




 本文介绍使用Keras框架实现字符级LSTM的seq2seq模型,完成英语到法语的翻译任务。通过官方示例详细解析模型搭建、训练及推理过程。
本文介绍使用Keras框架实现字符级LSTM的seq2seq模型,完成英语到法语的翻译任务。通过官方示例详细解析模型搭建、训练及推理过程。
【从官方案例学框架Tensorflow/Keras】基于字符LSTM的seq2seq
注:本系列仅帮助大家快速理解、学习并能独立使用相关框架进行深度学习的研究,理论部分还请自行学习补充,每个框架的官方经典案例写的都非常好,很值得进行学习使用。可以说在完全理解官方经典案例后加以修改便可以解决大多数常见的相关任务。
摘要:【从官方案例学框架Keras】基于字符LSTM的seq2seq,实现英语至法语的翻译任务,并附有LSTM实现seq2seq的图示讲解
目录
1 Introduction
基于字符的seq2seq实现英文至法语的翻译任务
总结:
- domain to domain(英语 至 法语)
- encoder LSTM 保留最后的state层,丢弃输出层
- decoder LSTM 被训练把目标序列变成相同的序列,但在未来偏移一个时间步长,并使用teacher forcing训练方法
- inference推理阶段,将输入编码成state向量(encoder_state),并传递给decoder端,decoder再加上序列开始字符(本例中是\t)的输入进行字符级的预测,如预测出字母a,再将a加入到decoder输入中,同样进行字符级的预测,直到最终预测出序列结束字符(本例中是\n)
2 Setup
导入所需包
import numpy as np
import tensorflow as tf
from tensorflow import keras
2.1 Download the data
本地可以直接复制链接到浏览器即可下载:http://www.manythings.org/anki/fra-eng.zip
!!curl -O http://www.manythings.org/anki/fra-eng.zip
!!unzip fra-eng.zip
2.2 Configuration
定义超参数
# Configuration
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
# Path to the data txt file on disk.
data_path = "fra.txt"
3 Prepare the data
向量化文本数据,具体参加代码中的注释
这里要着重理解decoder_input_data与decoder_target_data差一个步长的关系,先别看后面的图思考一下为什么要设置差一个步长timestamp,之后再看Encoder-Decoder的示例图
# Vectorize the data.
input_texts = [] # 输入文本
target_texts = [] # 输出文本
input_characters = set() # 输入文本的字符字典
target_characters = set() # 输出文本的字符字典
with open(data_path, "r", encoding="utf-8") as f:
lines = f.read().split("\n")
# 取num_samples 和 文件行数的最小值
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text, _ = line.split("\t")
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = "\t" + target_text + "\n" # 本例中取'\t'为起始字符'\n'为终止字符
input_texts.append(input_text)
target_texts.append(target_text)
# 添加字符至字符字典
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print("Number of samples:", len(input_texts))
print("Number of unique input tokens:", num_encoder_tokens)
print("Number of unique output tokens:", num_decoder_tokens)
print("Max sequence length for inputs:", max_encoder_seq_length)
print("Max sequence length for outputs:", max_decoder_seq_length)
# token,分词后的结果转为index,如a:1,b:2
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens), dtype="float32"
)
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.0
encoder_input_data[i, (t + 1): , input_token_index[" "]] = 1.0
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.0
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.0
decoder_input_data[i, t + 1 :, target_token_index[" "]] = 1.0
decoder_target_data[i, t:, target_token_index[" "]] = 1.0

这里向量化的“时序数据”的形状为
(len(input_texts), max_encoder(decoder)_seq_length, num_encoder(decoder)_tokens)
- axis=0 翻译文本对数量
- axis=1 encoder(decoder)中最大的sequence长度,不足最大长度用" "填充,这里也就是timestamp
- axis=2 token在字符字典的索引
举例:字符字典为abc,输入文本为【‘ac’,‘bc’】,将会被编码为
’ac’【【0,0,0】,【0,1,2】】
‘bc’【【1,0,1】,【1,1,2】】
实际上是one-hot encoding方式,这里省略了全0的部分
4 Build the model
先看看模型的样子,辅助下面具体的例子,你将会完全理解如何用encoder-decoder架构去实现seq2seq,下面两幅图是完全对应的,且与之后的代码变量名对应。
model.summary()
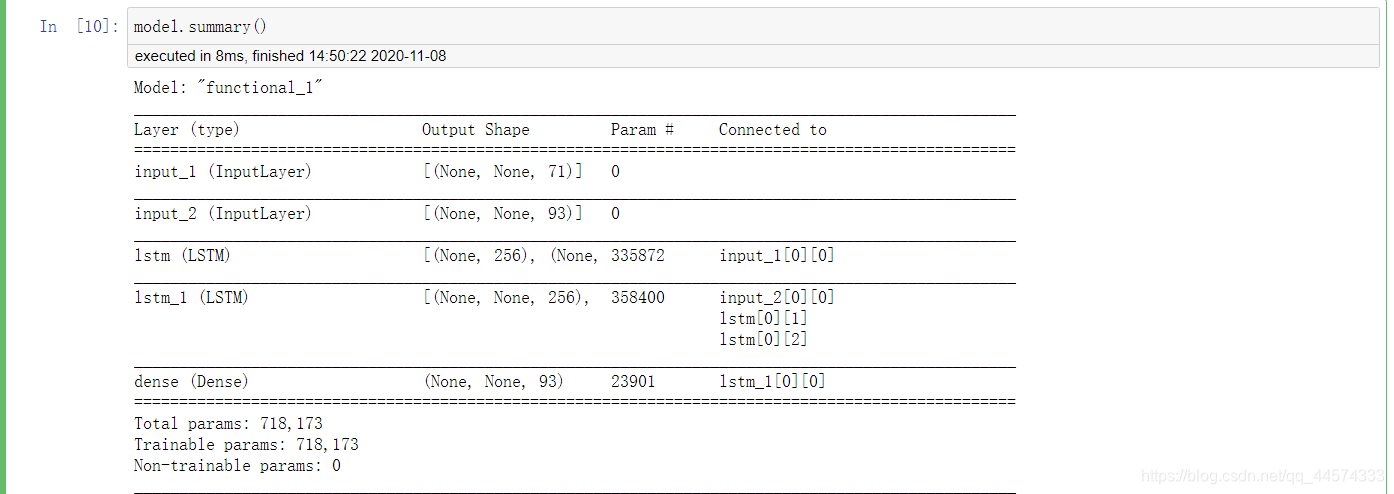
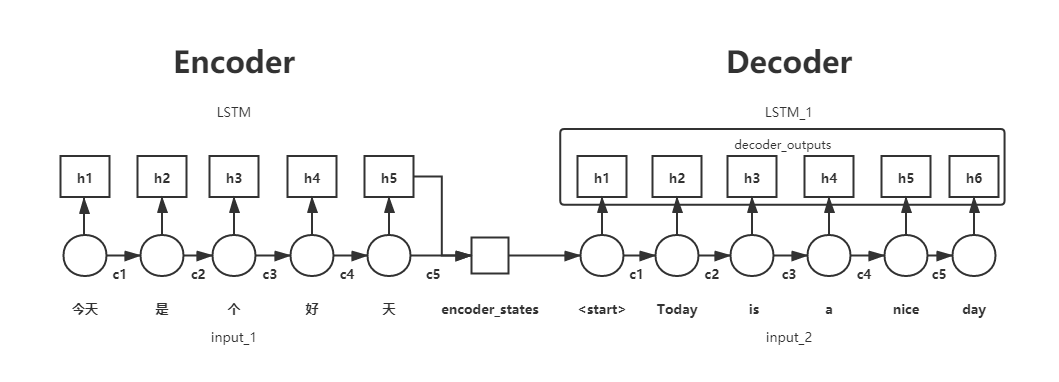
重点!:Keras中return_sequences与return_state的布尔取值,将会得到不同的state值
下面是这两个参数的描述,第一次看笔者也没太懂
-
return_sequences:默认 False。在输出序列中,返回单个 hidden state值还是返回全部time step 的 hidden state值。 False 返回单个, true 返回全部。
-
return_state:默认 False。是否返回除输出之外的最后一个状态。
在此,参照上图,举个例子,大家就会完全明白了,并了解到用encoder-decoder架构去实现seq2seq的基本思想
我们都知道LSTM是在RNN基础上的改进,相比RNN只有一个传递状态 h t h_t ht ,LSTM有两个传输状态,一个 c t c_t ct(cell state),和一个 h t h_t ht(hidden state)。简单而言,增加 c t c_t ct会影响之后产生 h t h_t ht的结果,从而解决RNN中梯度消失/爆炸的问题。
好了,让我们先回看上图中Encoder部分,当return_sequences与return_state的布尔取值不同时会得到如此的结果
| return_sequences | return_state | output |
|---|---|---|
| False | False | h5 |
| True | False | h1、h2、h3、h4、h5 |
| False | True | h5、h5、c5 |
| True | True | h1-h5、h5、c5 |
思考:encoder-decoder架构中,encoder起到什么作用,需要给decoder传递什么信息?
答:encoder需要将encoder_input即上图的Input_1时序编码成向量,代表了Input_1的讯息,也就是h5和c5组成的encoder_states
如果是简单的分类任务,encoder就足够了,取出h5交给Dense层进行分类任务即可
如果你已经明白了return_sequences与return_state的布尔取值的结果,再看之后的代码就会非常清晰简单!
下面代码已经给出与上图一样的表示注释来帮助大家理解
# Define an input sequence and process it.
encoder_inputs = keras.Input(shape=(None, num_encoder_tokens)) # 今天是个好天
encoder = keras.layers.LSTM(latent_dim, return_state=True) #h5,h5,c5
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c] # h5,c5
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = keras.Input(shape=(None, num_decoder_tokens)) # <start> Today is a nice day
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
# h1-h6,h6,c6
decoder_lstm = keras.layers.LSTM(latent_dim, return_sequences=True, return_state=True)
# h1-h6
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
# h1-h6进行一个一个的多分类
decoder_dense = keras.layers.Dense(num_decoder_tokens, activation="softmax")
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
5 Train the model
model.compile(
optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"]
)
model.fit(
[encoder_input_data, decoder_input_data],
decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
)
# Save model
model.save("s2s")
6 Run inference (sampling)
预测阶段,给定一个sequence,我们需要怎样把它代入到encoder-decoder模型中?
答:用该sequence输入到encoder端,得到encoder_state,将这个代表着输入sequence的encoder_state作为Decoder端的initial_state初始向量,即传递给Decoder端,并以’\t’代表Decoder端起始输入
同样,下面代码的注释与上图示例相同
# Define sampling models
# Restore the model and construct the encoder and decoder.
model = keras.models.load_model("s2s")
# encoder端生成encoder_states h5,c5
encoder_inputs = model.input[0] # input_1
encoder_outputs, state_h_enc, state_c_enc = model.layers[2].output # lstm
encoder_states = [state_h_enc, state_c_enc]
encoder_model = keras.Model(encoder_inputs, encoder_states)
# decoder端生成decoder_outputs h1,h2,h3,h4,h5,h6
decoder_inputs = model.input[1] # input_2
decoder_state_input_h = keras.Input(shape=(latent_dim,), name="input_3")
decoder_state_input_c = keras.Input(shape=(latent_dim,), name="input_4")
# 在预测阶段
# 这里的decoder_states_inputs就是以encoder端产生的encoder_states为初始化的
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_lstm = model.layers[3] # lstm_1
decoder_outputs, state_h_dec, state_c_dec = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs
)
# h1-h6,c6
decoder_states = [state_h_dec, state_c_dec]
decoder_dense = model.layers[4] # dense
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = keras.Model(
[decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states
)
# Reverse-lookup token index to decode sequences back to
# something readable.
# 就是index:char
reverse_input_char_index = dict((i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict((i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index["\t"]] = 1.0
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ""
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if sampled_char == "\n" or len(decoded_sentence) > max_decoder_seq_length:
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.0
# Update states
states_value = [h, c]
return decoded_sentence
for i in range(20):
seq_index = np.random.randint(num_samples)
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index : seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print("-")
print("Input sentence:", input_texts[seq_index])
print("Decoded sentence:", decoded_sentence)
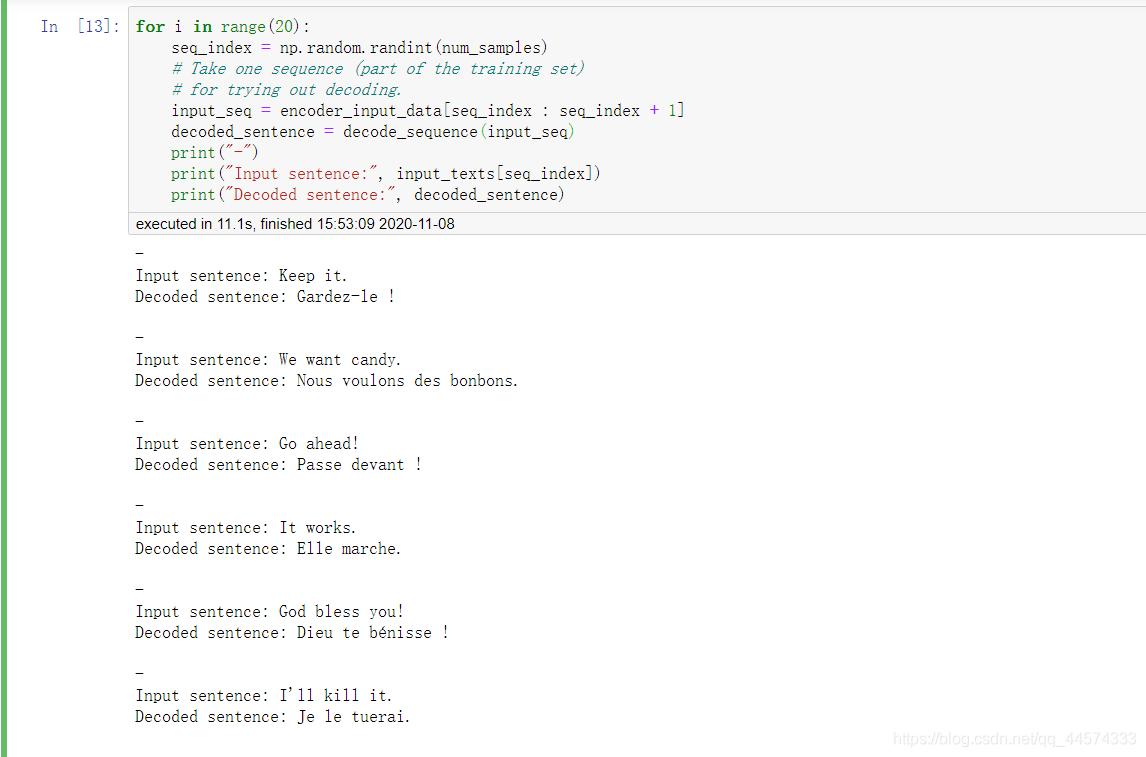
在本例中,encoder-decoder结构是没有什么不同的,两者都是LSTM,只不过是目标不同。理解好Keras中return_sequences与return_state的布尔取值的结果就可以轻松使用LSTM实现seq2seq。


















 3838
3838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











