






一、PaddleOCR 简介
PaddleOCR 是一套丰富、领先、且实用的OCR工具库, 助力开发者训练出更好的模型, 并应用落地.
基于 PaddleOCR 训练出的模型具有良好的文本识别性.
二、移植过程
1. 编译环境准备
我们需要编译用于移动端的 Paddle Lite 以及 C++ demo.
C++ 环境
gcc、g++ == 7.5.0
CMake == 3.10.3
Android NDK == r17c
Java 环境
OpenJDK == 11.0.6
2. 环境安装(以 Ubuntu 18.04 为例)
# 1. 安装 gcc g++ git make wget python unzip adb curl 等基础软件
sudo apt update
sudo apt get install -y --no-install-recommends gcc g++ git make wget python unzip adb curl
# 2. 安装 JDK 和 JRE
sudo apt install -y openjdk-11-jdk
sudo apt install -y openjdk-11-jre
# 3. 安装 CMake, 以下命令以 3.10.3 版本为例, 其他版本步骤类似
wget -c https://mms-res.cdn.bcebos.com/cmake-3.10.3-Linux-x86_64.tar.gz &&
tar xzf cmake-3.10.3-Linux-x86_64.tar.gz && \
sudo mv cmake-3.10.3-Linux-x86_64 /opt/cmake-3.10 &&
sudo ln -s /opt/cmake-3.10/bin/cmake /usr/bin/cmake && \
sudo ln -s /opt/cmake-3.10/bin/ccmake /usr/bin/ccmake
# 4. 下载 linux-x86_64 版本的 Android NDK, 以下命令以 r17c 版本为例, 其他版本步骤类似.
cd /tmp && curl -O https://dl.google.com/android/repository/android-ndk-r17c-linux-x86_64.zip
cd /opt && unzip /tmp/android-ndk-r17c-linux-x86_64.zip
# 5. 添加环境变量 NDK_ROOT 指向 Android NDK 的安装路径
# 要是使用的 zsh Shell 就把 .bashrc 替换成 .zshrc
echo "export NDK_ROOT=/opt/android-ndk-r17c" >> ~/.bashrc
source ~/.bashrc
3. 编译步骤
运行编译脚本之前, 请先检查系统环境变量 NDK_ROOT 指向正确的 Android NDK 安装路径. 之后可以下载并构建 Paddle Lite 编译包.
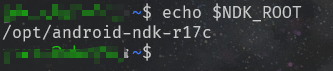
# 1. 检查环境变量 `NDK_ROOT` 指向正确的 Android NDK 安装路径
echo $NDK_ROOT
# 2. 下载 Paddle Lite 源码并切换到发布分支, 如 release/v2.10
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite && git checkout release/v2.10
# 3. 编译
./lite/tools/build_android.sh --arch=armv8 --with_cv=ON --with_extra=ON
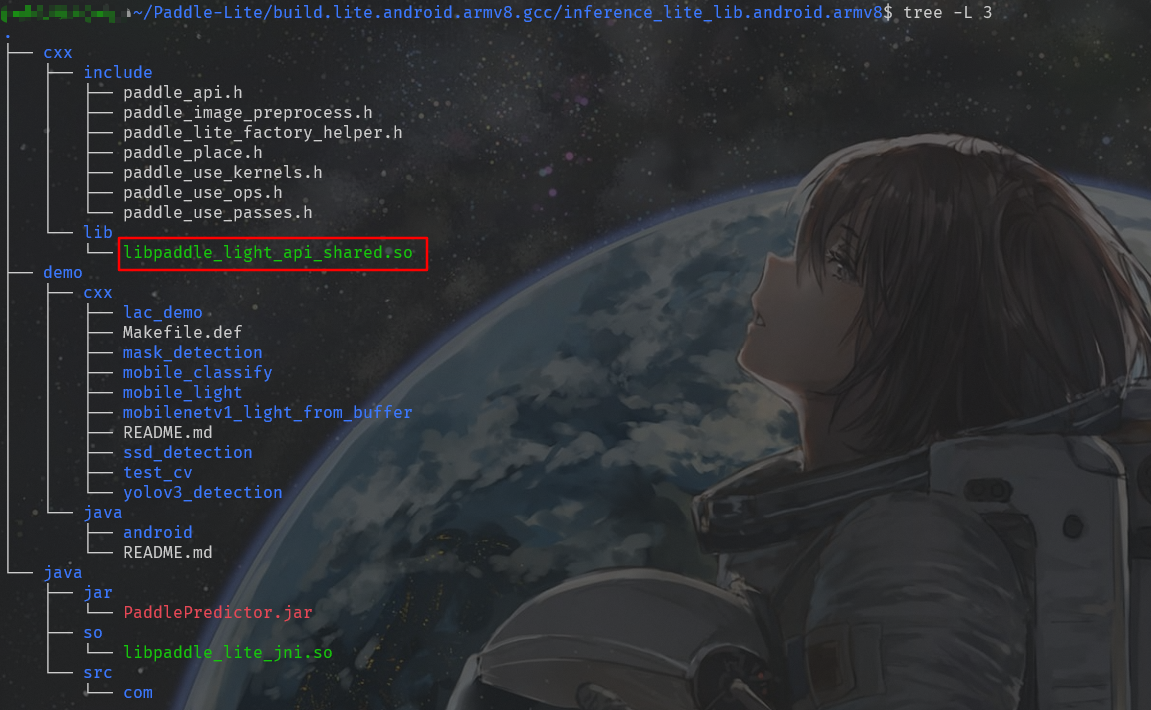
这步需要花费很久的时间, 建议使用虚拟机或者 WSL 来编译. 编译完成后我们就可以得到预测动态库 libpaddle_light_api_shared.so.
4. 模型转换
在 PC 端训练的模型是以 .pdmodel 后缀结尾的文件. 如果要在移动端使用训练的模型就需要把 .pdmodel 的文件转换成 .nb 的文件.
-
步骤一 : 安装 paddlelite 用于转换 paddle inference model 为 paddlelite 运行所需的 nb 模型.
pip install paddlelite==2.10 # paddlelite版本要与预测库版本一致安装完后, 如下指令可以查看帮助信息
paddle_lite_opt如果出现找不到命令, 那么就试着重启一下.

-
步骤二 : 使用 paddle_lite_opt 将推论模型转换成移动端模型格式.
以 PaddleOCR 的超轻量英文模型为例, 使用 paddle_lite_opt 完成推论模型到 Paddle-Lite 优化模型的转换.
# 下载 PP-OCRv3 版本的中文推论模型 wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.tar && tar xf ch_PP-OCRv3_det_slim_infer.tar wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.tar && tar xf ch_PP-OCRv3_rec_slim_infer.tar wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_cls_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_slim_infer.tar # 转换检测模型 paddle_lite_opt --model_file=./ch_PP-OCRv3_det_slim_infer/inference.pdmodel --param_file=./ch_PP-OCRv3_det_slim_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv3_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer # 转换识别模型 paddle_lite_opt --model_file=./ch_PP-OCRv3_rec_slim_infer/inference.pdmodel --param_file=./ch_PP-OCRv3_rec_slim_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv3_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer # 转换方向分类器模型 paddle_lite_opt --model_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_cls_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer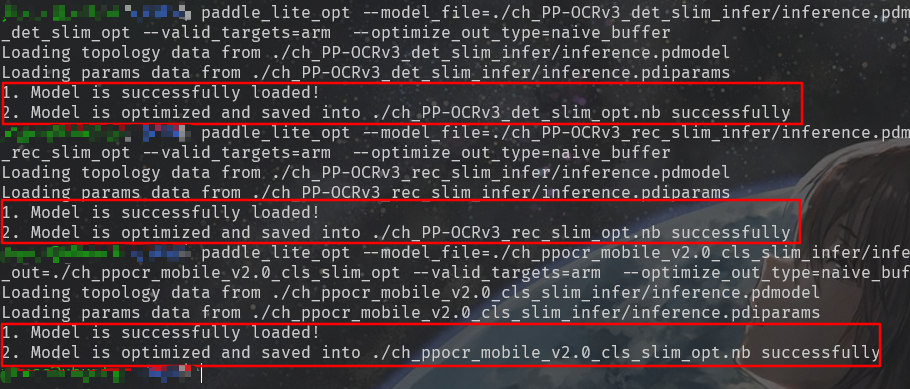
5. 与移动设备联调
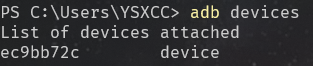
在 windows 端安装 adb 并在终端输入下面指令
adb devices
如果有device输出, 则表示安装成功.
准备优化后的模型、预测库文件、测试图像和使用的字典文件.
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR/deploy/lite/
# 运行 prepare.sh, 准备预测库文件、测试图像和使用的字典文件, 并放置在预测库中的 demo/cxx/ocr 文件夹下
# 也就是之前编译出的三个以 .nb 为后缀的文件.
sh prepare.sh /{lite prediction library path}/inference_lite_lib.android.armv8
# 进入 OCR demo 的工作目录
cd /{lite prediction library path}/inference_lite_lib.android.armv8/
cd demo/cxx/ocr/
# 将C++预测动态库so文件复制到debug文件夹中
cp ../../../cxx/lib/libpaddle_light_api_shared.so ./debug/
移动三个模型到 ./debug/ 文件夹下, 其中的 11.jpg 是测试图像.
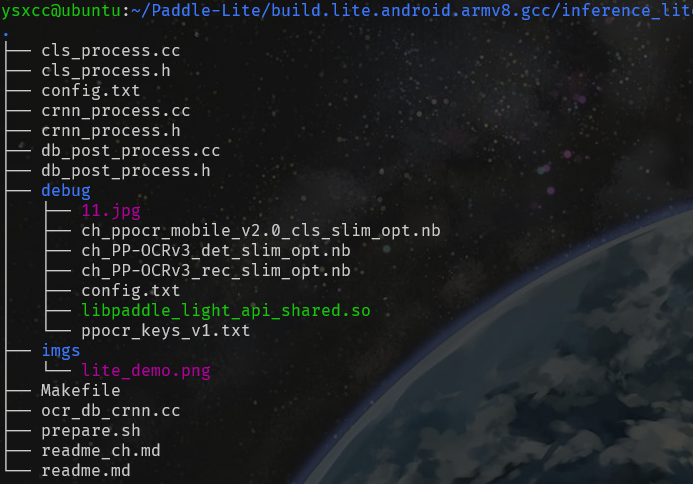
demo/cxx/ocr/
|-- cls_process.cc 方向分类器的预处理和后处理文件
|-- cls_process.h
|-- config.txt 超参数配置
|-- crnn_process.cc 识别模型CRNN的预处理和后处理文件
|-- crnn_process.h
|-- db_post_process.cc 检测模型DB的后处理文件
|-- db_post_process.h
|-- debug/
| |--11.jpg 待测试图像
| |--ch_ppocr_mobile_v2.0_cls_slim_opt.nb 优化后的文字方向分类器模型文件
| |--ch_PP-OCRv3_det_slim_opt.nb 优化后的检测模型文件
| |--ch_PP-OCRv3_rec_slim_opt.nb 优化后的识别模型文件
| |--config.txt 超参数配置
| |--libpaddle_light_api_shared.so C++预测库文件
| |--ppocr_keys_v1.txt 中文字典文件
|-- Makefile 编译文件
|-- ocr_db_crnn.cc C++预测源文件
|-- prepare.sh 文件生成脚本
|-- readme_ch.md 中文文档
|-- readme.md 英文文档
启动调试
# 执行编译,得到可执行文件 ocr_db_crnn, 第一次执行此命令会下载 opencv 等依赖库, 下载完成后, 需要再执行一次
make -j
这里会出现一个 BUG, 显示头文件的缺失.

想必这单纯是夹带私货了, 这里就需要下载 AutoLog 这个库并编译
# 在当前文件夹下 clone 这个仓库
git clone https://github.com/LDOUBLEV/AutoLog.git
cd AutoLog
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
python3 setup.py bdist_wheel
pip3 install ./dist/auto_log-1.2.0-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
# 将编译的可执行文件移动到 debug 文件夹中
mv ocr_db_crnn ./debug/
# 将 debug 文件夹 push 到手机上
adb push debug /data/local/tmp/
adb shell
cd /data/local/tmp/debug
export LD_LIBRARY_PATH=${PWD}:$LD_LIBRARY_PATH
! ! ! 这里需要注意 ocr_db_crnn 还不是可执行文件, 需要给其可执行属性.
chmod +x ./ocr_db_crnn
# 开始使用,ocr_db_crnn可执行文件的使用方式为:
# ./ocr_db_crnn 预测模式 检测模型文件 方向分类器模型文件 识别模型文件 运行硬件 运行精度 线程数 batchsize 测试图像路径 参数配置路径 字典文件路径 是否使用benchmark参数
./ocr_db_crnn system ch_PP-OCRv3_det_slim_opt.nb ch_PP-OCRv3_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt ppocr_keys_v1.txt True
# 仅使用文本检测模型,使用方式如下:
./ocr_db_crnn ch_PP-OCRv3_det_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt
# 仅使用文本识别模型,使用方式如下:
./ocr_db_crnn rec ch_PP-OCRv3_rec_slim_opt.nb arm8 INT8 10 1 word_1.jpg ppocr_keys_v1.txt config.txt
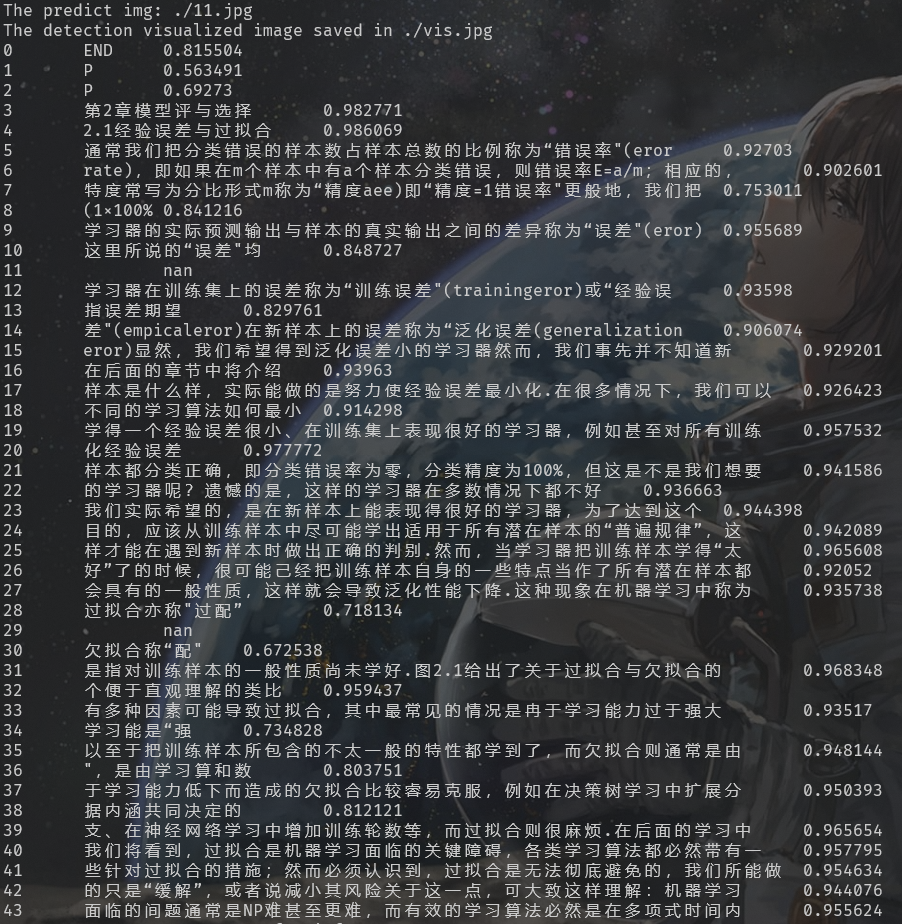
原图片 :

文本检测后的图片 :

识别情况 :
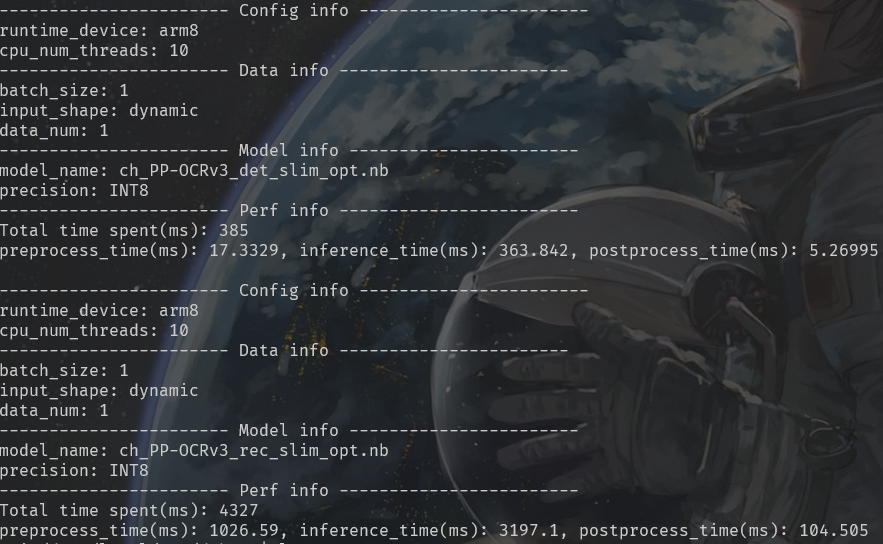
模型信息和运行速度 :
三、总结
PaddleOCR 的兼容性很差, 一个小版本都可能导致无法编译. 尤其需要注意高版本的 Android NDK, 它修改了各种库的位置, 很容易造成编译时出现头文件缺失的情况.
clone 项目尽量从 Github 进行 clone, Gitee 上虽然有相同项目文件, 但可能会出现识别文字乱码或者编译出的 ocr_db_crnn 找不到动态链接库.

















 3294
3294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









