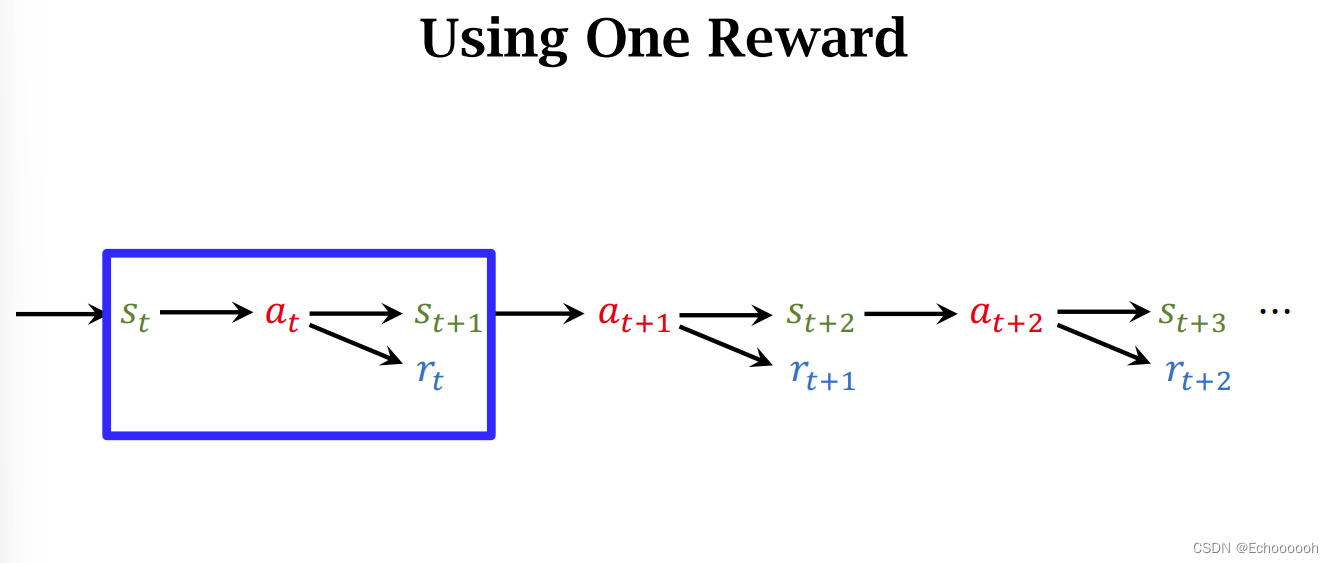
回顾 Sarsa 和 Q-Learning 两种算法都只包含一个 r t r_t rt,每次只使用一个过程单元 但其实也可以同时使用两个动作过程 这样得到的TD Target 叫做 Multi-Step TD Target 这样的效果更好一点 数学推导 若用于Sarsa算法 有 如果是Q-Learning 算法 多步TD Target 与 一步TD Target 的对比










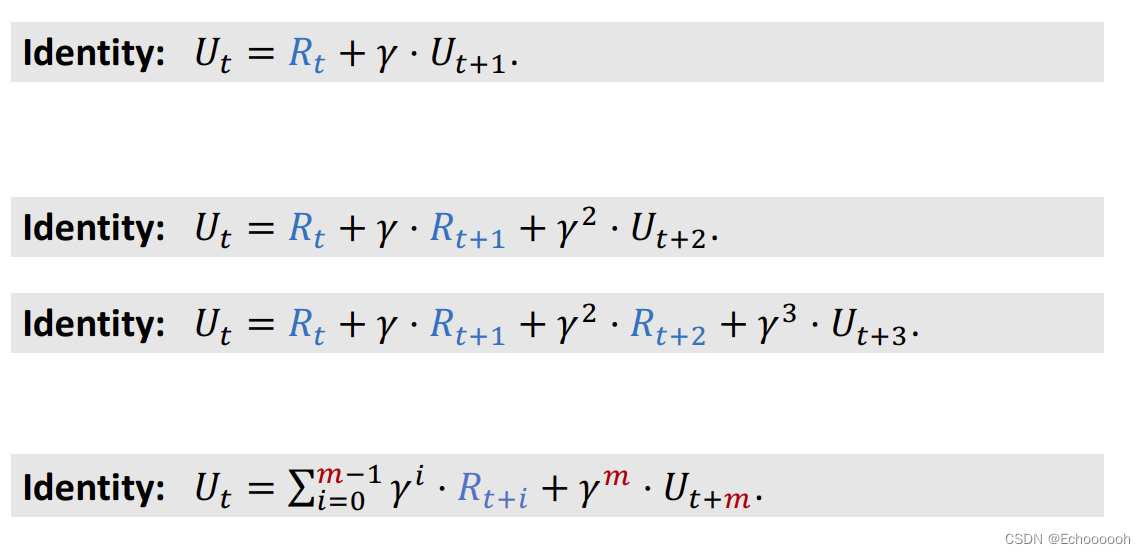


















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






