






一介绍
任务背景:
2018年IDRiD挑战sub1(hard exudates segmentation) using unet based on tensorflow and tensorlayer
任务描述
来自: https: //idrid.grand-challenge.org/Segmentation/
https://idrid.grand-challenge.org/Segmentation/
该挑战赛的目的是评估使用视网膜眼底图像自动检测和分级糖尿病性视网膜病变和糖尿病性黄斑水肿的算法。
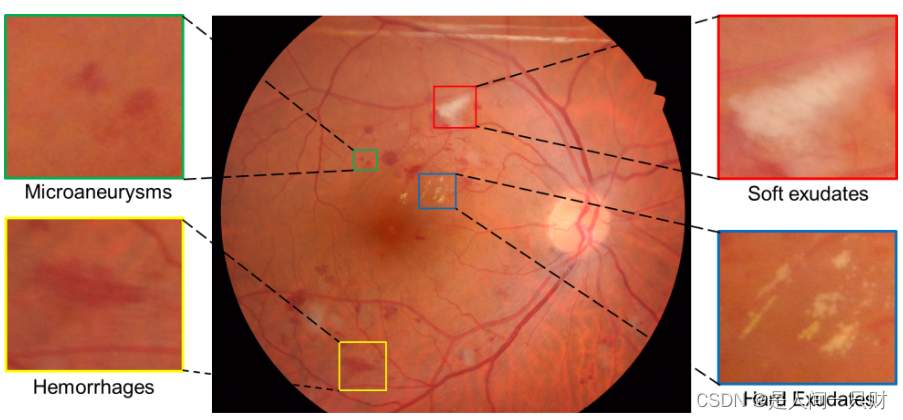
数据集介绍:
糖尿病性视网膜病变被称为一种临床诊断,表现为(见图)一个或多个视网膜病变,如微动脉瘤 (1. Microaneurysms)、出血 (2. Haemorrhages)、硬渗出物 (3. Hard Exudates) 和软渗出物 (4. Soft Exudates)。
与糖尿病视网膜病变相关的单个或多个病变的分割。子挑战可以分为四个不同的任务;参与者可以提交以下至少一项任务的结果:
- 微动脉瘤分割(MA)
- 出血分割(EX)
- 硬渗出物分割(HE)
- 软渗出物分割(SE)
数据构成:
它由 81 张图像组成,带有针对 MA、HE、SE 和 EX 等不同异常的像素级注释。

这里放上示例的图片,右边是图像,左边是真实标签。

下载地址: https://idrid.grand-challenge.org/Data_Download/![]() https://idrid.grand-challenge.org/Data_Download/
https://idrid.grand-challenge.org/Data_Download/
任务选择:
我这里的要做的任务是:渗出物分割--------HE。
二 模型方法
1.首先了解分割领域的一些常用指标:
TP:P表示你预测的Positive,T(True)表示你预测正确,TP表示你把正样本预测为正样本
FP:P表示你预测的Positive,F(False)表示你预测错误,FP表示你把负样本预测为正样本
TN:N表示你预测的Negative,T(True)表示你预测正确,TN表示你把负样本预测为负样本
FN:N表示你预测的Negative,F(False)表示你预测错误,FP表示你把正样本预测为负样本
(1)MIoU,它是分割任务的标准指标。
先介绍IoU(交并比),也称为 Jaccard 指数,它本质上是一种量化目标掩膜和预测掩膜之间重叠百分比的方法。具体来说,IoU 是预测分割和真实标签之间的重叠区域除以预测分割和真实标签之间的联合区域(两者的交集/两者的并集)。
IOU = TP / ( TP + FP + FN )
而MIoU 就是每个类别的IoU的平均。
(2)Dice相似系数
Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度(重叠程度),与F1-Score等价,与IoU基本相似。
dice = 2TP / ( 2TP + FP + FN )
(3)灵敏度(sen):sensitivity = TP / (TP + FN) ,
sensitivity 表示灵敏度,表示对正例的预测能力(越高越好),数值上等于召回率。
recall = TP / (TP + FN) , recall表示召回率, 针对的是所有的正样本中,预测正确的正样本(即把正样本预测为正样本)占的比例。召回率越高,表示找的越全。
(4)特异性(Specificity):specificity = TN / (TN + FP)
specificity 表示特异度,表示对负例的预测能力(越高越好)。
(5)像素准确率(piexl-acc):
acc = (TP+TN)/(TP+TN+FP+FN),其中, TP+TN+FP+FN=总像素数 ,TP+TN=正确分类的像素数 , 但是针对数据集类别不平衡的时候,它的准确率也是非常高的,这是因为前景和背景类像素差距太大,导致这种前景、背景不平衡的状态。这种不平衡数据分布在医学图像中是很常见的。比如我下面的实验的实验结果。
(6)precision = TP / (TP + FP) :
precision表示精确率,针对的是你所预测的正样本中,预测正确的正样本(即把正样本预测为正样本)占的比例。精确率越高,表示找的越准。
(7)HD95:
Dice对mask的内部填充比较敏感,而hausdorff distance 对分割出的边界比较敏感。
95%的豪斯多夫距离。其中Dice对mask的内部填充比较敏感,而HD对分割出的边界比较敏感。
HD95就是是最后的值乘以95%,目的是为了消除离群值的一个非常小的子集的影响。
2.损失函数的学习
(1)交叉熵(Cross Entorpy,CE)
可以理解为通过逐像素计算预测分布与groundtruth分布之间的“差距”得到损失函数的值。
交叉熵损失函数逐像素对比了模型预测向量与one-hot编码后的groundtruth,在二类分割问题中,
模型的概率预测结果可以由sigmoid函数(或softmax)计算得到,
其中,x 是模型的输出,后接sigmoid函数可以将其转为概率结果(即各类预测概率之和为1)
在这里我们要说一下,one-hot编码
从二分类推广到多分类分割问题时,需要用到one-hot编码。这在语义分割任务中是一个必不可少的步骤。一般情况下,我们分割的目标是为输入图像的每个像素预测一个标签:
如下图:是输入图像和它对应的语义分割

但是FCN类网络输出结果是h*w*c的特征图,想要在特征图与GT之间 计算Loss值 ,就必须进行转换使两者额的shape对应,而且每个像素点拥有对每一类的预测概率。因此,对于网络输出的特征图(假设预定类别数为C),我们使网络输出特征图为h*w*C,然后对每个像素位置的所有通道进行softmax操作,以使其表示为预测概率,最终通过取每个像素点在所有 channel 的 argmax 可以得到该像素点最终的预测类别。
对于数据标签(mask),为每一个类别创建一个输出通道(one-hot编码)。

GT经过one-hot编码后
这样一来,多分类转化为各个channel的二分类问题。
小结:交叉熵损失函数行使监督、易于理解,但忽略了不同类样本(像素)在样本空间的数量比例。ont-hot编码广泛应用于图像多类别分割问题中,使得所有二分类损失函数可以间接用于多分类任务
(2)Dice Loss(DL)
首先需要了解Dice系数,它可以衡量两个样本之间重叠程度,与F1-Score等价,与IoU基本相似。
Dice Loss在2016年的V-Net中首次提出,非常适用于类别不平衡问题,本身可以有效抑制类别不平衡引起的问题。
但是针对大背景中的小前景对象分割问题(常见于医学图像,典型的类别不平衡),基于重叠度的损失函数(例如Dice Loss),优化效果要好于原始的交叉熵损失函数。
但是单纯的dice loss不好收敛,我用的是loss = dice loss + cross_entorpy loss.
3学习率衰减策略
(1)StepLR
功能:等间隔调整学习率
lr_scheduler.StepLR(optimizer,step_size,gamma)
主要参数:step_size调整间隔数 gamma调整系数
设置step_size=50,每隔50个epoch时调整学习率,具体是用当前学习率乘以gamma
即lr=lr∗gamma
代码示例:
注意观察学习更新的位置所放的位置,必须要放在epoch迭代的下面。
for epoch in range(max_epoch):
for i in range(iteration):
...
loss = torch.pow((weights - target), 2)
loss.backward()
//优化器参数更新
optimizer.step()
optimizer.zero_grad()
//学习率更新
scheduler_lr.step()(2)MultiStepLR
功能:按给定间隔调整学习率
lr_scheduler.MultiStepLR(optimizer,milestones,gamma)
主要参数:milestones设定调整时刻数 gamma调整系数
如构建个list设置milestones=[50,125,180],在第50次、125次、180次时分别调整学习率,具体是用当前学习率乘以gamma
即lr=lr∗gamma
(3)ExponentialLR
功能:按指数衰减调整学习率
lr_scheduler.ExponentialLR(optimizer,milestones,gamma,last_epoch=-1)主要参数: gamma指数的底 , milestones参数含义如上。
调整方式:lr=lr∗gamma∗∗epoch(gamma通常会设置为接近于1的数值,如0.95)
(4)CosineAnnealingLR
功能:余弦周期调整学习率
lr_scheduler.ExponentialLR(optimizer,T_max,eta_min=0,last_epoch=-1)主要参数:T_max下降周期,eta_min最小学习率下限
(5)ReduceLRonPlateau
功能:监控指标,当指标不再变化则调整
lr_scheduler.ExponentialLR(optimizer,mode='min',
factor=0.1,patience=10,verbose=False,threshold=0.0001,
threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08)
主要参数:
mode:min和max
在min模式下面,观察监控指标是否下降,可以用于监控loss ;
在max模式下面 , 观察监控指标是否上升,可以用于监控acc等。
factor 调整系数:相当于上面几种策略的gamma值。
patience: "对待指标的耐心度",就是可以理解为接收几次不变化。比如这里的patience=10,可以理解为,某个指标在连续十次的epoch中都没有进行变化,就要进行学习率调整。
cooldown:“冷却时间”,停止监控一段时间。比如这里的cooldown=10,可以理解为某指标连续10次epoch没有进行变化,则进行学习率调整。
verbose:是否打印日志。
min_lr:学习率下限。
eps:学习率衰减最小值。
(6)LambdaLR
功能:自定义调整策略
功能很强大,但是需要自己有足够的理解去设置这个策略。
lambda1 = lambda epoch: 0.1 ** (epoch // 20)
lambda2 = lambda epoch: 0.95 ** epoch
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
如此,学习率衰减策略结束,想要详细了解的,可以自行搜索某个学习率策略的详细教程。
4图像增强方法---2D
(1). 直方图均衡化:通过调整图像像素的亮度分布,使之更具有对比度,从而增强图像的细节和信息。
(2). 去噪滤波:通过对图像进行滤波去除噪声和不必要的细节,从而使图像更清晰和易于分析。
(3). 锐化处理:通过增加图像中的高频信息,使得图像更加清晰和有轮廓,从而增强图像的细节。
(4). 色彩调整:通过增加或减少图像的颜色饱和度、亮度和对比度等属性,使得图像更加鲜明、清晰和易于分析。
(5). 图像缩放:通过对图像进行缩放处理,可以增加图像的分辨率,从而更容易分析图像中的细节和信息。
(6). 边缘检测:通过检测图像中的边缘,使得图像更加清晰和易于分析。
(7). 图像旋转和翻转:通过对图像进行旋转和翻转,可以使得图像更加清晰和易于分析。
对于彩色图像,它通常采用RGB颜色空间表示,其中R、G、B三个通道对应红、绿和蓝三种颜色。然而,由于颜色空间的特性,直接对RGB通道进行直方图均衡化可能会导致颜色失真、图像变形等问题。因此,通常将彩色图像转换到其他颜色空间进行处理。 其中,LAB颜色空间是一种广泛使用的颜色空间,它包含三个通道,即L、A、B通道。其中,L通道表示图像的亮度(Luminance),而A、B通道则表示颜色信息(Chromaticity)。由于L通道与图像的亮度相关,直方图均衡化可以有效地增强图像的对比度。而对于A、B通道,它们与图像的颜色信息相关,直接对它们进行直方图均衡化可能会导致色调变化、颜色失真等问题。因此,通常只对L通道进行直方图均衡化,而保持A、B通道不变。
推荐一个库,albumentations,里面已经集成很多很多方法,还可以组合使用,那就更多了。

四、实验结果:
输入图片:(左图为原始图片,右图为输入的下采样之后的图片)
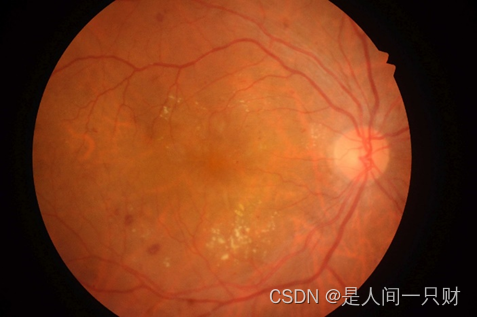
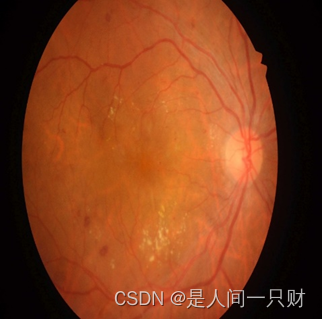
实验设置:
| Train | Val | Test |
| 40 | 14 | 27 |
| Lr | 1e-4 |
| Loss | Dice Loss + BCE Loss |
| 优化器 | Adam |
| Batch-Size | 2 |
| 数据增强 | CLAHE、亮度、对比度、旋转 |
| 数据预处理 | 归一化、标准化、Resize |
实验结果(test)
| Model | 数据集划分 | IOU | Dice | Precision | Sensitive |
| UNet | 原始数据集 | 0.5203 | 0.6744 | 0.6864 | 0.7032 |
| 数据集进行增强 | 0.5459 | 0.6945 | 0.7375 | 0.7050 | |
| UNet++ | 数据集进行增强 | 0.5553 | 0.7022 | 0.7203 | 0.7269 |
以下图片分别是原图 真实标签图 推理标签图

(2)其他一些网络尝试结果
| Model | 数据集划分 | IOU | Dice | Precision | Sensitive |
| AttUNet | 增强数据集 | 0.5626 | 0.7025 | 0.7546 | 0.7033 |
| MSUNet | 增强数据集 | 0.5219 | 0.6665 | 0.7091 | 0.6934 |
| UNet | 增强数据集 | 0.5481 | 0.6923 | 0.7362 | 0.7051 |
| UNet++ | 增强数据集 | 0.5724 | 0.7119 | 0.7661 | 0.7045 |
| UNetVgg16 | 增强数据集 | 0.5566 | 0.7033 | 0.7311 | 0.7183 |
| UNet++Vgg16 | 增强数据集 | 0.5654 | 0.7139 | 0.7297 | 0.7315 |
遇到的问题:
1.epoch,iteration,batch-size之间的关系?
epoch:当整个数据集全部经历了前相传播和反向传播,那么一个epoch就完成了。但如果 epoch 多于需要,它也可能导致曲线过度拟合。
iteration:
完成一个epoch所需的batchs总数称为iteration。例如,数据集包含 1000 张图像。我们将其分成十iteration,每iteration100 个。当一个iteration通过正向传播和反向传播的神经网络时,一次iteration完成。
下面的等式显示了batch-size和iteration与 epoch 之间的关系,可用于计算 epoch 大小:

batch-size:
通过神经网络的单个batch中的数据点总数称为batch-size。
一个epoch由很多batchs组成。有时由于内存不足或数据集太大,整个数据集无法一次通过神经网络。我们将整个数据集分成数量较少的部分,称为batch。这些批次通过模型进行训练。
当batch-size = 1的时候,
总的迭代次数 = len(train_loader) * epoch
当batch-size = n 的时候,
总的迭代次数 = len(train_loader) / n * epoch
2.二分类时,模型输出类别数的选择1还是2,如何去处理?
网上各种说法都有,这里没有做实验,不做评价,只是说明选择输出1还是2的时候,我们应该怎么做。
(1)输出为单通道:
即网络的输出 output 为 [batch_size,C,H,W] 形状。其中 batch_szie 为批量大小,C表示输出一个通道。
在训练时,模型输出通道数C是 1,网络得到的 output 包含的数值是任意的数。给定的 target 是一个单通道标签图,数值只有 0 和 1 这两种。为了让网络输出 output 不断逼近这个标签,首先会让 output 经过一个sigmoid 函数,使其数值归一化到[0, 1],得到 output1 ,然后让这个 output1 与 target 进行交叉熵计算,得到损失值,反向传播更新网路权重。最终,网络经过学习,会使得 output1 逼近target。
训练结束后,网络已经具备让输出的 output 经过转换从而逼近 target 的能力。首先将输出的 output 通过sigmoid 函数,然后取一个阈值(一般设置为0.5),大于阈值则取1反之则取0,从而得到预测 predict。后续则是一些评估相关的计算.
当网络最后一层没有使用sigmoid时,需要使用torch.nn.BCEWithLogitsLoss(),在这个函数中,拿到output首先会做一个sigmoid操作,再进行二进制交叉熵计算。
output = net(input) # net的最后一层没有使用sigmoid
loss_func1 = torch.nn.BCEWithLogitsLoss() #注意是用这个损失函数, 其内植了一个sigmoid函数
if train:
loss = loss_func1(output, target)
loss.backward()
else:
output1 = torch.sigmoid(output)
predict = torch.where(output1>0.5,torch.ones_like(output1),torch.zeros_like(output1))
pred_bind_labels = pred_bind_labels.cpu().numpy().tolist()loss_func1 = torch.nn.BCEWithLoss() #注意这个损失函数,其没有内置sigmoid函数
output = net(input) # net的最后一层没有使用sigmoid
output1 = torch.sigmoid(output)
if train: # 训练时
loss = loss_func1(output1, target)
loss.backward()
else:
# 即大于0.5的记为1,小于0.5记为0
predict = torch.where(output1>0.5,torch.ones_like(output1),torch.zeros_like(output1))
pred_bind_labels = pred_bind_labels.cpu().numpy().tolist()二, 输出为多通道:
即网络的输出 output 为 [batch_size, num_class] 形状。其中 batch_szie 为批量大小,num_class 表示类别数量。
在训练时,网络得到的 output 输出通道数num_class = 2, 包含的数值是任意的数 (数值范围不定). 给定的 target 是一个单通道标签值, 其中的数值要么是 0或者为 1。为了让网络输出 output 不断逼近这个标签,首先会让 output 经过一个 softmax 函数,使其数值归一化到[0, 1],得到 output1 ,在各通道中,这个数值加起来会等于1。对于target 他是一个单通道图,首先使用onehot编码,转换成 num_class个通道的图像,每个通道中的取值是根据单通道中的取值计算出来的,例如单通道中的第一个像素取值为1(0<= 1 <=num_class-1,这里num_class=2),那么onehot编码后,在第一个像素的位置上,两个通道的取值分别为0,1。也就是说像素的取值决定了对应序号的通道取1,其他的通道取0,这个非常关键。上面的操作执行完后得到target1,让这个 output1 与 target1 进行交叉熵计算,得到损失值,反向传播更新网路权重。最终,网络经过学习,会使得 output1 逼近target1(在各通道层面上)。
训练结束后,网络已经具备让输出的 output 经过转换从而逼近 target 的能力。计算 output 中各通道每一个像素位置上,取值最大的那个对应的通道序号,从而得到预测图 predict。后续则是一些评估相关的计算。
loss_func = torch.nn.CrossEntropyLoss()
logits = net(input) # net的最后一层没有使用sigmoid
if train: # 训练时
loss = loss_func(logits, target)
loss.backward()
else:
pred_labels = np.argmax(logits.data.cpu().numpy(), axis=1).tolist()实验总结:
当亲自动手对一个数据集进行分割框架的搭建的时候,一开始会发现有些困难,但是这个过程总是可以让人成长的,你总是看别人代码,总不过自己将框架,从数据读取部分开始搭建。
当然这仅仅代表我自己的观点。
所有的参考都放在下面,方便大家参考大佬们的原博客。谢谢大佬们的开源博客和代码,让我学习了很多。同时欢迎大家指正错误,方便我继续为这篇博客进行修改。
参考:
[1]语义分割中常用的评价指标有哪些?_mean intersection over union_行路南的博客-CSDN博客
[3]部分评价指标实现:FRCU-Net/Evaluate_Skin.py at main · rezazad68/FRCU-Net (github.com)
[5]基于U-Net的眼底图像血管分割实例_眼底图像分割_京局京段蓝白猪的博客-CSDN博客
[8]https://www.cnblogs.com/ylHe/p/12332319.html
[9]What is the difference between epoch, batch size, and iteration?
















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









