






一、前言
排除掉数据集大小不够的原因, 那么就只剩下选择数据属性的问题. 排除掉专业知识的影响, 我更希望找到那种区别大, 离散程度小的数据属性.
所以我的想法就是找平均值有差距, 但是方差或者标准差小的数据属性.
二、流程展示
1. 读取数据
将不同类别的数据以行为单位放在不同的的列表中 (列表中实际上是一个二维数组), 并对每行数据进行裁剪. 因为存在有些数据需要结合其他数据集才能使用, 这是之后的思考的方向, 在这里还是暂时搁置.
import pandas as pd
file = "./test.xlsx"
data = pd.read_excel(file)
name = data.columns.tolist()
data = data.values.tolist()
layer1 = []
layer2 = []
layer3 = []
for i in range(len(data)):
if data[i][-1] == "差气层":
layer1.append(data[i][5:-3])
elif data[i][-1] == "干层":
layer2.append(data[i][5:-3])
elif data[i][-1] == "气层":
layer3.append(data[i][5:-3])
else:
continue
name = name[5:-3]
2. 统计数据
这里需要注意, 因为是要观察每个数据属性, 所以这里就有一个矩阵转置的操作. 然后通过 numpy 库中的函数输出不同类别在相同数据属性下的平均值、标准差和方差.
import numpy as np
layer1 = np.array(layer1)
layer2 = np.array(layer2)
layer3 = np.array(layer3)
layer1 = layer1.T
layer2 = layer2.T
layer3 = layer3.T
for i in range(len(name)):
print(name[i]+" : ")
print("Average : ")
temp_layer1 = np.average(layer1[i])
temp_layer2 = np.average(layer2[i])
temp_layer3 = np.average(layer3[i])
print("temp_layer1 : " + str(temp_layer1))
print("temp_layer2 : " + str(temp_layer2))
print("temp_layer3 : " + str(temp_layer3))
print("\n")
print("Std : ")
temp_layer1 = np.std(layer1[i])
temp_layer2 = np.std(layer2[i])
temp_layer3 = np.std(layer3[i])
print("temp_layer1 : " + str(temp_layer1))
print("temp_layer2 : " + str(temp_layer2))
print("temp_layer3 : " + str(temp_layer3))
print("\n")
print("Var : ")
temp_layer1 = np.var(layer1[i])
temp_layer2 = np.var(layer2[i])
temp_layer3 = np.var(layer3[i])
print("temp_layer1 : " + str(temp_layer1))
print("temp_layer2 : " + str(temp_layer2))
print("temp_layer3 : " + str(temp_layer3))
print("\n")
运行截图
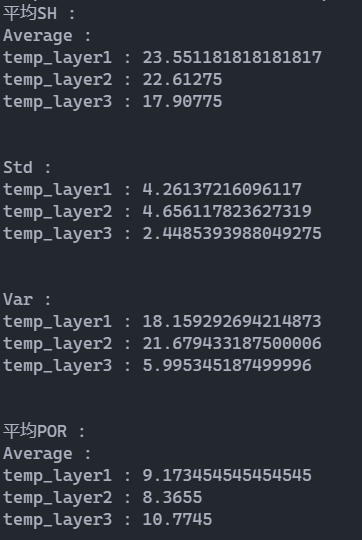
3. 选择新属性
然后通过观察, 数据属性太多就省去了画图的过程, 选出来了一些属性.
平均POR, 平均PERM, 平均DEN, 平均CNL, 平均C2, IV类厚度, III类厚度, II类厚度, I类孔隙
只需要修改之前的部分代码就可完成.
# Get column 6,7,11,12,15,17,19,21,24,27 except head
data = pd.read_excel(file, usecols=[6,7,11,12,15,17,19,21,24,27],names=None)
运行截图

高了一点点, 结果还是不尽人意.
三、总结
虽然能够想到的方法都试过了, 但是在观察数据属性的统计属性时发现了一个问题. 在进行训练之前我都没有对数据进行归一化, 犯了一个非常巨大的错误.
因为观察数据集, 发现有的数据大, 有的数据小. 归一化在这里的重要性就不用说了, 所以在写代码之前的思考和观察是必不可少的.















 2130
2130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









