










Chopped Symbolic Execution
1.引言
符号执行工具受到路径爆炸和约束求解限制的影响。下面的示例来自libtasn1的 extract_octet 函数,libtasn1根据ASN1规则解析输入字符串,libtasn1 4.5版本以前的release都会受到堆溢出漏洞的影响(CVE-2015-3622),示例中:
每一轮循环
-
extract_octet会调用get_length求出当前ASN数据对应的长度。 -
要么调用
append_value创建1个AST结点(对应ASN1规则,推测是终端结点)。 -
要么递归调用
extract_octet建立语法树。
其中第21行更新 str_len 会导致第8行调用 get_length 会造成堆缓冲区溢出。

在对上面示例进行符号执行时,嵌套函数调用会造成路径爆炸。输入长度为 n 的符号字符串对 get_length 进行符号执行会产生 4 * n 条路径,append_value 更是会产生更多路径并且由于大量调用约束求解影响性能。
为了执行到漏洞触发点,输入会经过2945次函数调用覆盖98个不同的函数,包括386727个指令。其中大部分函数调用与需要出发的漏洞没有太大关系,比如上述bug涉及 DECR_LEN 和 get_length,与 append_value没有太多关系。
因此作者提出一种新颖的符号执行形式,称之为chopped symbolic execution(CSE),允许用户在分析过程中指定要排除的代码中不感兴趣的部分(本文是函数调用),从而只针对重要的路径进行探索。
2.Overview
这里通过一个示例来整体说明CSE的工作流程,下图b部分每个灰色椭圆为1个状态,下图 main 调用了 f,而 f 为用户指定的要跳过的部分。
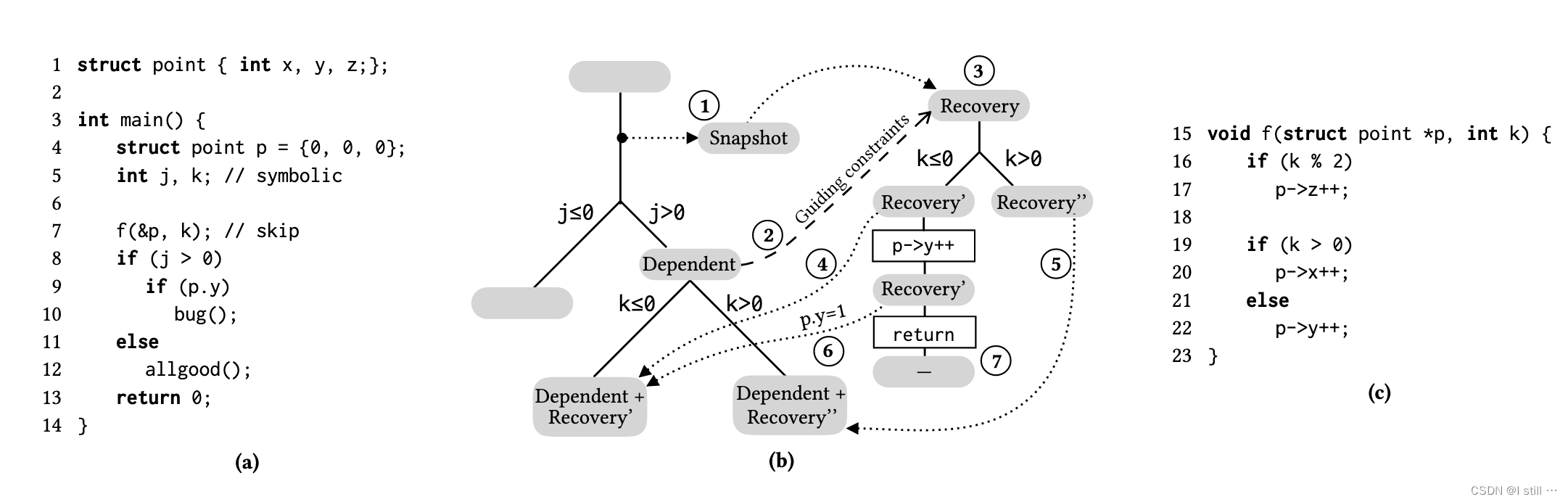
-
当一个状态对应的下一条指令为调用
f,CSE会clone当前状态为snapshot(1)(快照状态),并跳过当前函数调用。从下条指令开始,CSE需要考虑load指令可能会对f中的某些指令产生数据依赖。(f修改了p->z, p->x, p->y,main第9行读取了p.y,数据依赖于f第22行。,这里作者将第9行p.y这种读取可能受到影响的操作定义为dependent loads)。 -
如果
main函数中符号执行到11行else分支中的代码,那么不会触发dependent loads,因此不会调用f函数。 -
如果走的是第8行then分支,则会在第9行触发dependent loads
p.y,此时CSE会在将当前状态暂停并符号执行f,并且当前状态会成为dependent state(2),CSE基于之前的snapshot创建一个新的recovery state(3),并开始符号执行f。在上面示例p.y对应状态为dependent state,f入口处对应状态为recovery state。 -
执行recovery state发生fork时会将fork同步回dependent state(4, 5)。
-
对dependent load操作读取的内存行
store的操作也会同步回dependent state(6)。 -
如果recovery state下成功返回了,那么恢复对应dependent state的执行。如果执行recovery state时发生了错误,那么对应的dependent state也会停止执行。
同时还需要注意的是
-
当执行recovery state时,对应dependent state上的约束条件也会同步过来,保证路径约束的一致性。
-
在recovery state的执行中,很多路径对dependent loads并没有影响,比如
k % 2,这里作者用到program slice技术,相对于写入dependent loads读取的内存位置的store指令对函数f进行切片(示例中从p->y++对应的store指令开始切片)-
如果
f调用了其它函数,也对调用链上的其它函数进行slice)。 -
示例中,slice可以去掉16-17行和20行。
-
-
理论上dependent state和recovery state是一一对应的。
在示例中:
-
1.
main函数执行到第7行,创建snapshot并跳过函数调用。 -
2.执行到第9行,将当前状态变成dependent state并暂停。
-
3.克隆snapshot创建recovery state,将dependent state的约束条件
j > 0同步到recovery state。 -
4-5.基于dependent load读取的内存地址对函数
f进行slice,理论上能删除16-17行和20行,19行fork的时候,dependent state中也会发生fork。 -
6.其中一个forked recovery state会更新
p->y的值,因此在dependent state对应位置上也会更新。 -
7.最终,recovery state成功返回,CSE恢复dependent state开始符号执行。
3.Chopped Symbolic Executio(CSE)
与普通的符号执行相比
-
CSE多引入了一个外部参数
skipFunctions。(为用户指定跳过的函数,上面示例中skipFunctions = {f}) -
同时对于
load, store, br, ret, call指令添加了特殊处理。 -
对于符号状态,成员变量多了
-
skipped(为list类型),每个元素为当前状态跳过的1个函数调用及对应snapshot。 -
isRecovery(bool类型),标识当前状态是否是recoveryState。 -
overwrittenSet(set类型),记录当前状态写入过的地址。
-


上面红框标出的为CSE相比普通符号执行添加的部分:
-
Call指令:如果当前状态s对应将要执行的指令是call,并且调用的函数在skipFunctions中,那么基于当前状态clone一个snapshot,将(f, snapshot)添加到s.skipped列表中。 -
Load指令:需要考虑是不是dependent load,如果s对应将要执行的指令是load,首先查看load读取的内存地址addr,如果s跳过的函数中存在可能修改addr的指令,那么创建recoveryState。这里用到了2个辅助函数mayMod和createRecoveryState。 -
Br指令:需要考虑是不是在recovery state中的分支,如果是就需要同时考虑dependent state中的具体情况,recovery state中发生的fork也要同步到dependent state中。 -
Store指令:如果当前是在recovery state中进行store,那么会将修改的值同步到dependent state中。否则,将写入的地址记入到overwrittenSet中。 -
Return指令:如果当前状态是recovery state并且ret指令是在skipfunction函数体中,那么recovery state被终止,同时恢复dependent state执行。
需要注意的有:
3.1.静态推理过程
处理dependent load时用到了 MayMod 函数
 上面的函数需要先进行指针分析,作者用到了context-insensitive, flow-insensitive, field-sensitive的指针分析算法。需要注意的是:
上面的函数需要先进行指针分析,作者用到了context-insensitive, flow-insensitive, field-sensitive的指针分析算法。需要注意的是:
-
指针分析在1个测试程序的分析过程只执行1次。
-
每次创建recovery state的时候都会先进行slice,也就是slice会进行多次。
ModSet 用到了指针分析结果,指针分析中每个指针变量的内存位置会用 allocation site 进行抽象,比如 L: p=malloc(4) 属于1个allocation site,计作
A
S
L
AS_L
ASL,如果程序中包含 p = q,那么 p 可能指向
A
S
L
AS_L
ASL。指向图中的每个结点是一个指针变量名或者 allocation site,边表示潜在的指向关系。
指针分析算法是flow-insensitive的,因此在当前函数中可能存在其它 store 指令修改 addr,因此:
-
addr必须可能被skipFunction修改。 -
在skip function call和dependent load指令中间不能有其它对
addr进行修改的store指令,之前用到的overWritten成员变量正是用来判断当前addr是否已被其它store指令修改。
3.2.多重recovery state
7 f(&p,k); // skip
8 // next two branches depend on the side effects of f
9 if (p.x)
10 p.z++;
11 if (p.y)
12 p.z--;
上述示例中 f 的内容跟上一个示例一样,那么第9行读取 p.x 和第11行读取 p.y 处都会出现dependent load,并且都会产生dependent state和recovery state,但是,p.x 是在 k > 0 的情况下修改的,p.y 是在 k <= 0 的情况下产生的。因此在第一个dependent state恢复执行时,应该同步第一个recovery state中的约束,避免第二个dependent state中走向不可执行的path。
如下所示,第一个dependent state恢复后会fork成2个,一个添加约束条件 k > 0,另一个 k <= 0。而 p.y 只在第2个state中修改。
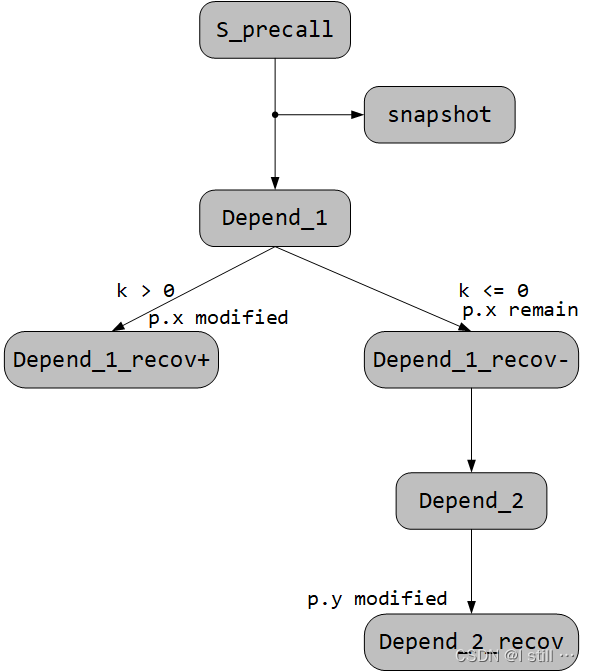
3.3.处理多重skip function
符号执行时可能会碰到多个skip function对一个 addr 进行写入的情况,作者用执行路径上最后一个可能修改 addr 的function进行搜索。
同样的还有1个问题,就是一个skip function可能会依赖于另一个skip function,如下面代码:
1 struct point { int x, y;};
2 void f1(struct point *p) {
3 p->y = 1;
4 }
5 void f2(struct point *p) {
6 if (p->y)
7 p->x = 1;
8 }
9 void g() {
10 struct point p;
11 f1(&p); // skip
12 f2(&p); // skip
13 if (p.x) {
14 // ...
15 }
16 }
执行到13行读取 p.x 触发dependent load,开始搜索 f2,执行到第6行读取 p->y 触发dependent load,此时探索 f1,因此 f1 执行完返回 f2 再执行完返回 g。同时注意的时 f2 对应的recovery state的 skipFunctions 一开始就包括了 f1。
为了提高CSE的效率,作者用到了recovery cache。
3.4.Memory Allocations
考虑以下代码,第8第9行都会触发dependent load,第8行dependent load会执行 f 第3行 malloc 语句,而第9行触发时又会执行第3、4行语句,这样 malloc 就执行了2次,会生成2个不同的地址,这其实是个错误。
为了预防这种错误,对于每个skip function,作者都会维护一个 list,其中每一个元素是 f 中的一个allocation site,与指针分析时不同,每个allocation site都会用其调用栈进行标识,这样当出现重复执行 alloca 指令的时候就能避免这种结果。
1 struct point { int x, y; } *p = NULL;
2 void f() {
3 p = malloc(sizeof(struct point));
4 p->x = 0;
5 }
6 void g() {
7 f(); // skip
8 if (p)
9 if (p->x) {
10 // ...
11 }
12 }
3.5.Chopping-aware搜索策略
传统SE中的搜索策略并没有考虑到CSE中状态的特性,在CSE中状态可分为normal和recovery(不考虑dependent),作者提出了一个新的搜索策略
-
传统搜索策略只用到了一个state worklist,CSE中用到2个,一个normal state worklist,一个recovery state worklist。
-
在选择状态的时候,首先以指定概率选择一个worklist(作者设定normal 0.8, recovery 0.2),然后再以正常方式选择状态。
3.6.局限性
主要的局限性来自符号地址,一个符号地址可能对应多个 allocation site,由此可能引用到多个skip function。此外,当在recovery state对某个地址执行存储时,CSE需要一个具体的加载地址来更新。
CSE目前侧重于跳过函数。然而,这种方法可以更通用:理论上可以跳过任何保留程序控制流的任意代码部分。
4.实现
项目的github地址,Chopper基于klee(commit b2f93ff)实现,指针分析用到SVF,反向切片用到了DG,用到了LLVM版本3.4.2,约束求解器为STP 2.1.2。
5.实验
实验主要探究2方面:
-
Failure reproduction:能比标准符号执行更快或者找到更多的bug吗?
-
Test suite augmentation:Chopper能否补充标准符号执行?
5.1.Failure reproduction
benchmark为libtasn1,包含的漏洞包括(都属于缓冲区溢出访问):
| Vulnerability | Version | C SLOC |
|---|---|---|
| CVE-2012-1569 | 2.11 | 24448 |
| CVE-2014-3467 | 3.5 | 22,091 |
| CVE-2015-2806 | 4.3 | 28115 |
| CVE-2015-3622 | 4.4 | 28109 |
CVE-2014-3467有3个触发位置因此在实验中被当成3个漏洞。
实现包括以下工作:
-
手动为libtasn1库创建一个执行驱动程序,以从其公共接口运行库,模拟外部程序的交互(GnuTLS)。
-
通过检查代码和漏洞报告来手动导出要跳过的函数集,漏洞报告通常包括堆栈跟踪,有时还来自动态分析工具。对于选定的case,作者设法在每次失败不到30分钟的时间内确定要排除的候选函数集,但熟悉代码的开发人员应该能够更快地做到这一点。
-
采用的搜索策略包括DFS,随机状态搜索,覆盖率引导(klee选项为
dfs, random-state, nurs:covnew),限时24小时。
实验结果如下所示:
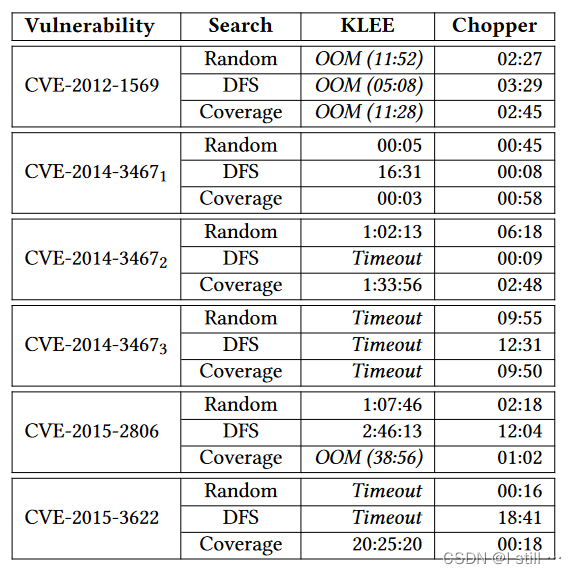
下图展示了Chopper在检测过程中生成的recovery和snapshot数量,以及用slice和不用slice的运行时间
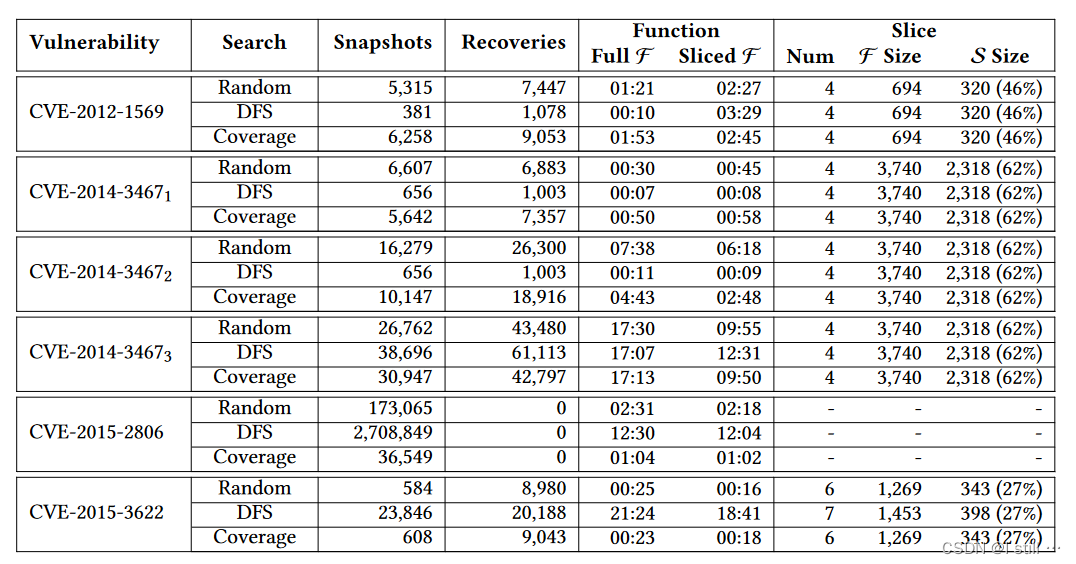 在检测CVE-2015-2806的时候,Chopper生成了0个recovery state,意味着skip function从没被执行过,因此跳过了许多不必要的执行。在检测CVE-2014-3467时,Chopper在slice的情况下提高了运行效率。但是在检测CVE-2012-1569时,不用slice反而运行更快,合理的解释是slice带来了额外的开销。
在检测CVE-2015-2806的时候,Chopper生成了0个recovery state,意味着skip function从没被执行过,因此跳过了许多不必要的执行。在检测CVE-2014-3467时,Chopper在slice的情况下提高了运行效率。但是在检测CVE-2012-1569时,不用slice反而运行更快,合理的解释是slice带来了额外的开销。
5.2.Test Suite Augmentation
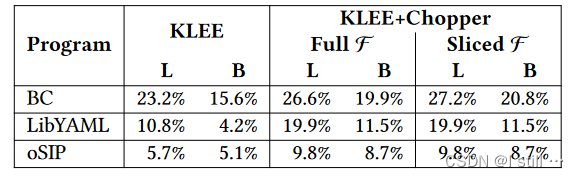
这部分做的是覆盖率测试,用到的benchmark是BC, LibYAML和GNU oSIP,这部分对比的是纯Klee和Klee+Chopper组合,Klee+Chopper的运行流程为:
-
先运行Klee生成初始Testcase,统计line和branch覆盖率,用到的策略为
nurs:covnew,限时1小时。 -
收集没被覆盖的函数,比如
f调用g和h,f和h已被覆盖,那么skip function就包含h,包含f的话g就不可达了。 -
运行chopper,对于normal state使用
nurs:covnew策略,对于recovery state使用dfs策略,限时1小时。
实验结果在下表。
参考文献
Chopped Symbolic Execution; David Trabish, Andrea Mattavelli, Noam Rinetzky, Cristian Cadar















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









