






[Cherno C++ 笔记 P21~P30]static,枚举,构造函数,析构函数,继承,虚函数,接口,可见性
系列博客
[Cherno C++ 笔记 P1~P10]安装、链接器、变量、函数、头文件
[Cherno C++ 笔记 P11~P20]判断,循环,指针,引用,类
[Cherno C++ 笔记 P21~P30] static,枚举,构造函数,析构函数,继承,虚函数,接口,可见性
[Cherno C++ 笔记 P31~P40]数组、字符串、CONST、mutable、成员初始化列表、三元操作符、创建初始化对象、new关键字、隐式转换与explicit
[Cherno C++ 笔记 P41~P50]运算符重载、this、生存期、智能指针、复制与拷贝构造函数、箭头操作符、动态数组、std::vector、静态链接、动态库
前言
这个系列的视频需要一些基础,最好是学过C。
视频链接
P31 C++数组
P32 C++字符串
P33 C++字符串字面量
P34 C++中的CONST
P35 C++的mutable关键字
P36 C++的成员初始化列表
P37C++的三元操作符
P38 创建并初始化C++对象
P39 C++ new关键字
P40 C++隐式转换与explicit关键字
C++数组
指针式C++数组工作方式的基础。
C++数组就是表示一堆相同类型变量组成的集合。
int example[5];
这样,我们就创建了一个有5个整数的数组,并且分配了对应的空间。
在这里,我们的数组有5个元素,下标从0到4,如果我们像exampl[5]这样去使用了不属于这个数组的空间,在debug模式下会报错,而在release模式下可能不会报错,它可能会修改属于其他变量的内存。所以,我们需要确保设置了安全检查,确保写的东西没有超出界限。

我们可以看到数组在内存中的样子。
当我们通过索引访问内存中的元素时,它实际做的时对这个内存取了一个偏移量,如果我们对example取2,它会偏移8个字节(2*4),然后向后读取4个字节,输出2。
数组实际上只是一个指针,我们可以这样写
#include<iostream>
int main()
{
int example[5];
int* ptr = example;
for (int i = 0; i < 5; i++)
{
example[i] = i;
}
std::cout << example[2] << std::endl;
std::cout <<*(ptr+2)<< std::endl;
std::cin.get();
}
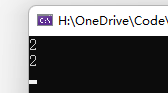
可以看到,结果是一样的。
在ptr+2中,因为ptr是一个int类型的指针,所以进行+2会偏移2*4个字节。
我们可以在堆上创建一个数组
#include<iostream>
int main()
{
int example[5]; // 在栈上创建
int* another = new int[5]; //在堆上创建
std::cin.get();
}
这两个数组的区别在于生存期,在栈上创建的数组example在花括号结束后会被销毁,而在堆上创建的数组another直到程序把销毁delete[] another;之前都是处于活动状态的。
在堆上创建数组会因为”间接寻址“导致性能的损耗
#include<iostream>
class Entity
{
public:
int example[5];
int* another = new int[5]; //在堆上创建
Entity()
{
for (int i = 0; i < 5; i++)
{
another[i] = 2;
example[i] = 2;
}
}
};
int main()
{
Entity e;
std::cin.get();
}
通过&e来得到e的内存地址

可以看到,在栈上的数组可以直接得到它的内存地址。

而在堆上创建的内存,我们可以看到,我们获取到的只是指向这个内存的一个内存地址,我们把这个内存地址输入进去

我们可以看到,经过一次转跳后,我们才能得到堆上数组的内容。
在C++11中,有一个标准数组std::array,相对于以上的原始内存,它有很多优点,例如边界检查,记录数组大小(原始数组无法计算大小)
P32 C++字符串
字符:char
字符串:字符数组
const char* name = "Name";

在表示”Name“的ascii编码后的0称为空终止字符,空终止字符是为了判断字符串的size。字符串从指针的内存地址开始,直到碰到0为止。
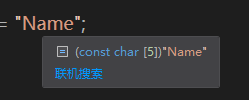
可以看到,这里Name的类型是const char[5],为什么会多一个呢?就是因为它多了一个空终止符({‘N’,‘a’,‘m’,‘m’,‘e’,0})
注意,在vs2019及以上版本中,不能像视频中那样去掉const
在c++中使用字符串,应该使用std::string。基本上,std::string就是一个char数组和一些操作这些数组的函数。
string有一个构造函数,它接收char或const char参数,
使用双引号包围起来的是一个const char类型的数组,如果要追加字符,char数组的是无法直接相加的
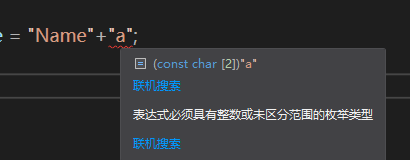
在这里,“Name”还不是真正的字符串
我们可以这样写
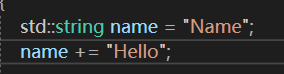
我们可以来看一下在字符串中查找一个字符串
bool find = name.find("me") != std::string::npos; //npos表示 是一个不存在的位置
std::cout << find << std::endl;
那么如何将字符串作为参数传递给其他函数呢?
void func(std::string string)
{
std::cout << string << std::endl;
}
这样写的话,我们实际上是创建了一个副本。
如果把一个类(对象)传递给一个函数时,这个操作实际上时在复制这个类(对象),在函数中对这个类(对象)进行的操作不会传递到原始的类(对象)中。
void func(const std::string& string)
{
std::cout << string << std::endl;
}
我们可以这样写,在这里,引用表示它不会被复制,const意味着我们承诺不会在这里修改它。
P33 C++字符串字面量
来看一下几种不同的字符串
const char* name = "char"; // 一个字节 utf8
const wchar_t* name2 = L"wchar"; //宽字符
const char16_t* name3 = u"char16"; // char16_t 2个字节 16个比特 utf16
const char32_t* name4 = U"char32";//char32 4个字节 32个比特 utf32
至于宽字符,它由编译器决定,在win上2个字节,在linux上4个字节
在c++14中,有一个函数可以让字符串的相加变得更简单
std::string name5 = "name"s + "hello"
s代表着一个操作符函数,它返回标准字符串对象,也可以把u、L、U放在前面,可以得到其他格式的字符串
在字符串前加R可以忽略转义字符
P34 C++中的CONST
const类似于private、public这样的关键词,它是对开发人员写代码强制特定的规则。它承诺某些东西将是不变的。
int MAX_AGE = 90;
// 常量指针
const int* a = &MAX_AGE;
int const* c = &MAX_AGE;
// 指针常量
int* const b = &MAX_AGE;
在常量指针中,指针指向的内容是不可改变的,指针看起来好像指向了一个常量
在指针常量中,指针自身的值是一个常量,不可改变,始终指向同一个地址。在定义的同时必须初始化
在类中
class Entity
{
private:
int m_x, m_y;
public:
int GetX() const
{
return m_x;
}
};
在方法参数列表后加入const,表示方法不会修改任何实际的类,不能修改类成员变量。
class Entity
{
private:
int* m_x, m_y; //这里的m_x为指针,而m_y为整型
public:
const int* const GetX() const
{
return m_x;
}
};
这里一行中有3个const,这意味着我们返回了一个不能被修改的指针,同时,指针内容也不能被修改,而且,这个方法承诺不修改实际的Entity类
注意,常对象只能调用常函数
class Entity
{
private:
int* m_x, m_y; //这里的m_x为指针,而m_y为整型
public:
const int* const GetX() const
{
return m_x;
}
};
void PrintEntity(const Entity& e)
{
std::cout << e.GetX() << std::endl;
}
在这里,如果将Get方法的const去掉,那么它会报错,因为Get方法无法保证不会对类内容做出修改。
P35 C++的mutable关键字
有些情况下,你确实想在一个标记为const的函数中修改类中的内容,那么你可以使用mutable关键字。
class Entity
{
private:
int* m_x, m_y; //这里的m_x为指针,而m_y为整型
mutable int m_z = 1;
public:
const int* const GetX() const
{
m_z += 1;
return m_x;
}
};
这样,通过mutable标记的内容就可以在const函数中进行修改。
mutable还有另一种使用方法,那就是在lambda中
int main()
{
int x = 8;
auto f = [&]() mutable
{
std::cout << ++x << std::endl;
};
f();
std::cin.get();
}
P36 C++的成员初始化列表
这是一种在构造函数中初始化类成员(变量)的一种方式。
我们在编写一个类并向该类添加成员时,通常需要某种方式对这些成员(变量)进行初始化。这在构造函数中通常有两种方法,1.我们可以在构造函数中初始化一个类成员。
#include<iostream>
#include<string>
class Entity
{
private:
std::string m_Name;
public:
Entity()
{
m_Name = "Unknown";
}
Entity(const std::string& name)
{
m_Name = name;
}
const std::string& GetName() const { return m_Name; }
};
int main()
{
Entity e0;
Entity e1("Hello");
std::cout << e0.GetName() << std::endl;
std::cout << e1.GetName() << std::endl;
std::cin.get();
}
2.我们可以通过成员初始化列表
class Entity
{
private:
std::string m_Name;
int m_Score;
public:
Entity() :m_Name("Unknown"),m_Score(90) {} // 这里的顺序要和上方定义变量的顺序一致。
Entity(const std::string& name)
{
m_Name = name;
}
const std::string& GetName() const { return m_Name; }
};
P37C++的三元操作符
s_Speed = s_Level > 5 ? 10 : 5;
三元运算符 ? :
?前为判断,:左边为判断成立要运行的,右边为判断失败运行的。
P38 创建并初始化C++对象
在栈上创建对象并初始化
#include<iostream>
#include<string>
using String = std::string;
class Entity
{
private :
String m_Name;
public:
Entity():m_Name("Unknown"){}
Entity(const String& name):m_Name(name){}
const String& GetName() const { return m_Name; }
};
int main()
{
// 在栈上创建对象
Entity entity("E1");
std::cout << entity.GetName() << std::endl;
std::cin.get();
}
如果可以使用这种方式创建对象,那尽量以这种方式创建对象,这是在C++中速度最快的方式,也是可管控的方式。
但是,这里的对象创建在栈上,在作用域之外,这个类会被销毁。
如果一个对象特别大,而且有多个同类型的对象,可能无法放在栈上,因为栈一般很小。
所以我们需要在堆上创建对象
#include<iostream>
#include<string>
using String = std::string;
class Entity
{
private :
String m_Name;
public:
Entity():m_Name("Unknown"){}
Entity(const String& name):m_Name(name){}
const String& GetName() const { return m_Name; }
};
int main()
{
// 在栈上创建对象
Entity entity("E1");
std::cout << entity.GetName() << std::endl;
// 在堆上创建对象
Entity* entity2 = new Entity("E2");
std::cout << entity2->GetName() << std::endl;
std::cin.get();
}
这里最大的区别不是这个类型变成了指针,而是关键字new。
我们调用构造函数时,new Entitiy实际上会返回一个Entity*,它会返回这个entity在堆上被分配的内存地址。
在堆上分配要比栈花费更长的时间,而且在堆上分配的话,必须手动释放内存。
P39 C++ new关键字
new的主要目的时在堆上分配内存,根据你所写的,不管是类还是基本类型,还是一个数组,它决定了必要的分配大小,以字节为单位。它会返回一个指向这个内存的指针,这样就可以开始使用创建的数据。new不仅会去分配空间,还会去调用构造函数。
new是一个操作符,就像加减乘除那样。这意味着你可以重载这个操作符,并改变它的行为。
调用new,实际上会重写它背后的函数malloc(),也就是说,调用new实际上相当于我们写了malloc(sizeof(Entity)),然后将其转换为Entity*类型。
Entity* e = new Entity();
Entity* e = (Entity*)malloc(sizeof(Entity));
这两个代码之间的区别,就在于new调用了Entity的构造函数,而malloc没有调用。
在使用new之后,一定要记得delete e,delete也是一个操作符,有block内存块和size作为参数,这是一个常规函数,它调用了C函数free,free可以释放malloc申请的内存。
如果我们使用new创建了一个数组(如new int[50]),我们需要使用delete[]
P40 C++隐式转换与explicit关键字
在两个类型之间,c++允许进行隐式转换,而不需要用cast做强制转换,类型转换是将数据类型转换到另一个类型的过程。
我们先创建一个类
class Entity
{
private :
String m_Name;
int m_Age;
public:
Entity(const String& name)
:m_Name(name),m_Age(-1){}
Entity(int age)
:m_Name("Unknown"), m_Age(age) {}
const String& GetName() const { return m_Name; }
};
再创建一个函数
void PrintEntity(const Entity& entity)
{
// Printing
}
PrintEntity(22); // 在这里,int类型的22隐式转换为Entity,因为Entity的构造函数中可以接收一个int类型的数据进行初始化
PrintEntity("Name"); // 这里报错的原因,是因为C++中只能进行一次隐式转换,“Name”是char类型的数据,需要将它转换为string类型才能转换为Entity类型
PrintEntity((std::string)"Name"); // 这样就不会报错了。
explicit
explicit与隐式转换有关,它禁用这个隐式转换的功能,explicit关键字放在构造函数前面,表示没有隐式的转换。
在上面的例子中,如果要使用整数构造这个Entity对象,则必须显式调用此构造函数。
class Entity
{
private :
String m_Name;
int m_Age;
public:
explicit Entity(const String& name)
:m_Name(name),m_Age(-1){}
Entity(int age)
:m_Name("Unknown"), m_Age(age) {}
const String& GetName() const { return m_Name; }
};
void PrintEntity(const Entity& entity)
{
// Printing
}
















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









