







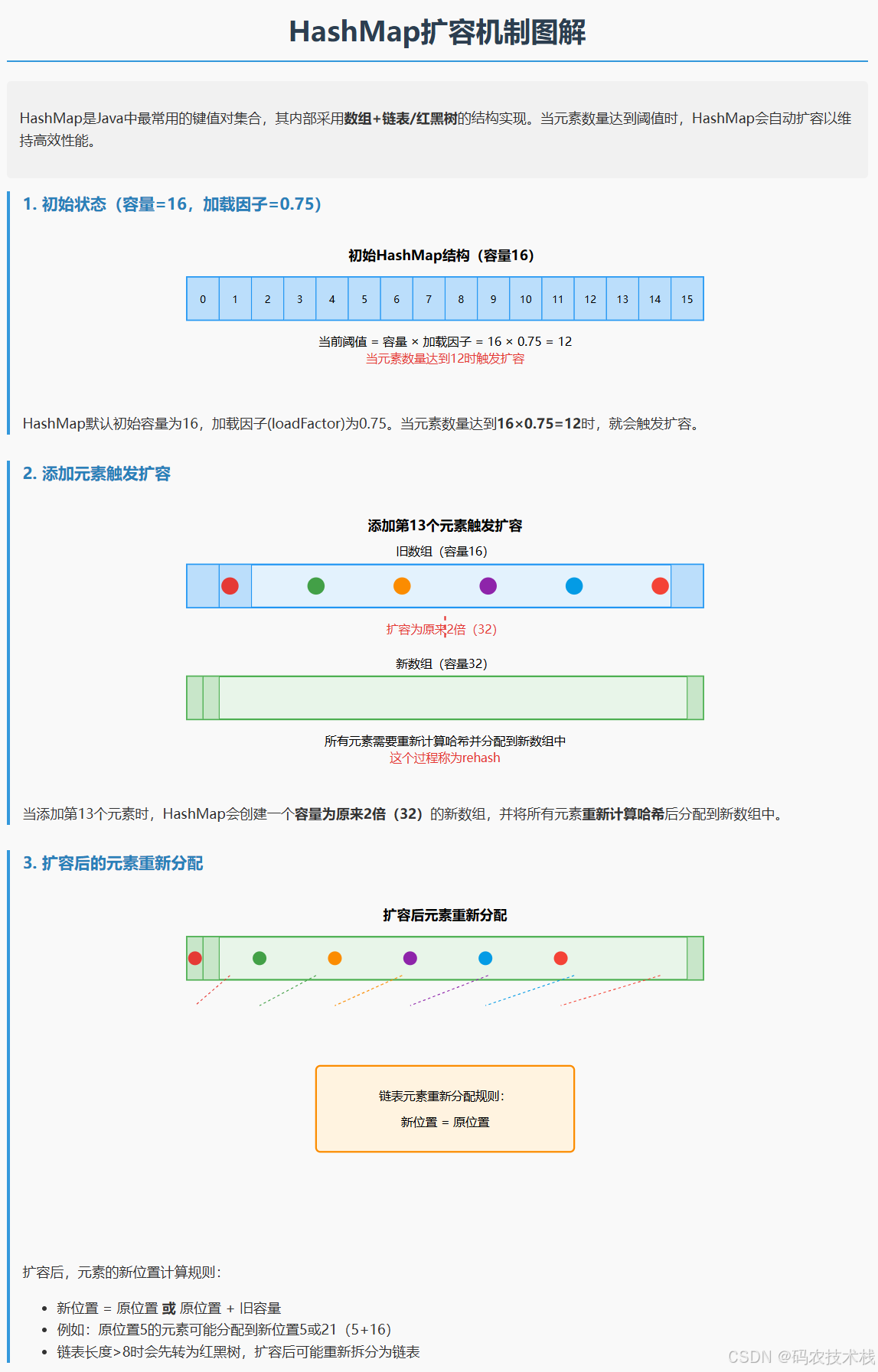
在Java中,HashMap是最常用的集合类之一,它通过“数组+链表(红黑树)”的结构实现快速查找。但你有没有想过:当存入的数据越来越多,底层数组不够用时,HashMap是如何“动态扩容”的?
一、为什么需要扩容?
先想象一个场景:
HashMap的底层是一个数组,比如初始时数组长度(容量)是16。每个元素通过哈希值计算下标,存到数组的某个位置。如果存入的元素太多(比如存了20个),数组“装满了”,就会导致大量元素挤在同一个位置(哈希冲突),链表或红黑树变得很长,查询效率从O(1)退化成O(n)。
扩容的目的:扩大数组容量,让元素分布更稀疏,减少哈希冲突,保证查询效率。
二、扩容的触发条件
HashMap不会等到数组“完全装满”才扩容,而是通过两个关键参数控制:
- 容量(Capacity):底层数组的长度,必须是2的幂(如16、32、64…)。
- 负载因子(Load Factor):默认是0.75,用来控制“数组装到多少时触发扩容”。
触发公式:
当已存元素数量(size) > 容量(capacity) × 负载因子(loadFactor)时,触发扩容。
比如默认情况下:
- 初始容量16,负载因子0.75,触发扩容的临界值是 16 × 0.75 = 12。
- 当存入第13个元素时,就会触发扩容。
三、扩容的具体过程:从16到32的蜕变
假设现在有一个容量为16的HashMap,触发扩容后,会分两步完成“生长”:
1. 创建新数组:容量翻倍,且仍是2的幂
- 新容量 = 旧容量 × 2(比如16→32,32→64)。
- 为什么必须是2的幂?
因为HashMap通过哈希值与运算(hash & (capacity - 1))计算下标,当容量是2的幂时,capacity-1的二进制全是1,能保证下标均匀分布,减少冲突。
2. 迁移旧元素:重新计算下标,放入新数组
旧数组中的每个元素,需要重新计算在新数组中的位置。这里有个巧妙的优化:
利用“高位哈希”快速定位,避免重新计算完整哈希值:
- 旧容量是16(二进制
10000),新容量是32(100000),两者的差值是16(010000)。 - 对于旧数组中的元素,其哈希值的第5位(从0开始数)如果是0,新下标和旧下标相同;如果是1,新下标 = 旧下标 + 旧容量。
(例如:旧下标是5,旧容量16,新下标可能是5或5+16=21,取决于哈希值的高位)
举例说明:
假设有个元素的哈希值二进制是 ...01011(低位5位是01011,对应下标5),旧容量16(二进制10000),新容量32(100000)。
- 旧下标:
01011 & 1111(15)= 5。 - 新下标:
01011 & 11111(31)= 5,或者5 + 16 = 21(取决于更高位是否为1)。
这样,元素要么留在原位置,要么移到“原位置+旧容量”的位置,无需重新计算整个哈希值,效率大大提高!
HashMap扩容机制图解
四、JDK 1.7 vs 1.8:扩容时的链表处理差异
- JDK 1.7:
迁移元素时,链表顺序会反转(因为采用头插法)。如果多个线程同时扩容,可能导致链表成环,引发死循环(这是1.7的经典bug)。 - JDK 1.8:
改用尾插法迁移元素,避免了链表反转,同时当链表长度≥8且容量≥64时,链表会转为红黑树,扩容时红黑树可能退化为链表(若拆分后节点数<6)。
五、扩容的性能影响与优化建议
- 耗时点:
扩容需要创建新数组、迁移所有元素,时间复杂度是O(n),元素越多越耗时。 - 优化建议:
- 如果提前知道数据量,初始化时设置合适的容量(通过构造方法
new HashMap<>(initialCapacity)),避免多次扩容。
计算方式:期望元素数 / 负载因子(0.75),并向上取最近的2的幂(如期望存20个元素,20/0.75≈27,取32)。 - 负载因子不是越小越好:
- 太小(如0.5)会频繁扩容,浪费内存;
- 太大(如1.0)会减少扩容次数,但增加哈希冲突,查询变慢。
- 如果提前知道数据量,初始化时设置合适的容量(通过构造方法
六、总结:HashMap扩容的核心逻辑
- 触发条件:元素数量超过“容量×负载因子”(默认12→16扩容)。
- 新容量:旧容量翻倍,始终是2的幂(保证下标计算高效)。
- 元素迁移:通过高位哈希快速定位新下标,链表用尾插法避免成环。
- 性能关键:合理设置初始容量,减少扩容次数,平衡内存与效率。
理解扩容机制,能帮我们在实际开发中更高效地使用HashMap。下次遇到“为什么HashMap初始化时建议指定容量”,你就知道答案啦!
如果觉得有帮助,欢迎点赞收藏~ 后续会分享更多Java集合底层原理,带你从“会用”到“精通”!


















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











