







【天池智慧海洋建设】Topline源码——特征工程学习
团队名称:Pursuing the Past Youth
链接:
https://github.com/juzstu/TianChi_HaiYang
前言
topline代码开源学习,仅关注特征工程部分,具体为输入,输出,作用、原理及部分个人理解。
I 数据部分

原始数据描述:
渔船ID:渔船的唯一识别,结果文件以此ID为标示
x: 渔船在平面坐标系的x轴坐标
y: 渔船在平面坐标系的y轴坐标
速度:渔船当前时刻航速,单位节
方向:渔船当前时刻航首向,单位度
time:数据上报时刻,单位月日 时:分
type:渔船label,三种作业类型(围网、刺网、拖网)
II 代码部分
2.1 预处理部分
# 将原始数据以ID、time为主键进行排序
df.sort_values(['ID', 'time'], inplace=True)
# 将文本类时间如 ”0912 23:59:55“转换成'2019-09-12 23:59:55'
df['time'] = df['time'].apply(lambda x: '2019-' + x.split(' ')[0][:2] + '-' + x.split(' ')[0][2:] + ' ' + x.split(' ')[1])
df['time'] = pd.to_datetime(df['time'])
预处理部分的主要目的是整理数据,将(原始数据)脏数据转换成(可被处理、人类能看懂的数据)干净数据
2.2 特征工程部分
# 本行与下一行的经纬度、速度、分钟的差值
df['lat_diff'] = df.groupby('ID')['lat'].diff(1)
df['lon_diff'] = df.groupby('ID')['lon'].diff(1)
df['speed_diff'] = df.groupby('ID')['speed'].diff(1)
df['diff_minutes'] = df.groupby('ID')['time'].diff(1).dt.seconds // 60
# 找出锚点
df['anchor'] = df.apply(lambda x: 1 if x['lat_diff'] < 0.01 and x['lon_diff'] < 0.01
and x['speed'] < 0.1 and x['diff_minutes'] <= 10 else 0, axis=1)
# 选取出经纬度均不为0 以及 速度不为0
lat_lon_neq_zero = df[(df['lat_diff'] != 0) & (df['lon_diff'] != 0)]
speed_neg_zero = df[df['speed_diff'] != 0]
# 将标签数字化
df['type'] = df['type'].map({'围网': 0, '刺网': 1, '拖网': 2,0 'unknown': -1})
基本的dataframe处理,基础知识不再阐述
# 将多条相同ID的数据行,聚合为ID
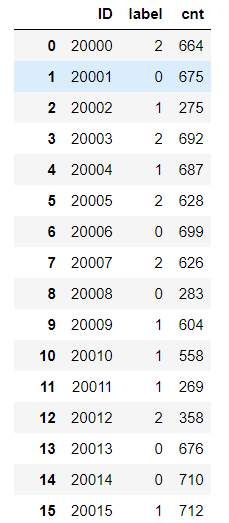
group_df = df.groupby('ID')['type'].agg({'label': 'mean', 'cnt': 'count'}).reset_index()
对于df.groupby的基本用法:
df.groupby('主键')[’所选要处理的列名‘].agg({'新定义的列名':'所用方法'})
具体而言,上述代码表示为将所有相同ID的type取mean平均值、count统计值,并定义其列名为’label’和’cnt’
效果如下:
# 同样的聚合操作,对上面做出的anchor锚点进行求和
anchor_df = df.groupby('ID')['anchor'].agg('sum').reset_index()
anchor_df.columns = ['ID', 'anchor_cnt']
# 将锚点统计值链接到group_df中
group_df = group_df.merge(anchor_df, on='ID', how='left')
# 将锚点统计值除以数据type的统计值,得出锚点的频率
# 注:这里使用频数代替type的统计值更符合实际意义,但如果同一个ID下的type完全相同,
# 只会与实际有大小的差异,而对整体数据没有影响
group_df['anchor_ratio'] = group_df['anchor_cnt'] / group_df['cnt']
上述代码,获取锚点anchor位置信息
# 定义函数并命名
stat_functions = ['min', 'max', 'mean', 'median', 'nunique', q10, q20, q30, q40, q60, q70, q80, q90]
stat_ways = ['min', 'max', 'mean', 'median', 'nunique', 'q_10', 'q_20', 'q_30', 'q_40', 'q_60', 'q_70', 'q_80', 'q_90']
# 所要进行的统计列:经度、维度、速度、方向,同样的groupby操作不再阐述,并命名
stat_cols = ['lat', 'lon', 'speed', 'direction']
group_tmp = df.groupby('ID')[stat_cols].agg(stat_functions).reset_index()
group_tmp.columns = ['ID'] + ['{}_{}'.format(i, j) for i in stat_cols for j in stat_ways]
# 同样对经纬度不为0的数据以ID聚合,同样进行上述数据列的统计
lat_lon_neq_group = lat_lon_neq_zero.groupby('ID')[stat_cols].agg(stat_functions).reset_index()
lat_lon_neq_group.columns = ['ID'] + ['pos_neq_zero_{}_{}'.format(i, j) for i in stat_cols for j in stat_ways]
# 同样对速度不为0的数据以ID聚合,同样进行上述数据列的统计
speed_neg_zero_group = speed_neg_zero.groupby('ID')[stat_cols].agg(stat_functions).reset_index()
speed_neg_zero_group.columns = ['ID'] + ['speed_neq_zero_{}_{}'.format(i, j) for i in stat_cols for j in stat_ways]
# 将统计后的三个DataFrame链接到group_df中
group_df = group_df.merge(group_tmp, on='ID', how='left')
group_df = group_df.merge(lat_lon_neq_group, on='ID', how='left')
group_df = group_df.merge(speed_neg_zero_group, on='ID', how='left')
在这里可以注意到,虽然使用同样的列、同样的方法,但是却在整个数据的不同子集下进行统计,并将其统一到一起
group_tmp:总数据
lat_lon_neq_group:经纬度不为0的数据
speed_neg_zero_group:速度不为0的数据
def q10(x):
return x.quantile(0.1)
对于上述统计特征的构造是很有普遍意义的,在此进行解释
‘min’,:取最小值
‘max’:取最大值
‘mean’:取均值
‘median’:取中位数
‘nunique’: 取唯一值的个数
‘q_10’(q_20等同理): 分位数的计算,在pandas实现也很简单,如上所示,使用.quantile指定p值即可。
分位数的计算有两种方法:
分位数计算法一
pos = (n+1)*p,n为数据的总个数,p为0-1之间的值
分位数计算法二
pos = 1+ (n-1)*p,n为数据的总个数,p为0-1之间的值
分位数的计算有两种方法:
分位数计算法一
pos = (n+1)*p,n为数据的总个数,p为0-1之间的值
分位数计算法二(pandas中所使用的)
pos = 1+ (n-1)*p,n为数据的总个数,p为0-1之间的值
统计学上的四分为函数
原则上q是可以取0到1之间的任意值的。但是有一个四分位数是p分位数中较为有名的。
所谓四分位数;即把数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数。
第1四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第2四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
第3四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第3四分位数与第1四分位数的差距又称四分位距(InterQuartile Range,IQR)
mode_df = df.groupby(['ID', 'lat', 'lon'])['time'].agg({'mode_cnt': 'count'}).reset_index()
mode_df['rank'] = mode_df.groupby('ID')['mode_cnt'].rank(method='first', ascending=False)

同样对总数据进行聚合操作,所选取列为time,方法为统计,得出对于ID、经纬度的相同time时间统计,并在此数据上(上图所示)对时间的统计值进行排序
# 获取TOP频次的位置信息,这里选Top3
for i in range(1, 4):
tmp_df = mode_df[mode_df['rank'] == i]
del tmp_df['rank']
tmp_df.columns = ['ID', 'rank{}_mode_lat'.format(i), 'rank{}_mode_lon'.format(i), 'rank{}_mode_cnt'.format(i)]
group_df = group_df.merge(tmp_df, on='ID', how='left')
这里的取出rank排序等于1、2、3的数据,并将其经度、维度、时间统计值链接到group_df中
tfidf_df = get_geohash_tfidf(df, 'ID', 'lat_lon', 30)
group_df = group_df.merge(tfidf_df, on='ID', how='left')
print('geohash tfidf finished.')
grad_tfidf = get_grad_tfidf(df, 'ID', 'grad', 30)
group_df = group_df.merge(grad_tfidf, on='ID', how='left')
print('gradient tfidf finished.')
sample_tfidf = get_sample_tfidf(df, 'ID', 'sample', 30)
group_df = group_df.merge(sample_tfidf, on='ID', how='left')
print('sample tfidf finished.')
w2v_df = w2v_feat(df, 'ID', 'lat_lon', 30)
group_df = group_df.merge(w2v_df, on='ID', how='left')
print('word2vec finished.')
经典的数字向量化,所用方法有tf-idf、word2vec,下面看看实现代码
def geohash_encode(latitude, longitude, precision=12):
"""
Encode a position given in float arguments latitude, longitude to
a geohash which will have the character count precision.
"""
lat_interval, lon_interval = (-90.0, 90.0), (-180.0, 180.0)
base32 = '0123456789bcdefghjkmnpqrstuvwxyz'
geohash = []
bits = [16, 8, 4, 2, 1]
bit = 0
ch = 0
even = True
while len(geohash) < precision:
if even:
mid = (lon_interval[0] + lon_interval[1]) / 2
if longitude > mid:
ch |= bits[bit]
lon_interval = (mid, lon_interval[1])
else:
lon_interval = (lon_interval[0], mid)
else:
mid = (lat_interval[0] + lat_interval[1]) / 2
if latitude > mid:
ch |= bits[bit]
lat_interval = (mid, lat_interval[1])
else:
lat_interval = (lat_interval[0], mid)
even = not even
if bit < 4:
bit += 1
else:
geohash += base32[ch]
bit = 0
ch = 0
return ''.join(geohash)
def get_geohash_tfidf(df, group_id, group_target, num):
df[group_target] = df.apply(lambda x: geohash_encode(x['lat'], x['lon'], 7), axis=1)
tmp = df.groupby(group_id)[group_target].agg(list).reset_index()
tmp[group_target] = tmp[group_target].apply(lambda x: ' '.join(x))
tfidf_tmp = tfidf(tmp[group_target], num, group_target)
count_tmp = count2vec(tmp[group_target], num, group_target)
return pd.concat([tmp[[group_id]], tfidf_tmp, count_tmp], axis=1)
geohash_encode: Encode a position given in float arguments latitude, longitude to
a geohash which will have the character count precision.
get_geohash_tfidf:使用这样一个函数geohash_encode
geohash_encode所用的是开源https://github.com/vinsci/geohash一个库,可以对经纬度进行编码解码的库
def tfidf(input_values, output_num, output_prefix, seed=1024):
tfidf_enc = TfidfVectorizer()
tfidf_vec = tfidf_enc.fit_transform(input_values)
svd_tmp = TruncatedSVD(n_components=output_num, n_iter=20, random_state=seed)
svd_tmp = svd_tmp.fit_transform(tfidf_vec)
svd_tmp = pd.DataFrame(svd_tmp)
svd_tmp.columns = ['{}_tfidf_{}'.format(output_prefix, i) for i in range(output_num)]
return svd_tmp
tf-idf“文本向量化”+SVD奇异值分解
def count2vec(input_values, output_num, output_prefix, seed=1024):
count_enc = CountVectorizer()
count_vec = count_enc.fit_transform(input_values)
svd_tmp = TruncatedSVD(n_components=output_num, n_iter=20, random_state=seed)
svd_tmp = svd_tmp.fit_transform(count_vec)
svd_tmp = pd.DataFrame(svd_tmp)
svd_tmp.columns = ['{}_countvec_{}'.format(output_prefix, i) for i in range(output_num)]
return svd_tmp
count2vec不同实现的“文本向量化”
# workers设为1可复现训练好的词向量,但速度稍慢,若不考虑复现的话,可对此参数进行调整
def w2v_feat(df, group_id, feat, length):
print('start word2vec ...')
data_frame = df.groupby(group_id)[feat].agg(list).reset_index()
model = Word2Vec(data_frame[feat].values, size=length, window=5, min_count=1, sg=1, hs=1,
workers=1, iter=10, seed=1, hashfxn=hashfxn)
data_frame[feat] = data_frame[feat].apply(lambda x: pd.DataFrame([model[c] for c in x]))
for m in range(length):
data_frame['w2v_{}_mean'.format(m)] = data_frame[feat].apply(lambda x: x[m].mean())
del data_frame[feat]
return data_frame
word2vec,经典的文本向量化
def d2v_feat(df, group_id, feat, length):
print('start doc2vec ...')
data_frame = df.groupby(group_id)[feat].agg(list).reset_index()
documents = [TaggedDocument(doc, [i]) for i, doc in zip(data_frame[group_id].values, data_frame[feat])]
model = Doc2Vec(documents, vector_size=length, window=5, min_count=1, workers=1, seed=1, hashfxn=hashfxn,
epochs=10, sg=1, hs=1)
doc_df = data_frame[group_id].apply(lambda x: ','.join([str(i) for i in model[x]])).str.split(',', expand=True).apply(pd.to_numeric)
doc_df.columns = ['{}_d2v_{}'.format(feat, i) for i in range(length)]
return pd.concat([data_frame[[group_id]], doc_df], axis=1)
document2vec,文档向量化,只不过是以文档为基础进行操作
















 7191
7191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











