









VulDeeLocator: A Deep Learning-based Fine-grained Vulnerability Detector
一.背景
自动检测软件漏洞在学术界引起了广泛关注。但现有的检测器依旧有许多不足。静态检测(static analysis)是一种流行的检测方式。这种检测方式可以分为
- 代码相似度匹配(code similarity-based):VUDDY,ReDeBug,VulPecker属于这一类。这一类可以检测由代码克隆引起的bug。但是导致了高假阴性率(high false-negatives),检出能力差。
- 模式匹配(pattern-based):这一类又可进一步分为
- 规则匹配(rule-based):Flawfinder,Checkmarx,Fortify,Coverity,MLSA等。这类方法需要专家定义漏洞规则,在能检测到漏洞时能定位到行。但是误报率,漏报率高。
- 基于ML的(machine learning-based):Chucky,Devign,VulDeepecker,SySeVR等。这些方法通过ML trick来对人工定义的代码特征表示(feature representation)进行学习。缺点是检测粒度过粗,不能定位到行。
同时,作者在观察SySeVR的效果时,尽管它在合成和半合成的数据集 (SARD,NVD)上取得比较好的效果,但在真实数据集上效果较差。这可能归因于:
- 方法不能捕获不同文件(file)的statement之间的语义关系。
- 不能捕获精准的控制流和变量定义调用(define-use)关系。
其中
- 第一点非常重要因为程序经常在头文件(.h)中定义许多宏定义(macro)和自定义变量类型(type)。这一点仅仅单独分析源文件是做不到的,需要跨文件依赖分析,这点到现在依然不明确。
- 第二点也不能仅通过分析源代码实现。这不能很好的识别程序中精准的控制流和变量定义-调用关系。而每个变量不仅仅会只被赋值一次。
鉴于以上2点,基于源代码的表示(source code-based representations)不能包含足够的语义信息。
作者的contribution 在于提出了针对C程序的新的漏洞检测器VulDeeLocator(全称Vulnerability Deep learning-based Locator)。与state-of-art方法相比性能更好(F1等指标),VulDeeLocator的创新性体现在3方面
- 确定了现有检测方法性能不佳的一个根源(不能跨文件,控制流不精准),解决办法是将(同一工程下)多个文件通过define-use关系链接起来,并用中间代码表示(Intermediate code-based representations)替代源代码。中间代码是SSA(Static Single Assignment)形式的。
- 作者提出了granularity refinement这个概念来定位代码漏洞行。具体来说就是提出了BRNN-vdl(全称Bidirectional Recurrent Neural Network (BRNN) for vulnerability detection and locating)。这个方法也许不是最优的,但是可以对于输入有32行的代码片段输出与漏洞有关的3行代码。
- 作者准备了一个新的数据集,每个样例都由LLVM中间代码和源代码构成,数据集总共157692个样本,40450个有漏洞,117242个没有漏洞。作者将它们的数据集和实验相关的代码开源到VulDeeLocator。
二.基本思想
大致流程如下图所示,其中用到了slice技术(跟SySeVR差不多)

给定一系列vulnerability syntax characteristic(SySeVR中slice的起始点),先从程序中slice出一些statement(表示为tokens of interest),之后将这些statement表示为中间代码形式,之后就是通过神经网络输出漏洞行(不再是二分类了,输出的是漏洞行代码)。
下图展现了一个缓冲区下溢出漏洞,这个漏洞很多检测器检测不出来因为不能很好的获取第14行代码中N<m ? N : 99中的控制流信息。
- 与直接
if条件比较N和m的值相比,三目运算符的控制流比较隐晦。 - 宏定义的
N值为100。

所以VulDeeLocator会将memset(dataBuffer,’A’, N<m?N:99);这一行代码解析为4行中间代码(6-9行)。会出现比较N和m的分支,以及N的值被解析为100。之后,VulDeeLocator会利用BRNN-vdl来指出第25行会触发漏洞。

三.VulDeeLocator概述
从直观上看程序漏洞会表现出一些语法特征(syntax characteristics,比如数组定义,指针定义,函数调用,这些语法特征可以用来筛选出一些代码片段(比如program slice)来作为漏洞检测的对象。漏洞语法特征通常表现在一些数据结构(AST)中,可以根据语法特征提取代码片段(slice),代码片段作为漏洞检测的起始点。
- 定义1,sSyVC:给定程序 P P P(可能由多个文件组成)以及语法特征集合 H = { h 1 , . . . , h η } H = \{h_1,...,h_\eta\} H={h1,...,hη}。一个sSyVC y i y_i yi 是 P P P 中一个或多个连续的token(identifiers, operators, constants, keywords等) 。 y i y_i yi 能够匹配到 H H H 中的某些语法特征。
- 定义2,iSeVC:给定程序 P P P(可能由多个文件组成)其中间代码为 P ′ P^{'} P′,以及一个sSyVC y i y_i yi。 y i ′ y_i^{'} yi′ 是 y i y_i yi 的中间代码表示形式。 y i y_i yi 的iSeVC表示为 e i e_i ei。 e i e_i ei 由 P ′ P^{'} P′ 中一系列的statement构成。这些statement与 y i ′ y_i^{'} yi′ 存在数据或控制依赖。也就是从sSyVC获得iSeVC需要在中间代码上做slice,slice的起始点是 y i ′ y_i^{'} yi′。
VulDeeLocator的框架如下图所示,输入是目标程序的C语言代码,代码应满足:
- 代码可编译成中间代码,比如LLVM IR。
- 有漏洞的程序应该有标注到哪一行有漏洞。

四.基于中间代码的表示
4.1. 漏洞candidate表示的指导原则
直观上来看漏洞检测器应该考虑到程序的语义信息,这强调了确定有效的漏洞candidate表示的重要性。为此,作者提出以下原则:
- 原则1,考虑跨文件语义相关的statement:有些文件可能依赖于其它文件,因为这些文件引用了在其它文件定义的变量。有效的candidate表示应该考虑到这个define-use关系。
- 原则2,考虑跨函数语义相关的statement:语义相关的statement可能会超出函数的边界。
4.2.提取sSyVCs
语法SyVC是满足一些漏洞语法特征的代码片段,获取漏洞语法特征的方式有很多种。作者利用已知漏洞的语法特征并将这些特征通过AST表示出来,这会让sSyVC的提取变得容易,作者定义了4种漏洞语法特征。
- Library/API Function Call (FC):这种特征表现在AST上其中一个结点的type为函数调用(function call),子结点function name能够匹配上Library/API function name。并且函数调用的参数中至少一个是变量。
- Array Definition (AD): 这种特征表现在AST上有一个结点的type为变量定义(variable declaration),并且该结点对应的代码包含字符
[和]。 - Pointer Definition (PD): 这种特征表现在AST上有一个结点的type为变量定义(variable declaration),并且该结点对应的代码包含字符
*。 - Arithmetic Expression (AE): 这种特征表现在AST上有一个结点type为赋值操作(assignment expression),以及在赋值操作结点的右子树上至少有一个变量结点。
给定程序的源代码,通过生成AST,遍历AST获得sSyVCs。下图展示了一个程序中的sSyVCs (红框表示)。

- FC类型(函数调用)包括
printf(第6行),memset(14, 23),memmove(25)。 - AD类型(数组定义)包括
dataBuffer(10),source(11)。 - PD类型(指针定义)包括
data(2)。 - AE类型(算术运算)包括
data=dataBuffer-8(19)。
可以看出sSyVc生成仅仅在源代码层面,不涉及到中间代码。
4.3.生成iSeVCs
生成iSeVCs包含3步:
- 生成链接好的中间表示(IR)文件
- 生成对应sSyVCs的中间表示slice
- 生成iSeVCs
下面算法描述了这一过程

4.3.1.生成链接好的中间文件(原则1)
- 使用编译器(clang)对程序中的每个源文件生成一个中间表示文件
- 根据它们的依赖关系链接这些中间表示文件
4.3.2.生成对应sSyVCs的中间表示slice并进一步生成iSeVCs(原则2)
- 从生成的中间表示文件中提取控制和数据依赖图。
- 根据sSyVC对依赖图进行slice,这一步可用DG完成。中间代码中每个局部变量都会用
%加一个数字表示。
给定中间表示的slices(复数),生成iSeVcs的过程如下:
- 对于函数 f α f_\alpha fα 调用函数 f γ f_\gamma fγ 的情况。 f γ f_\gamma fγ 的slice的statements会被添加到 f α f_\alpha fα 调用 f γ f_\gamma fγ 的这个statement的末尾。这保存了statement的执行顺序。
- 如果存在调用嵌套的情况( f α f_\alpha fα 调用 f γ f_\gamma fγ, f γ f_\gamma fγ 再调用 f α f_\alpha fα)。那么作者只考虑( f α f_\alpha fα -> f γ f_\gamma fγ -> f α f_\alpha fα)一层循环,这样避免无限嵌套。
- 在跨函数的slice中,作者对局部变量也进行了重新赋值操作,一般在一个函数内部,局部变量会从
%1开始分配名字,但是为了避免同一个局部变量名出现在同一个slice中多次。作者对变量名进行了再分配。比如下图中d部分,printLine函数的中间表示局部变量名从%20开始,因为main函数最后一个变量名是%19。
从源代码到iSeVC的过程可如下图描述

五.细粒度的漏洞检测
5.1.细粒度检测器的必要条件
作者认为意在检测和定位漏洞的神经网络模型必须具备3个条件
- 粒度细化(Granularity refinement):代码的粒度决定了分析源代码的基本单元(unit),可以从最粗的粒度到文件(file),函数(function),代码片段(code fragment),语句(statement),以及最细粒度的token层面。输入检测模型的是iSeVc,这是code fragment层面的(包括多个层面)。而输出的粒度必须比输入更细。
- 容易映射(Easy Mapping):将神经网络模型的输出映射到iSeVC须容易进行,这样方便定位漏洞。输出应该是一个token序列,其中1个或多个连续的token对应同1行中间代码(IR)。这些中间代码行能轻松映射回iSeVC,进而映射到源代码中的漏洞行。
- 采用Attention机制(Attention taking):attention机制来源于深度学习,意在获取输入中的重要部分,很多情况下,在一个有漏洞的iSeVC中,只有1个或少数的statement有漏洞。这就意味着这些漏洞行比非漏洞行更重要。因此,在attention矩阵中应该被赋予更高的权重。
5.2.标注iSeVCs
标注iSeVC和之前标注slice(code gadget,SeVC)有些不同,之前的slice只要包含漏洞行就标注为1,否则0。因为之前做的都是二分类工作,在这:
- 如果1个iSeVC包含已知漏洞,那么标注它为漏洞行序列 [ x 1 , . . . , x ζ ] [x_1, ..., x_\zeta] [x1,...,xζ](这里的理解可能有误,欢迎大佬指正),其中 x i x_i xi 为1个行号。
- 否则标注为0
比如对于下面漏洞数据
45 000/071/269/api/CWE122_Heap_Based_Buffer_Overflow__c_CWE805_char_memcpy_06_2_*data&&1.final.ll
define i32 @main(i32, i8**) #0 {
call void @CWE122_Heap_Based_Buffer_Overflow__c_CWE805_char_memcpy_06_bad()
define void @CWE122_Heap_Based_Buffer_Overflow__c_CWE805_char_memcpy_06_bad() #0 {
%2 = alloca i8*, align 8
%3 = alloca [100 x i8], align 16
store i8* %4, i8** %2, align 8
%5 = load i8*, i8** %2, align 8
%6 = getelementptr inbounds i8, i8* %5, i64 0
store i8 0, i8* %6, align 1
%7 = getelementptr inbounds [100 x i8], [100 x i8]* %3, i32 0, i32 0
call void @llvm.memset.p0i8.i64(i8* %7, i8 67, i64 99, i32 16, i1 false)
%8 = getelementptr inbounds [100 x i8], [100 x i8]* %3, i64 0, i64 99
store i8 0, i8* %8, align 1
%9 = load i8*, i8** %2, align
%10 = getelementptr inbounds [100 x i8], [100 x i8]* %3, i32 0, i32
call void @llvm.memcpy.p0i8.p0i8.i64(i8* %10, i8* %10, i64 100, i32 1, i1 false
%11 = load i8*, i8** %2, align 8
%12 = getelementptr inbounds i8, i8* %11, i64 99
store i8 0, i8* %12, align 1
%13 = load i8*, i8** %2, align 8
%14 = load i8*, i8** %2, align 8
%15 = load i8*, i8** %2, align 8
}
}
[15, 16, 17]
大概意思就是中间代码(这里是个人理解)的第15,16,17行存在漏洞,可以看到这里调用了memcpy函数,可能触发漏洞。
而这个就是没漏洞的,但0还是写在list里
18783 000/073/796/point/CWE124_Buffer_Underwrite__char_alloca_loop_15_3_*dataBuffer.final.ll
define i32 @main(i32, i8**) #0 {
call void @CWE124_Buffer_Underwrite__char_alloca_loop_15_good()
define void @CWE124_Buffer_Underwrite__char_alloca_loop_15_good() #0 {
call void @goodG2B1()
define internal void @goodG2B1() #0 {
%3 = alloca i8*, align 8
%4 = alloca i8*, align 8
%5 = alloca i64, align 8
%6 = alloca [100 x i8], align 16
%7 = alloca i8, i64 100, align 16
store i8* %7, i8** %4, align 8
%8 = load i8*, i8** %4, align 8
call void @llvm.memset.p0i8.i64(i8* %8, i8 65, i64 99, i32 1, i1 false)
%11 = load i8*, i8** %4, align 8
store i8* %11, i8** %3, align 8
%12 = getelementptr inbounds [100 x i8], [100 x i8]* %6, i32 0, i32 0
call void @llvm.memset.p0i8.i64(i8* %12, i8 67, i64 99, i32 16, i1 false)
%13 = getelementptr inbounds [100 x i8], [100 x i8]* %6, i64 0, i64 99
store i8 0, i8* %13, align 1
store i64 0, i64* %5, align 8
%15 = load i64, i64* %5, align 8
%16 = icmp ult i64 %15, 100
br i1 %16, label %17, label %25
%18 = load i64, i64* %5, align 8
%19 = getelementptr inbounds [100 x i8], [100 x i8]* %6, i64 0, i64 %16
%20 = load i8, i8* %19, align 1
%21 = load i8*, i8** %3, align 8
%22 = load i64, i64* %5, align 8
%23 = getelementptr inbounds i8, i8* %21, i64 %20
store i8 %20, i8* %23, align 1
%25 = load i64, i64* %5, align 8
%26 = add i64 %25, 1
store i64 %26, i64* %5, align 8
%28 = load i8*, i8** %3, align 8
%29 = getelementptr inbounds i8, i8* %28, i64 99
store i8 0, i8* %29, align 1
%30 = load i8*, i8** %3, align 8
%31 = load i8*, i8** %4, align 8
}
}
}
[0]
5.3.训练神经网络模型(训练阶段)
神经网络的输入是iSeVC,在一个iSeVC输入神经网络之前依旧需要符号化处理。之前在VulDeepecker和SySeVR中符号化主要是把用户自定义的函数(比如goodG2B1)转换为FUNC1,FUNC2,以及将用户自定义变量(char *data)转换为VAR1,VAR2(char *VAR1)。这里作者采用的是中间代码,所有的局部变量已经被%1,%2这样的值替代,所以变量不需要符号化。而看上面的样例可知,中间代码中,用户自定义函数名依旧存在,所以需要符号化。
符号化后的iSeVC会以token序列的形式输入神经网络,token会先用word embedding(Word2Vec)向量化,之后输入序列的向量长度(应该是序列长度 * embedding_size)会修正为固定值 θ \theta θ。(token序列长度小于 θ \theta θ 则补0填充,大于则截断(应该是删除后面部分,一定要确保sSyVC出现在iSeVC中))
作者用BiRNN来实现easy mapping,RNN可以输出(下图中Activation layer的输出)输入token序列(长度为 λ \lambda λ)每个token的长度。BRNN-vdl的结构如下图所示

作者将一个iSeVC
e
i
e_i
ei 在Activation layer的输出表述为
A
i
=
(
g
1
(
e
i
)
,
.
.
.
,
g
λ
(
e
i
)
)
A_i = (g_1(e_i), ..., g_\lambda(e_i))
Ai=(g1(ei),...,gλ(ei)),
g
τ
(
e
i
)
g_\tau(e_i)
gτ(ei) 是RNN在
τ
\tau
τ 时刻输出。
之后作者通过Multiply layer实现attention,要求如下:
- 对于有漏洞的iSeVC,multiply layer需要选出对应漏洞行的tokens(连续的token序列,这些token的权重系数会大于其它token)。
- 对于没有漏洞的iSeVC,multiply layer需要选出所有的token(这是所有的token权重应该相似)
具体的运算就是 M i = A i . L i M_i = A_i.L_i Mi=Ai.Li ( M i M_i Mi 是输出, L i L_i Li 是参数,对角矩阵)
对角矩阵 L i L_i Li 生成规则如下(训练阶段):
- 如果iSeVC是无漏洞的,那么 L i L_i Li 就是 λ × λ \lambda \times \lambda λ×λ 的单位矩阵。
- 如果iSeVC是有漏洞的,那么 L i L_i Li 在有漏洞行token的几列值为1,其余为0。详细来说: L i = { α 1 , . . . , α λ } L_i = \{\alpha_1, ..., \alpha_\lambda\} Li={α1,...,αλ}。第一个漏洞行token位置是 x ε ′ x_\varepsilon^{'} xε′,漏洞行总共 ω ε \omega_\varepsilon ωε 个token。那么对于 φ ∈ { x ε ′ , . . . , x ε ′ + ω ε − 1 } \varphi \in \{x_\varepsilon^{'}, ..., x_\varepsilon^{'} + \omega_\varepsilon - 1\} φ∈{xε′,...,xε′+ωε−1}。 α φ = 1 \alpha_\varphi = 1 αφ=1。否则 α φ = 0 \alpha_\varphi = 0 αφ=0。
之后作者通过k-max pooling layer和average pooling layer实现粒度细化,k-max
pooling layer意在选取输出向量
M
i
M_i
Mi 中top k的值。average pooling layer意在计算k个值的平均值。average pooling layer的输出
o
i
=
a
v
g
(
m
a
x
k
(
M
i
)
)
o_i = avg(max_k(M_i))
oi=avg(maxk(Mi))
5.4.检测和定位漏洞(测试阶段)
使用训练好的神经网络模型检测漏洞的流程如下,需要注意的是,在测试阶段BRNN-vdl中已经没有multiply layer了。在检测阶段,作者会对每行的token(应该是记录行的起始和终止token索引)求平均值,大于一个阈值的会作为漏洞行,不然就没有漏洞行。

六.实验部分
作者提出了4个研究问题:
- RQ1:中间代码能用来获取更好的检测效果吗?
- RQ2:BRNN-vdl能比BRNN取得更好的定位效果吗?
- RQ3:VulDeeLocator在检测和定位已知ground truth的情况下能多精准和有效?
- RQ4:VulDeeLocator在真实软件中检测和定位效果如何?
6.1.评估指标
用
- TP表示标注有漏洞检测出有漏洞的样本数量
- FP表示标注无漏洞检测出有漏洞的样本数量
- TN表示标注无漏洞检测无漏洞的样本数量
- FN表示标注有漏洞检测无漏洞的样本数量
作者用5个常用指标评估检测性能:
- FPR(false-positive rate): F P R = F P F P + T N FPR = \frac{FP}{FP+TN} FPR=FP+TNFP
- FNR(false-negative rate): F N R = F N F N + T P FNR = \frac{FN}{FN+TP} FNR=FN+TPFN
- A(accuracy): A = T P + T N T P + F P + T N + F N A = \frac{TP+TN}{TP+FP+TN+FN} A=TP+FP+TN+FNTP+TN
- P(precision): P = T P T P + F P P = \frac{TP}{TP+FP} P=TP+FPTP
- F1: F 1 = 2 ⋅ P ⋅ ( 1 − F N R ) P + ( 1 − F N R ) F1 = \frac{2·P·(1−FNR)}{P+(1−FNR)} F1=P+(1−FNR)2⋅P⋅(1−FNR)
对于漏洞定位性能的评估,作者用IoU(Intersection over Union)来评估:
I
o
U
=
∣
U
∩
V
∣
∣
U
∪
V
∣
IoU = \frac{|U \cap V|}{|U \cup V|}
IoU=∣U∪V∣∣U∩V∣
- U U U 为真实的漏洞行
- V V V 为检测出的漏洞行
拿下面这个例子来说,真实漏洞有4行,检测出3行,其中交叉2行,并集5行,那么
I
o
U
IoU
IoU 的值就是
2
5
\frac{2}{5}
52 。
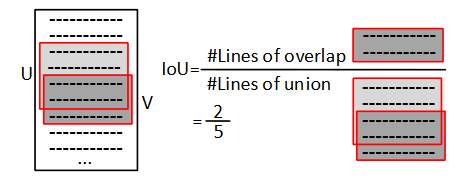
6.2.准备数据集
作者依旧从NVD和SARD上收集C语言的源代码,NVD上的数据集常伴随有diff文件,这描述了带漏洞的文件和修复后的文件之间的区别。SARD上的数据集常标注好了哪一个文件哪一行有漏洞。作者过滤了一些不能被LLVM编译的源文件。
作者总共收集了14511个程序,包括2182个真实环境下的程序和12329个合成和学术研究上的程序。真实环境的程序收集自多个版本的开源C语言程序(Linux kernel, OpenSSL, FFmpeg, Wireshark和Libtiff)。
对于真实环境的程序,作者收集了2017年以前的漏洞程序和它们的修复版本。作者从真实和合成的数据集中随机选取80%作为训练集,合成数据集中剩下的20%作为测试集1(Testset-1),真实数据集中剩下的20%作为测试集2(Testset-2)。作者希望能评估在不同数据来源下实验结果的不同。
6.3.基于中间代码的漏洞candidate
作者通过clang来为C代码生成AST,然后遍历AST生成sSyVCs。生成sSyVCs时用到了checkmarx中的规则,因为这些语法规则对已知漏洞的覆盖率大。包括Library/API Function Call (FC), Array Definition (AD), Pointer Definition
(PD), 和Arithmetic Expression (AE) 4种,这4种语法规则能覆盖NVD和SARD上98.3%的漏洞。这里作者只是用了checkmarx的规则,并没有用它的检测结果作为baseline。
对于FC类型的规则,遍历AST生成sSyVC的规则如下:
- 定位到类型为
CxCursor_CallExpr的AST结点(标识函数调用)。 - 识别出其token可以匹配的上系统函数调用的结点(
memset等,应该是过滤掉一部分非系统函数调用)。 - 遍历系统函数调用的子结点,找出类型为
CxCursor_DeclRefExpr的子结点(变量参数)。 - 系统函数调用和它的变量参数会作为一个sSyVC被提取出来。
提取sSyVC后,就是生成iSeVC了。作者先用DG来从sSyVC提取LLVM中间代码slices。iSeVC则是基于slice生成的slice。
6.4.细粒度的漏洞检测
对于一些超参数,作者设置如下:
| 参数 | 值 |
|---|---|
| word vector size | 30 |
| token序列最大长度 | 900 |
| RNN输出维度 | 512 |
| RNN隐藏层数 | 2 |
| RNN隐层结点数 | 900 |
| batch size | 16 |
| learning rate | 0.002 |
| dropout | 0.4 |
| 训练epoch数 | 10 |
| k-max层的k | 1 |
在检测阶段,作者计算每行代码top k token的平均值,平均值大于0.5的行会被作为漏洞行。
6.5.RQ1的实验
为了评估中间代码表示的优势,作者对比了sSeVC和iSeVC的表示来对比,对于提取sSeVR作者先用Joern提取控制和数据依赖,对于中间代码则用DG。这里用到的模型的BGRU-vdl。
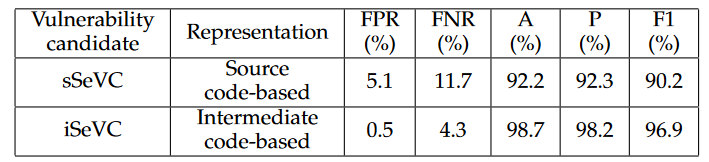
可以看到基于中间表示的优于基于源代码表示的。主要原因是一些跨函数的宏定义和全局变量的信息没有用上。
同时这里作者也对比了进行数据平衡处理和不平衡处理的方法的区别,对比了不平衡,用NearMiss-2平衡和用SMOTE平衡的区别。

6.6.RQ2的实验
作者还对比了BRNN-vdl和BRNN以及不同代码表示情况下定位漏洞行的能力,Test-set1上的结果如下:
 这里基于BRNN的应该是将整个iSeVC作为漏洞行来表示。
这里基于BRNN的应该是将整个iSeVC作为漏洞行来表示。
可以看到iSeVC + BRNN-vdl的组合取得的IoU最高,并且基于BRNN-vdl的 ∣ V ∣ |V| ∣V∣ 大小远小于基于BRNN的。所以可以证明,基于BRNN-vdl的模型的定位能力强于基于BRNN的。
6.7.RQ3的实验
作者在Test-set1和Test-set3上对比了VulDeeLocator和state-of-art方法,结果如下:

可以得出结论,VulDeeLocator在检测和定位漏洞能力上强于其它方法。
6.8.RQ4实验
作者用VulDeeLocator对在NVD上2017-2019报出的漏洞进行检测,包括3个软件产品(FFmpeg 2.8.2, Wireshark 2.0.5, Libav 9.10),作者随机从中选取了200个程序进行测试,结果如下:

其中VulDeeLocator报出22个漏洞,18个是已确认的和4个假阳性,并漏报了5个漏洞。下表展示了确认报出的和漏报的样本。

七.局限性
- 只局限在C语言,毕竟用到的工具(clang,checkmarx,joern,DG)都支持C语言。以后怎么扩展到其它语言有待研究。
- 代码必须可被编译为中间语言,在代码不可编译的情况下不好用。
- 用到的4种语法规则能覆盖数据集中98.3%的已知漏洞,而SARD和NVD可能不能代表现实数据集。
- 对于漏洞检测任务需要订制神经网络模型。
- VulDeeLocator依旧是一个静态漏洞检测器,对于依赖于运行时信息检测的漏洞难以检测。
- 作者能部分地解释VulDeeLocator的有效性,但是在可解释性(explainability)这方面依旧需要更多研究。
八.总结
整个VulDeeLocator的流程图大致如下:
这篇和SySeVR存在很多相似,不同之处在于:
- 这里基于LLVM中间代码表示,而不是源代码。
- 这里的目的是输出漏洞行,不是二分类。















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









