







堆分配机制
前面提到过格式化字符串漏洞和栈缓冲区溢出漏洞。不过它们的危害都主要在栈区,而C语言的输入变量除了可能在栈区还有可能出现在堆区。堆区也有堆区难念的经。
什么是堆
- 在程序运行过程中,堆可以提供动态分配的内存,允许程序申请大小未知的内存。与之对应的是栈,比如申请数组空间,
int a[10];就是在栈上申请10个单位内存,但是必须在编译之前就确定数组大小,而int *p = (int*)malloc(n*sizeof(int));允许在编译之前不确定n大小的情况下动态确定数组大小。 - 堆其实就是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长。与栈相反。
- 堆管理器处于用户程序与内核中间,主要的工作是
malloc和free。
想要学习堆漏洞就离不开对堆内存分配机制的理解。而windows和linux的堆内存分配机制稍有不同,比如这篇。这里主要先谈下而linux下的堆分配,而linux下malloc主要是glibc的malloc。这篇understanding-glibc-malloc写的比较详细。
这里也不过多讨论详细的机制,主要关注malloc和free函数。
这里涉及到3个概念,arena,bin,chunk,详细参考:理解glibc的malloc
- arena:通过
sbrk或mmap系统调用为线程分配的堆区,按线程的类型可以分为2类- main arena:主线程建立的arena
- thread arena:子线程建立的arena
- bin:一个用以保存free chunk链表的表头信息的指针数组,按所悬挂链表的类型可以分为4类
- fast bin
- unsorted bin
- small bins(加s是因为不止一个链表)
- large bins(加s是因为不止一个链表)
- chunk(last remainder chunk用的少)
- allocated chunk:即分配给用户使用且未释放的内存块
- free chunk:即用户已经释放的内存块
- top chunk
- last remainder chunk(用的少,不讨论了)
这里arena的等级大于bin的等级大于(free)chunk的等级。
一个线程可以包含多个堆段,这些堆段同属于一个舞台来管理。一个堆段用_heap_info结构体表示
typedef struct _heap_info
{
mstate ar_ptr; /* Arena for this heap. 此堆段归属于哪一个arnea管理。*/
struct _heap_info *prev; /* Previous heap. 前一个堆段*/
size_t size; /* Current size in bytes. */
size_t mprotect_size; /* Size in bytes that has been mprotected
PROT_READ|PROT_WRITE. */
/* Make sure the following data is properly aligned, particularly
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
MALLOC_ALIGNMENT. */
char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK];
} heap_info;
一.chunk
堆内存分配以chunk(堆块)为基本单位,切分配的内存多余需求的。比如malloc(10);肯定不止分配10字节chunk。
chunk的数据结构定义如下:
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; // Size of previous chunk (if free)
INTERNAL_SIZE_T size; //size in bytes, including overhead
struct malloc_chunk* fd; // double links -- used only if free
struct malloc_chunk* bk;
// only used for large blocks: pointer to next larger size.也就是下面2个不一定出现
struct malloc_chunk* fd_nextsize; // double links -- used only if free
struct malloc_chunk* bk_nextsize;
};
这里每一项
prev_size:如果前一个chunk是空闲块,该域表示前一chunk的大小。否则,无意义。size:当前chunk大小,并包括N,M,P 3种属性,下面会讲。fd和bk:这2项只当该chunk空闲才有意义,作用是将相应的chunk加入到空闲chunk列表中。而当chunk被分配(malloc)时这2项不存在,会当作数据区使用而不至于浪费。fd_nextsize和bk_nextsize:当该chunk处于large bin时有意义,large bin中的chunk按照大小排序,但同一大小chunk可能有多个,增加这2字段可以加快遍历large bin。fd_nextsize指向下一个比当前chunk大的第一个空闲chunk,bk_nextsize指向前一个比当前chunk小的第一个空闲chunk。而未被使用时,这2项会跟数据区一起使用而不至于浪费。

在chunk中
- P为前一堆块占用标志(空闲0,使用1)。主要用来判断free时是否能与上一块进行合并。不过fastbin属于例外,通常,fast bin为了满足快速分配小内存的需求,一直保持P=1,不参与合并。
- M表示该chunk是否由
mmap分配,0表示由堆块中的top chunk分裂产生,1表示由mmap分配。 - N表示是否属于主线程(arena),0表示属于主线程堆块,1表示属于子线程。
如果前一个堆块是被释放的,那么当前堆块P=0,左上角的表项为prev_size。如果被使用,那么P=1,左上角为pre_data。
这里盗用一个图来说明一下一个堆段中堆内存的分配机制,大致就是从低地址往高地址分配。
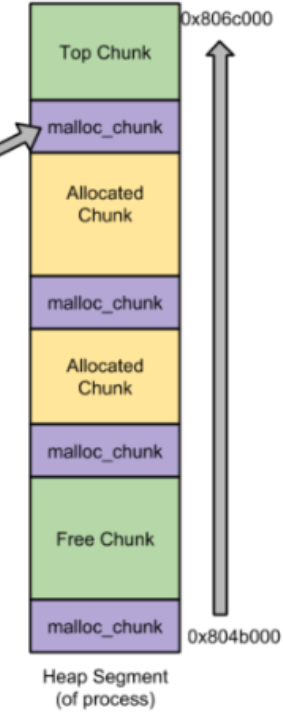
1.1 allocated chunk
表示被分配使用的chunk
当前堆块结构如下,对于allocated chunk不存在fd和bk。所以size域后面就是cur_data(该chunk的用户数据),甚至下一个chunk的pre_size域都用来存放该chunk的数据。

其下一个chunk表头如下:

cur_data是当前chunk的数据而不是下一个chunk的,size是下一个chunk的size。下一个chunk P=1。
chunk的大小是需要对齐的,规则如下
- 32位系统,按8字节对齐,chunk最小16字节(0x10)。
- 64位系统,按16字节(0x10)对齐,chunk最小32字节(0x20)。
用malloc申请内存时。64位系统中,chunk size在0x69-0x78之间都会对齐到0x80。
1.2 free chunk
属于空闲的堆块
这里
fd指向bin(空闲列表)中下一个空闲chunkbk指向bin(空闲列表)中前一个空闲chunk- 数据区未被使用所以为no_use

下一个chunk头信息如下
 这里下一个chunk P通常会置0,但是在fast bin中永远为1。
这里下一个chunk P通常会置0,但是在fast bin中永远为1。
1.3 top chunk
属于空闲块,该块位于前两种块之后,头结构与allocated类似,主要是pre_size和size域。
当一个chunk处于一个arena的最顶部(即最高内存地址处)的时候,就称之为top chunk。
该chunk并不属于任何bin,而是在系统当前的所有free chunk(无论哪种bin)都无法满足用户请求的内存大小的时候,将此chunk当做一个应急消防员,分配给用户使用,一般不会用。至于怎么分配,这里不讨论了。
二.bin
allocated chunk被释放后,会放入bin或者合并到top chunk中去。bin是一个由chunk结构体组成的链表。bin的主要作用是加快分配速度,其通过链表方式(chunk结构体中的fd和bk指针)进行管理。
一个bin即一个链表,一个线程有很多bin链。这些bin链由arena所表示的malloc_state结构体管理。
内存分配的最终目的在于分配出合适大小的内存块返回给用户。在实现中即为在bin或top chunk中找到(并分割出)所需内存块,其检索的优先级从高到低分别是:
- fast bin
- small bin
- unsorted bin
- large bin
- top chunk
fast bin、small bin、unsorted bin和 large bin中保存的都是用户曾经释放的内存块(可能经过合并)
2.1 fast bin
fast bin中包含一维指针数组头,用于管理小堆块。64位系统中,保存0x20-0x80之间的,32位系统中,其大小区间为0x10-0x40(0x10和0x40算在内)。fast bin采用单链表结构组织,用fd指向下一堆块,采用LIFO机制(Last In First Out),后free的chunk会被添加到先free的chunk的后面;同理,通过malloc取出chunk时是先去取最新放进去的,因此,bk域是没有用到的。fast bin中,堆块的P值一直为1,防止合并,用于快速分配小内存。一般fast bin中有10条bin链。
2.2 其它bin
其它bin包含一维指针数组头,采用双链表结构进行组织以及FIFO机制(First In First Out)
其中
- small bins主要保存0x10-0x400(64位是0x20-0x800)区段的chunk,包括bin2-bin63(62个链表)。同一个链表下的堆块大小相同,如32位下bin2对应0x10,bin3对应0x18…(对齐过的)。
- unsorted bin存放刚释放的堆块以及大堆块分配后剩余的堆块,大小没有限制。为bin1
- large bins,包括bin64-bin126。主要用来存放大于0x400(64位是0x800)的堆块,同一个链表堆块大小不一定相同,在一定范围内,按从小到大顺序排序。
三.Arena
一个线程申请的1/多个堆包含很多的信息:二进制位信息,多个malloc_chunk信息等这些堆需要东西来进行管理,那么Arena就是来管理线程中的这些堆的。
- 一个线程只有一个arnea,并且这些线程的arnea都是独立的不是相同的。
- 主线程的arnea称为“main_arena”。子线程的arnea称为“thread_arena”。
- 每个程序中arnea的数量是有限制的,因为过多的线程也不会产生过多的arnea,线程太多,有的arena得共享,数量由以下规则制定的:
- 32位系统中:Number of arena = 2 * number of cores + 1
- 64位系统中:Number of arena = 8 * number of cores + 1
而一个arena由malloc_state结构体实现
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
可以看到一个arena包含很多信息,包括各种bins的信息,top chunk以及最后一个剩余chunk等。其中
fastbinsY数组存储的是该领域管理的fast bins。bins数组存储的是该arena管理的small bins,unsorted bin,large bins。binmap,系统查看有哪些垃圾箱链中有块时,不可能去fastbinsY和箱数组一个一个的遍历。通过binmap变量,采用二进制存储,将二进制位与数组的索引相对,系统查找箱链时可以。通过按位与来查询,这样更高效。虽然unsigned int的二进制位比数组总元素少,但是系统不会有那么多的bin链,不需要考虑这个问题。
四.malloc基本规则
malloc函数返回对应大小字节的内存块的指针。此外,还提供异常管理机制,比如malloc(0);返回当前系统允许的堆的最小内存块。若malloc(-n);,由于在大多数系统中,size_t是无符号数,所以程序就会申请很大的内存空间,但通常来说都会失败,因为系统没有那么多的内存可以分配。
malloc主要对照_int_malloc函数查看,这函数非常长,可以参考这篇大佬的文章。这里只讨论基本情况,最开始glibc所管理的内存空间是brk系统调用产生的,如果malloc太大,超出了现有空闲内存,则会调用brk或mmap继续产生内存。
对于malloc申请一般大小(不会超出现有空闲大小)的内存,简化版流程如下
- size按照一定规则对齐。得到最终分配到的大小
size_real(先看看要分配多大的内存)。- 32位:size+4按照0x10对齐
- 64位:size+8按照0x20对齐
- 检查
size_real是否符合fast bin的大小,若是则查看fast bin中对应size_real那条链表中是否存在堆块,有的话分配返回,否则进入下一步。 - 检查
size_real是否符合small bin的大小,若是则查看small bin中对应size_real那条链表中是否存在堆块,有的话分配返回,否则进入下一步。 - 检查
size_real是否符合large bin的大小,若是调用malloc_consolidate函数对fast bin中所有的堆块进行合并,过程是将fast bin中的堆块取出,清除下一块的P标志并进行合并,合并完放入unsorted bin。然后在small bins和large bins中找到适合size_real大小的块,找到即分配,并将多余部分放入unsorted bin,找不到进入下一步。 - 检查top chunk的大小是否符合
size_real的大小,若是则分配前面一部分,并重新设置top chunk,否则调用malloc_consolidate对fast bin中所有堆块进行合并,并将最终堆块放入unsorted bin,若依然不够,借助系统调用开辟新空间分配,若还是无法满足,则在最后返回失败。
五.free的基本原则
void free(void *p);会释放由p所指向的内存块。这个内存块有可能是通过malloc函数得到的,也有可能是通过相关的函数realloc得到的。
该函数还对异常情况进行了一下处理:
- 当
p为空指针时,函数不执行任何操作。 - 当
p已经被释放之后,再次释放会出现错误的效果,这其实就是double free。 - 除了被禁用(
mallocpt)的情况下,当释放很大的内存空间时,程序会将这些内存空间还给系统,以便减小程序所使用的内存空间。
free函数的源码分析主要参考__libc_free和_int_free()。源码篇幅太大,可以参考大佬的文章。
步骤如下:
free时首先会检查地址是否对齐,并根据size找到下一块的位置,检查其P标志是否为1。- 检查释放块的
size是否符合fast bin的大小区间,若是放入fast bin,并保持下一个堆块中的P标志为1不变(避免堆块合并)。否则进入下一步。 - 若本块的
size域中P=0(前一块处于释放状态),则利用本块的pre_size找到前一堆块的开头,将其冲bin链中unlink,合并这2块,得到新的释放块。 - 根据
size找到下一堆块,如果是top chunk,则直接合并到top chunk中,直接返回。否则检查后一堆块是否处于释放态(检查下下块的P标志是否为0),若是,则unlink掉,合并得到新的堆块。 - 将合并得到的最终chunk放到unsorted bin中去。
六.tcache
glibc 2.26之后引入tcache,管理方式类似于fast bins。
tcache涉及到2个重要的结构体tcache_entry和tcache_pertheread_struct,定义如下
typedef struct tcache_entry{
struct tcache_entry *next;
} tcache_entry;
typedef struct tcache_pertheread_struct{
char counts[TCACHE_MAX_BINS];
tcache_entry* entries[TCACHE_MAX_BINS];
} tcache_pertheread_struct;
初始化管理指针:
struct __thread tcache_pertheread_struct *tcache = NULL;
TCACHE_MAX_BINS值为64,堆空间起始部分都会有一块先于用户申请分配的堆空间,大小0x250(592)。
- 总共64个bin链,每个链最多7个chunk,64位系统从0x18-0x408,以0x10递增,32位系统从0xC-0X200,以0x8递增。
- 其缓存的是非large chunk的chunk。
- 只有tcache满了之后,chunk才会被放入其它链表,进行
malloc时,tcache的首先被分配。也就是tcache优先级高于fast bin。 - tcache某条bin链被占满后,之后
freechunk时,该chunk原来该放哪就放哪(fast bin或者small bin或者…)。















 1506
1506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









