.gz"?y
[root@hadoop01 software]# mv kafka-eagle-web-1.3.3 kafka-eagle-web
[root@hadoop01 software]#
(2)设置环境变量
[root@hadoop01 software]# vim /etc/profile
export JAVA_HOME=/home/software/jdk1.8.0_131
export HADOOP_HOME=/home/software/hadoop-2.7.1
export KE_HOME=/home/software/kafka-eagle-web
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$KE_HOME/bin:$PATH
[root@hadoop01 software]# source /etc/profile
(3)进入kafka-eagle的conf目录下修改配置文件,配置基础配置
[root@hadoop01 software]# cd /home/software/kafka-eagle-web/
[root@hadoop01 kafka-eagle-web]# cd /home/software/kafka-eagle-web/conf/
[root@hadoop01 conf]# vim system-config.properties
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=hadoop01:2181,hadoop02:2181,hadoop03:2181
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=25
######################################
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=true
######################################
# kafka sql topic records max
######################################
kafka.eagle.sql.topic.records.max=5000
######################################
# alarm email configure
######################################
kafka.eagle.mail.enable=false
kafka.eagle.mail.sa=alert_sa@163.com
kafka.eagle.mail.username=alert_sa@163.com
kafka.eagle.mail.password=mqslimczkdqabbbh
kafka.eagle.mail.server.host=smtp.163.com
kafka.eagle.mail.server.port=25
######################################
# alarm im configure
######################################
#kafka.eagle.im.dingding.enable=true
#kafka.eagle.im.dingding.url=https://oapi.dingtalk.com/robot/send?access_token=
#kafka.eagle.im.wechat.enable=true
#kafka.eagle.im.wechat.token=https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=xxx&corpsecret=xxx
#kafka.eagle.im.wechat.url=https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=
#kafka.eagle.im.wechat.touser=
#kafka.eagle.im.wechat.toparty=
#kafka.eagle.im.wechat.totag=
#kafka.eagle.im.wechat.agentid=
######################################
# delete kafka topic token
######################################
kafka.eagle.topic.token=chenzhe
######################################
# kafka sasl authenticate
######################################
cluster1.kafka.eagle.sasl.enable=false
cluster1.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster1.kafka.eagle.sasl.mechanism=PLAIN
cluster2.kafka.eagle.sasl.enable=false
cluster2.kafka.eagle.sasl.protocol=SASL_PLAINTEXT
cluster2.kafka.eagle.sasl.mechanism=PLAIN
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://hadoop01:3306/test
kafka.eagle.username=root
kafka.eagle.password=root
(4)启动
[root@hadoop01 conf]# cd /home/software/kafka-eagle-web/bin/
[root@hadoop01 bin]# chmod 777 ke.sh
[root@hadoop01 bin]# ./ke.sh start
.......
*******************************************************************
* Kafka Eagle system monitor port successful...
*******************************************************************
[2021-08-25 11:30:12] INFO: Status Code[0]
[2021-08-25 11:30:12] INFO: [Job done!]
Welcome to
__ __ ___ ____ __ __ ___ ______ ___ ______ __ ______
/ //_/ / | / __/ / //_/ / | / ____/ / | / ____/ / / / ____/
/ ,< / /| | / /_ / ,< / /| | / __/ / /| | / / __ / / / __/
/ /| | / ___ | / __/ / /| | / ___ | / /___ / ___ |/ /_/ / / /___ / /___
/_/ |_| /_/ |_|/_/ /_/ |_| /_/ |_| /_____/ /_/ |_|\____/ /_____//_____/
Version 1.3.3
*******************************************************************
* Kafka Eagle Service has started success.
* Welcome, Now you can visit 'http://<your_host_or_ip>:port/ke'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************
[root@hadoop01 bin]# jps
9138 NameNode
9442 SecondaryNameNode
11394 Bootstrap
2755 Kafka
2389 QuorumPeerMain
11701 Jps
9269 DataNode
9702 NodeManager
9597 ResourceManager
[root@hadoop01 bin]#
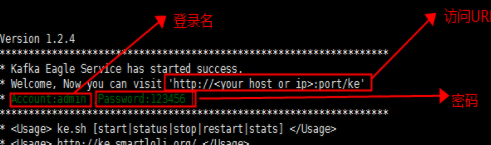
(5)在浏览器输入http://192.168.232.129:8048/ke
进入登录界面。输入用户名:admin,密码:123456(如上图)

登录后



(二)Kafka的索引机制
(Ⅰ)概述
1、Kafka解决查询效率的手段之一是将数据文件分段,可以配置每个数据文件的最大值,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名
2、每个log文件默认是1GB生成一个新的Log文件,比如新的log文件中第一条的消息的offset 16933,则此log文件的命名为:000000000000000016933.log,此外,每生成一个log文件,就会生成一个对应的索引(index)文件。(一个log+一个index文件合称为一个segment)这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中
3、数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引——Offset与position(Message在数据文件中的绝对位置)的对应关系

4、 index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了(稀疏索引+二分查找,可以加快查找速度)
索引文件被映射到内存中,所以查找的速度还是很快的
四、Kafka API使用
(1)建文档
导包:将下列选中的内容中的所有jar包复制到上面的jars中,并build path
(2)代码
package cn.edu.kafka;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.security.JaasUtils;
import org.junit.Test;
import kafka.admin.AdminUtils;
import kafka.admin.RackAwareMode;
import kafka.utils.ZkUtils;
public class KafkaTest {
@Test
public void createTopic() {
ZkUtils zkUtils = ZkUtils.apply("192.168.232.129:2181,192.168.232.130:2181,192.168.232.131:2181",
30000, 30000,JaasUtils.isZkSecurityEnabled());
AdminUtils.createTopic(zkUtils, "student",1, 1,
new Properties(), RackAwareMode.Enforced$.MODULE$);
zkUtils.close();
}
@Test
public void delete_topic() {
ZkUtils zkUtils = ZkUtils.apply("192.168.232.129:2181,192.168.232.130:2181,192.168.232.131:2181", 30000, 30000,
JaasUtils.isZkSecurityEnabled());
// 删除topic 't1'
AdminUtils.deleteTopic(zkUtils, "student");
zkUtils.close();
}
@Test
public void producer() throws InterruptedException, ExecutionException {
// 设置属性
Properties props = new Properties();
// 设置键的类型,实际上是偏移量
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
// 设置值的类型,实际上是实际数据
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置Kafka的连接地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "Hadoop01:2181");
// 添加数据
Producer<Integer, String> kafkaProducer = new KafkaProducer<Integer, String>(props);
for (int i = 0; i < 10; i++) {
ProducerRecord<Integer, String> message = new ProducerRecord<Integer, String>("student", "hello" + i);
kafkaProducer.send(message);
}
while (true) ;
}
}
五、出现问题及解决方法:
(一)启动kafka出现8048界面500
1、修改eagle目录 ./bin/ke.sh文件
//注释掉下面的几行内容:
# rm -rf $KE_HOME/kms/webapps/ke
# rm -rf $KE_HOME/kms/work
# mkdir -p $KE_HOME/kms/webapps/ke
# cd $KE_HOME/kms/webapps/ke
# ${JAVA_HOME}/bin/jar -xvf $KE_HOME/kms/webapps/ke.war
2、删除eagle目录 ./kms/webapps/ke/WEB-INF/lib下的jar包
rm -rf jackson-*.jar
3、重启eagle
./bin/ke.sh restarta
(二)编写 kafka API时,创建producer,在服务器启动consumer没有反应
解决方法,修改hosts,修改ip为主机名

在上图所选中的文件中添加如下行
192.168.232.129 hadoop01
192.168.232.130 hadoop02















 6923
6923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









