






数据挖掘导论1
1.概述
1.1数据挖掘的功能
- 特征化和区分
数据特征化:经常购买某类商品的用户特征
数据区分:干燥和潮湿地区的特征比较
-
频繁模式和关联(相关和因果关系)
-
用于预测的分类和回归
-
聚类分析(对数据分组形成新的类)
-
离群点分析
-
趋势和演变分析
1.2 数据挖掘的主要问题
- 挖掘方法和用户交互
- 有效性和可伸缩性
- 数据类型的多样性
- 数据安全,隐私的保护
2.数据预处理
2.1认识数据
-
数据对象,即所代表的实体
-
属性:描述对象的特征
-
属性类型
标称属性:类别,名称,如头发颜色 二元属性:只有两个状态的标称属性 序数属性:排名,年级 数值属性:可度量和计算 -
数据的基本统计描述
-
度量数据的中心趋势 1.平均值 2.中位数 3.众数 -
数据倾斜

- 度量数据离散度
极差:最大值与最小值之差
百分位数:第k个百分位数
四分位数:Q1(百分位25),Q3(百分位75)
中间四分位数极差(IQR):Q3-Q1
孤立点:至少高于Q3或低于Q1的1.5*IQR值
方差和标准差
- 箱型图

2.2数据预处理
- 数据清理的功能
填写缺失的值
识别离群点和平滑噪声数据
纠正不一致的数据
解决数据集成造成的冗余
-
例子:用分箱光滑噪声数据

-
数据清理的过程
1 偏差检测
2 数据变换(纠正偏差)
3 数据变换和偏差检测的迭代执行
- 数据集成:将多个数据源中的数据整合到一个一致的存储当中
- 处理数据集成中的冗杂数据
- 数据规约,常用的为数据压缩,直方图,回归模型,抽样
- 数据变换
离散化:区间的标号代替实际的数据值
概念分层:用高层概念(青年,中年,老年)代替底层的属性值(实际的年龄数据)

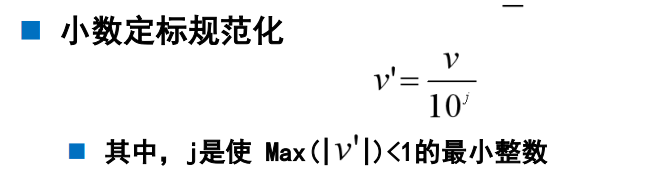
## 3.数据仓库
3.1数据仓库
- 数据仓库有很多定义,但却很难有一种严格的定义
- 区别于其他数据存储系统
- 数据仓库是一个面向主题,集成的,随时间变化的,不统一丢失的数据集合,支持管理部门的决策过程
- 数据仓库是一个数据库
数据仓库关键特征一:面向主题
数据仓库关键特征二:数据集成(通过多个异种数据源构造)
集成方法:查询驱动(对于频繁的查询开销很大),更新驱动(高性能)
数据仓库关键特征三:历史信息
其时间范围比操作数据库系统长很多
数据仓库关键特征四:数据不易丢失
-
操作数据库系统的主要任务是联机事务处理OLTP----面向顾客,且为当前详细的数据
-
数据仓库的主要任务是联机分析处理OLAP----面向市场,且为历史汇总的数据
-
OLAP只读,访问数据量大
3.2多维数据模型
- 数据仓库和OLAP工具基于多维数据模型
- 数据以数据立方体的形式存在




- 多维数据模型上的OLAP操作
上卷:汇总数据
下卷:上卷的逆操作
切片和切块:通过对维度进行选择定义子立方体
转轴:可视化操作,可以理解为对立方体进行转动

3.3数据仓库的设计与使用
- 设计过程

- 应用

4.关联规则挖掘
4.1关联规则
- 用于从大量数据中挖掘出有价值的数据项之间的关系,在电子商务,推荐系统得到广泛应用


- 关联规则的度量

- 频繁项集
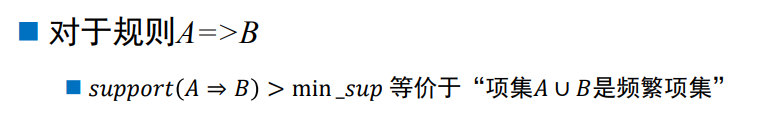
- 关联规则挖掘的两步过程
1 找出所有频繁项集
2 由频繁项集产生强关联规则
4.2频繁项集挖掘
- Apriori算法
Apriori算法由连接和剪枝两个步骤组成


- Apriori算法实例




4.3规则评估方法
-
客观度量:支持度,置信度
-
主观度量:强关联规则是否是有趣的
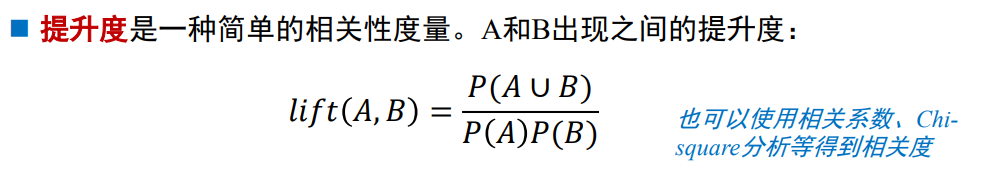
















 4490
4490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









