






pyspark 数据处理
本文介绍了在pyspark中数据预处理的不同步骤 。预处理技术当然会因人而异,。许多不同的方法可以用来将数据转换成所需的数据形式。本文的目的是介绍一些常见的技术 用于处理Spark中的大数据。如处理缺失的数据值、合并数据集、应用函数、聚合和排序。
创建sparksession对象
第一步是创建一个spark会话对象,以便使用Spark。我们还可以从spark.sql中导入所有所需的函数和数据类型
from pyspark.sql import SparkSession, Window
import pyspark.sql.functions as F
from pyspark.sql.types import *
import matplotlib.pyplot as plot
import pandas as pd
import seaborn as sns
spark=SparkSession.builder.appName('data_processing').getOrCreate()
创建dataframes
在下面的示例中,我们正在创建一个包含5个数据名的新数据
schema=StructType().add("user_id","string").add("country","string").add("browser", "string").add("OS",'string').add("age", "integer")
df=spark.createDataFrame([("A203",'India',"Chrome","WIN", 33),("A201",'China',"Safari","MacOS",35),("A205",'UK',"Mozilla", "Linux",25)],schema=schema)
df.printSchema()


空值处理
空值在整体数据中非常常见。因此,在数据处理流程中添加一个步骤来处理空值变得至关重要。在spark中我们可以通过替换的方式来处理空值,替换成特定的值,或者删除空值。
df_na=spark.createDataFrame([("A203",None,"Chrome","WIN",33),("A201",'China',None,"MacOS",35),("A205",'UK',"Mozilla", "Linux",25)],schema=schema)
df_na.show()

创建一个具有一定null值的dataframe
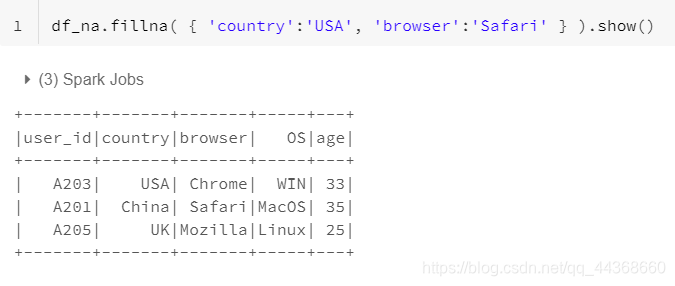
- fillna函数,将数据中的null值替换成某个数据

- fillna函数可以接收一个字典形式的参数,指定某列数据中的null值替换为何值,不同列可以将null替换成不同数值,非常方便,在实际问题中使用频率也较高。
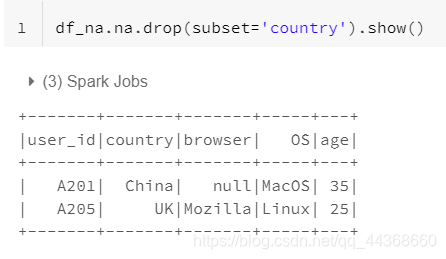
- drop函数,删除包含null值的一组数据,留下的数据中不包含任何null值

- 当然drop函数也可以传递列名,使得剩下的数据中保证该列不存在null值。
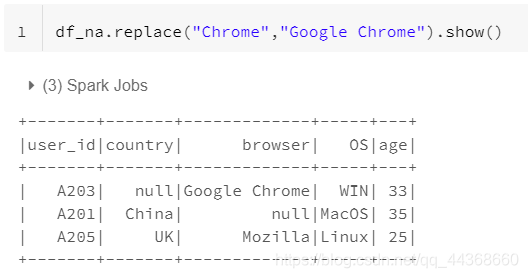
- 数据处理中另一个非常常见的步骤是替换一些数据 具有特定值的点。我们可以使用替换函数
databricks读取csv文件
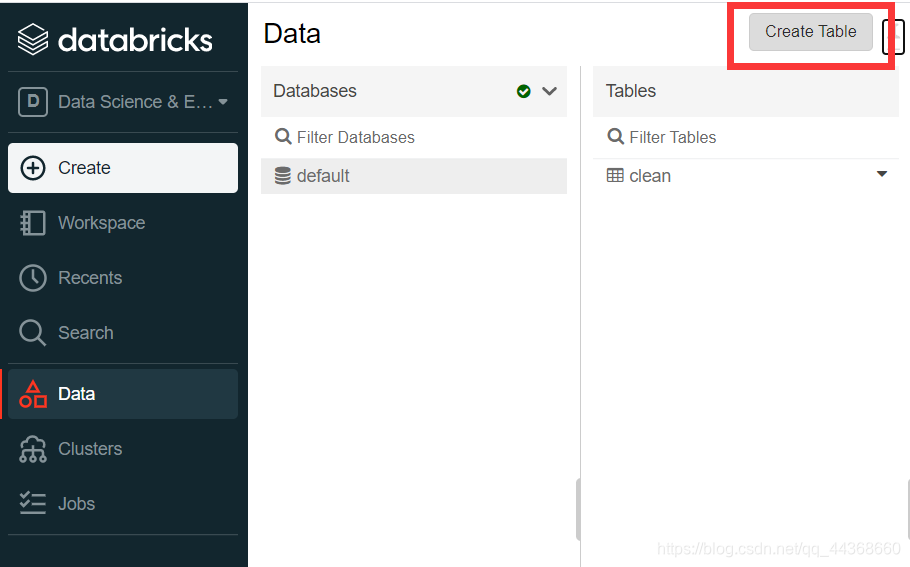
选择创建一个新的数据表
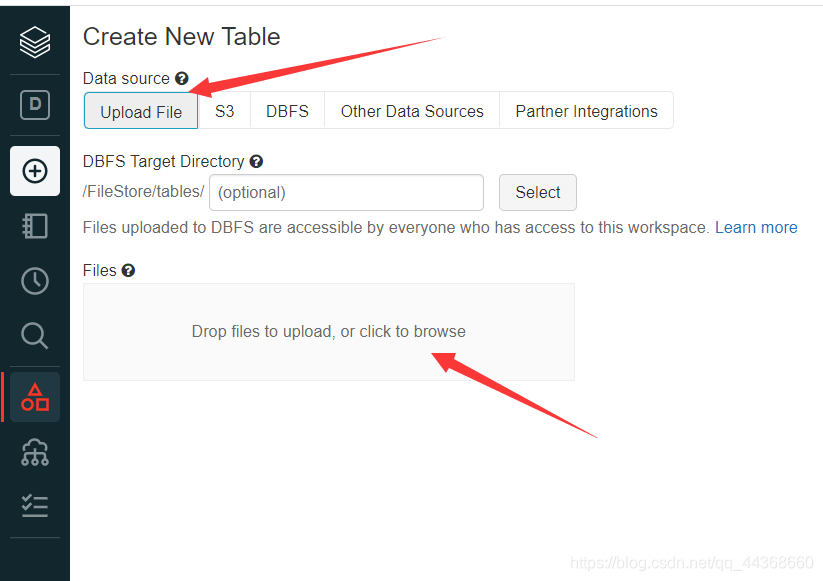
选择upload file,然后上传本地的csv文件
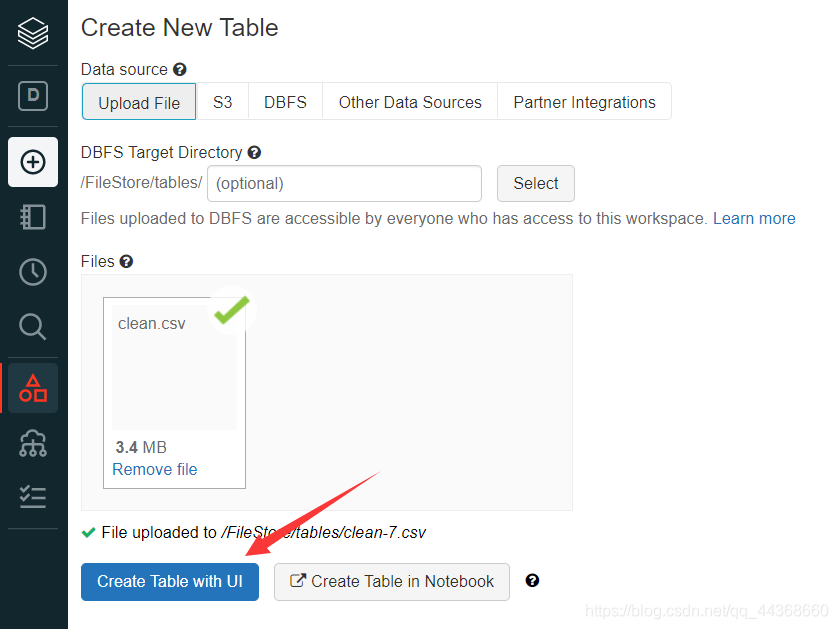
上传完成后,选择通过ui创建数据表
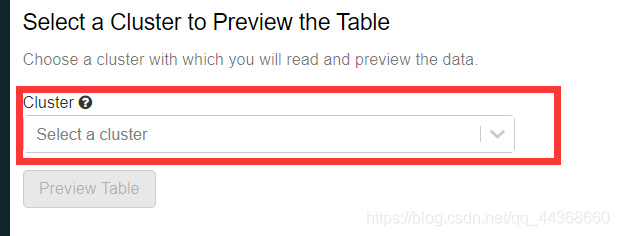
选择你之前创建的cluster,然后preview table,就可以预览你创建的数据表,最后点击创建即可。创建完成后可以在data中查看你现有的数据表
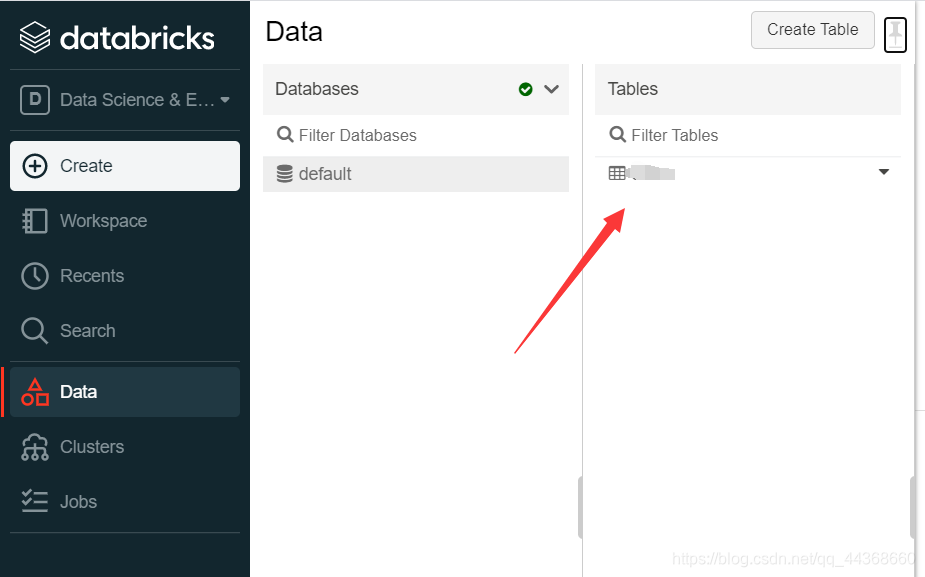
回到notebook中,将table中数据读取进来
可以看到这个数据共有23432条,读取成功。
数据子集的筛选
基于多个条件,可以创建数据的子集 我们可以选择几行、几列、符合某些过滤条件的数据或数据的指定的位置。
select
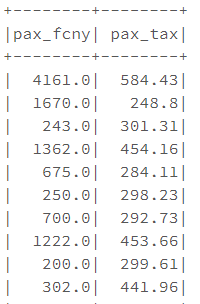
通过select传入列名,选取某些列的数据
df.select(['pax_fcny','pax_tax']).show()
filter
df.filter(df['pax_fcny']>10000).count()
Out[32]: 1656
多个过滤器叠加:
df.filter(df['pax_fcny']>10000).filter(df['pax_tax']>10000).count()
Out[34]: 1471
where
df. where((df['pax_fcny']>10000)&(df['pax_tax']>10000)).count()
Out[35]: 1471
与上述多个过滤器叠加效果一致
数据聚合(Aggregations)
任何一种类型的聚合都可以简单地分为三个阶段
- split
- apply
- combine
第一步是根据其中的一列或一组数据来分割数据,然后对这些小的个体执行操作(计数、最大值、平均值等)。最后一步是把所有这些结果结合起来。
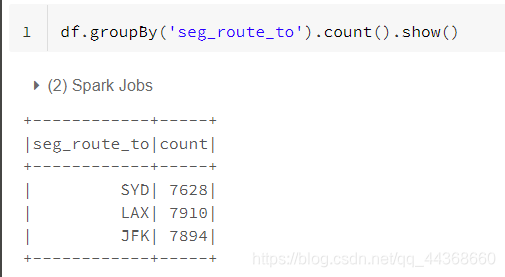
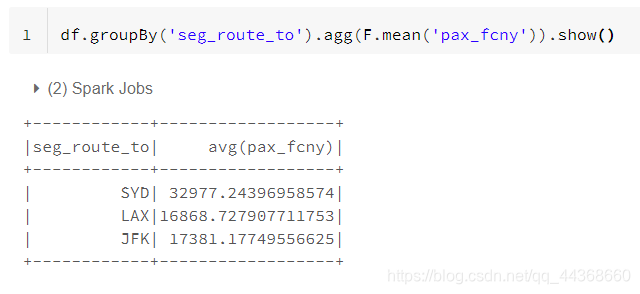
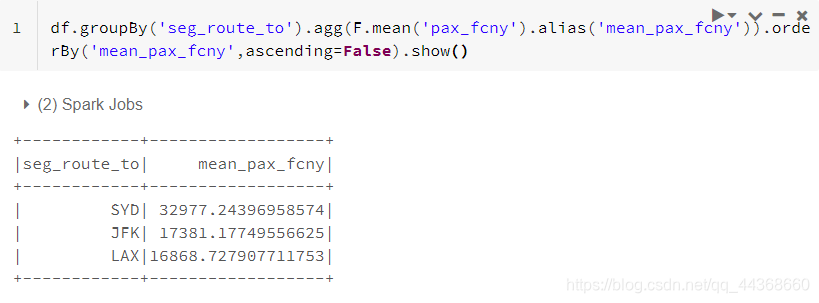
个人觉得,这一部分的知识在关系型数据库中着重体现,不太清楚的读者可以自行去了解学习一下数据库中的数据聚合。
收集collect
收集列表提供了以原始发生顺序排列的所有值 ,并且收集集合只提供唯一的值

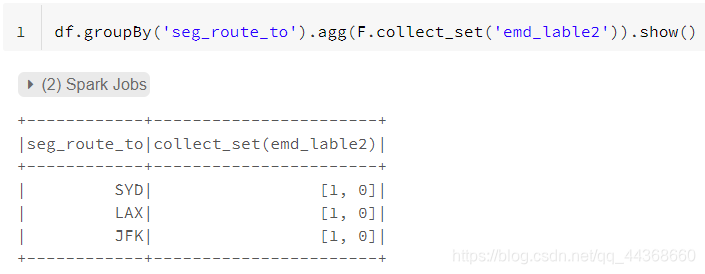
可以方便观察每个分组中collect_list列的数据分布情况
用户自定义函数(UDFs)
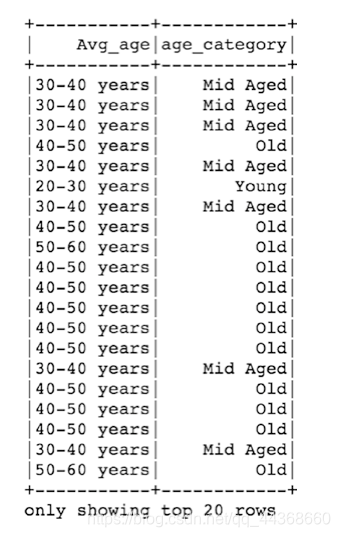
在示例中,我们试图命名年龄类别,并创建一个Python函数(年龄类别)。为了运行这在Spark数据框架上,我们使用这个Python函数创建了一个UDF对象。唯一的要求是函数的返回类型。在这种情况下,它只是一个字符串值。

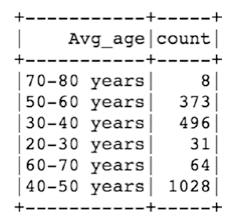


pandas UDF
我们熟知的pandas UDFs与上述提到的用户自定义函数相比处理和效率更快 。主要的区别 在普通的Python UDF和PandasUDF之间,PythonUDF是 逐行执行,pandas UDF是逐块执行它,并提供更快的结果。
有三个不同类型的pandas UDF:标量、分组映射和分组agg。与传统的UDF相比,使用pandas UDF的唯一区别在于声明中。

数据连接(joins)
region_data = spark.createDataFrame([('Family with grown ups','PN'),('Driven Growers','GJ'),('Conservative families','DD'),('Cruising Seniors','DL'),('Average Family ','MN'),('Living well','KA'),('Successful hedonists','JH'),('Retired and Religious','AX'),('Career Loners','HY'),('Farmers','JH')],schema=StructType().add("Customer_main_type","string").add("Region Code","string"))
region_data.show()

new_df=df.join(region_data,on='Customer_main_type')
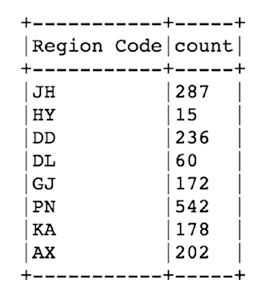
new_df.groupby("Region Code").count().show()
总结
数据处理非常重要,甚至占据了一个项目的大半时间,对后续使用MLlib时起到较为关键的作用。数据决定了项目的上限,而模型只是去无限逼近那个上限。















 9719
9719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











