






Requests入门
- Requests安装
pip install requests
-
使用方式
requests模块主要用来模拟浏览器发送HTTP 请求,每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息。 -
request方法
delete(url, args) 发送 DELETE 请求到指定 url
get(url, params, args) 发送 GET 请求到指定 url
head(url, args) 发送 HEAD 请求到指定 url
patch(url, data, args) 发送 PATCH 请求到指定 url
post(url, data, json, args) 发送 POST 请求到指定 url
put(url, data, args) 发送 PUT 请求到指定 url
request(method, url, args) 向指定的 url 发送指定的请求方法 -
发送get请求
import requests
url = "http://www.xinfadi.com.cn/index.html"
resp = requests.get(url);
#设置编码格式
resp.encoding='utf-8'
# 查看响应状态码
print (resp.status_code)
# 查看响应头部字符编码
print (resp.encoding)
# 查看完整url地址
print (resp.url)
- 追加请求头
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44"
}
resp = requests.get(url,headers=headers);
- post请求
# 导入 requests 包
import requests
# 表单参数,参数名为 fname 和 lname
myobj = {'fname': 'RUNOOB','lname': 'Boy'}
# 发送请求
x = requests.post('https://www.runoob.com/try/ajax/demo_post2.php', data = myobj)
# 返回网页内容
print(x.text)
BeatifulSoup入门
BeatifulSoup简介
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
- 使用
import requests
from bs4 import BeautifulSoup
url = "http://www.umei.cc/bizhitupian/"
page = requests.get(url) #获取网页源代码
page.encoding='utf-8' #设置编码格式
htmls = BeautifulSoup(page.text,"html.parser") #创建解析器
创建解析器后,通过查询源代码html代码标签,可以通过htmls.find(“标签”,“标签的属性值”)或者htmls.find_all(“标签”,“标签的属性值”)的形式获取数据
例如:``
#表示获取class为"pic-list after"的ul标签下的所有a标签
aList = htmls.find("ul",class_="pic-list after").find_all("a")
#另一种写法,两种写法意义相同
aList = htmls.find("ul",attrs={"class":"pic-list after"}).find_all("a")
另外,还有通过select筛选,按标签名查找等方式查找数据,根据自己的习惯来使用
- 实例: 爬取优美图库图片并下载
import requests
from bs4 import BeautifulSoup
import time
url = "http://www.umei.cc/bizhitupian/"
page = requests.get(url)
page.encoding='utf-8'
htmls = BeautifulSoup(page.text,"html.parser") #
aList = htmls.find("ul",class_="pic-list after").find_all("a")
# print(aList)
main_url = "https://www.umei.cc"
for i in aList:
#每个图片的点击路径
print(i.get('href'))
child_url = i.get('href')
pic_page = requests.get(main_url+child_url)
pic_page.encoding='utf-8'
child_htmls = BeautifulSoup(pic_page.text,"html.parser")
img = child_htmls.find("section",class_="img-content").find("img").get('src')
print(img)
# 下载图片
img_resp = requests.get(img)
img_name = img.split("/")[-1]
with open("img/"+img_name,mode="wb") as f:
f.write(img_resp.content) #获取图片的字节码文件
print(img_name,"下载完成!!!")
time.sleep(1)
print("所有图片下载完成!!!")
xpath入门
xpath 是在xml中搜索内容的一门语言
使用时,安装lxml模块 pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple lib_name
注意,老版本的lxml导入模块,使用的是from lxml import html, 新版本取消了etree模块
from lxml import html
etree = html.etree
- xpath用法
from lxml import html
etree = html.etree
f = open("xinfadi.html",'r',encoding='utf-8')
content = f.read()
f.close()
html = etree.HTML(content)
print(html)
# 获取网页中所有标签并遍历输出标签名
result = html.xpath("//*")
for i in result:
print(i.tag,end=" ")
# 获取节点
result = html.xpath("//li") # 获取所有li节点
result = html.xpath("//li/a") # 获取所有li节点下的所有直接a子节点
result = html.xpath("//ul//a") # 效果同上(ul下所有子孙节点)
result = html.xpath("//a/..") #获取所有a节点的父节点
print(result)
# 获取属性和文本内容
result = html.xpath("//li/a/@href") #获取所有li下所有直接子a节点的href属性值
result = html.xpath("//li/a/text()") #获取所有li下所有直接子a节点内的文本内容
print(result) #['百度', '京东', '搜狐', '新浪', '淘宝']
result = html.xpath("//li/a[@class]/text()") #获取所有li下所有直接含有class属性子a节点内的文本内容
print(result) #['百度', '搜狐', '新浪']
#获取所有li下所有直接含有class属性值为aa的子a节点内的文本内容
result = html.xpath("//li/a[@class='aa']/text()")
print(result) #['搜狐', '新浪']
#获取class属性值中含有shop的li节点下所有直接a子节点内的文本内容
result = html.xpath("//li[contains(@class,'shop')]/a/text()")
print(result) #['搜狐', '新浪']
# 按序选择
result = html.xpath("//li[1]/a/text()") # 获取每组li中的第一个li节点里面的a的文本
result = html.xpath("//li[last()]/a/text()") # 获取每组li中最后一个li节点里面的a的文本
result = html.xpath("//li[position()<3]/a/text()") # 获取每组li中前两个li节点里面的a的文本
result = html.xpath("//li[last()-2]/a/text()") # 获取每组li中倒数第三个li节点里面的a的文本
print(result)
print("--"*30)
# 节点轴选择
result = html.xpath("//li[1]/ancestor::*") # 获取li的所有祖先节点
result = html.xpath("//li[1]/ancestor::ul") # 获取li的所有祖先中的ul节点
result = html.xpath("//li[1]/a/attribute::*") # 获取li中a节点的所有属性值
result = html.xpath("//li/child::a[@href='搜狐']") #获取li子节点中属性href值的a节点
result = html.xpath("//body/descendant::a") # 获取body中的所有子孙节点a
print(result)
result = html.xpath("//li[3]") #获取li中的第三个节点
result = html.xpath("//li[3]/following::li") #获取第三个li节点之后所有li节点
result = html.xpath("//li[3]/following-sibling::*") #获取第三个li节点之后所有同级li节点
for v in result:
print(v.find("a").text)
-
快速获取xpath方法
通过网页源代码,点击,右键即可复制 -
xpath实战
import requests
from lxml import html
etree = html.etree
url = "http://pingxiang.zbj.com/search/case/?kw=saas&r=1&l=0"
resp = requests.get(url)
resp.encoding='utf-8'
# print(resp.text)
#解析
html = etree.HTML(resp.text)
divs = html.xpath('//*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div')
print("标题\t"," ","标签\t"," ","店铺名称\t"," ","店铺地址\t")
for div in divs:
title = div.xpath('./div/a[1]/text()')[0] #标题
tags = " ".join(div.xpath('./div/div//*/text()')) #标签
store_name = div.xpath('./div/a[2]/div[2]/div[1]/span[1]/text()')[0] #店铺名称
store_local = div.xpath('./div/a[2]/div[2]/div[1]/span[2]/text()')[0].replace(" ","").split("\n")[1]#店铺地址
store_score = div.xpath('./div/a[2]/div[2]/div[3]/span[1]/text()')[0] #店铺评分
print(title," ",tags," ",store_name," ",store_local)
Requests进阶
- 处理cookie
有些网站数据需要在登录情况下才能获取到,这使得用简单的requests请求是不可行的,Requests内置了处理cookie的方法,使用session请求,提交data即可携带cookie进行登录
import requests
#会话
session = requests.session()
#网页登录时,提交post请求,要求提交的form表单数据
data = {
"username":"",
"password":""
}
url = ""
#登录
response= session.post(url,data=data)
#查看携带的cookie
print(response.cookie)
防盗链
目前大部分网页数据都是异步请求,也就是数据并不在网页源代码,此时我们需要通过抓包获取异步请求的url从而来获取数据,但是有些网站我们直接访问异步请求url的做法是被网站禁止的,只有先访问网页url,之后再访问异步请求url,才能够获取数据,这就是因为有防盗链的存在,而我们只需要在请求头内添加防盗链参数,即可解决此问题
- 防盗链
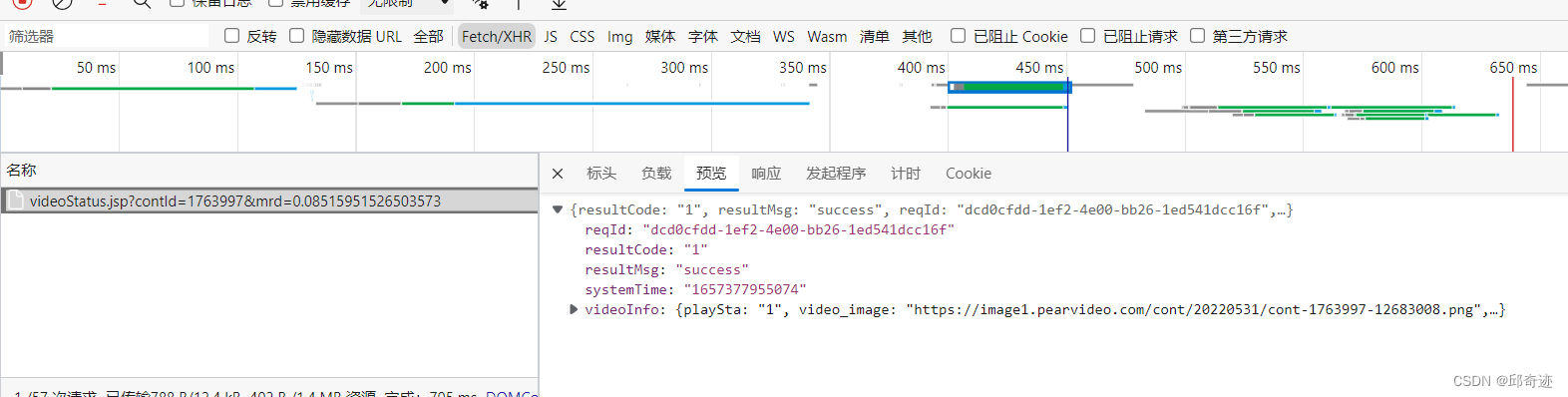
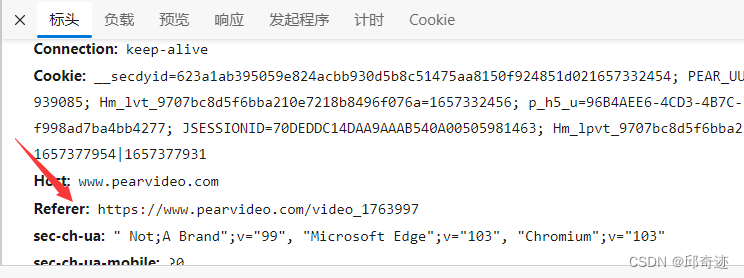
- 防盗链实战(爬取梨视频视频数据并下载)
import requests
# 最初url
url = "https://www.pearvideo.com/video_1767013"
contId = url.split("_")[1]
# 异步响应url
videoStatusUrl = "https://www.pearvideo.com/videoStatus.jsp?contId=1767013&mrd=0.1022088173482516"
#通过异步响应获取到的视频链接: https://video.pearvideo.com/mp4/third/20220708/1657332520146-11905134-113314-hd.mp4
# 真实视频链接: https://video.pearvideo.com/mp4/third/20220708/cont-1767118-11905134-113314-hd.mp4
# 由于网站对真实视频链接做过处理,因此,要对爬取到的视频链接进行还原
headers = {
# 请求头加上代理
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49",
# 请求头加上防盗链
"Referer": url,
}
res = requests.get(videoStatusUrl,headers=headers)
# 需要替换的部分
systemTime = res.json()['systemTime']
# 处理过的url
srcUrl = res.json()['videoInfo']['videos']['srcUrl']
print(systemTime,srcUrl)
# 替换为真实url
realUrl = srcUrl.replace(systemTime,"cont-"+contId)
print(realUrl)
# 下载视频
with open("a.mp4","wb") as f:
f.write(requests.get(realUrl).content)
f.close()














 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









