







这个word2vec的方法是在2013年的论文《Efficient Estimation of Word Representations inVector Space》中提出的,作者来自google,文章下载链接:https://arxiv.org/pdf/1301.3781.pdf
1、基本介绍
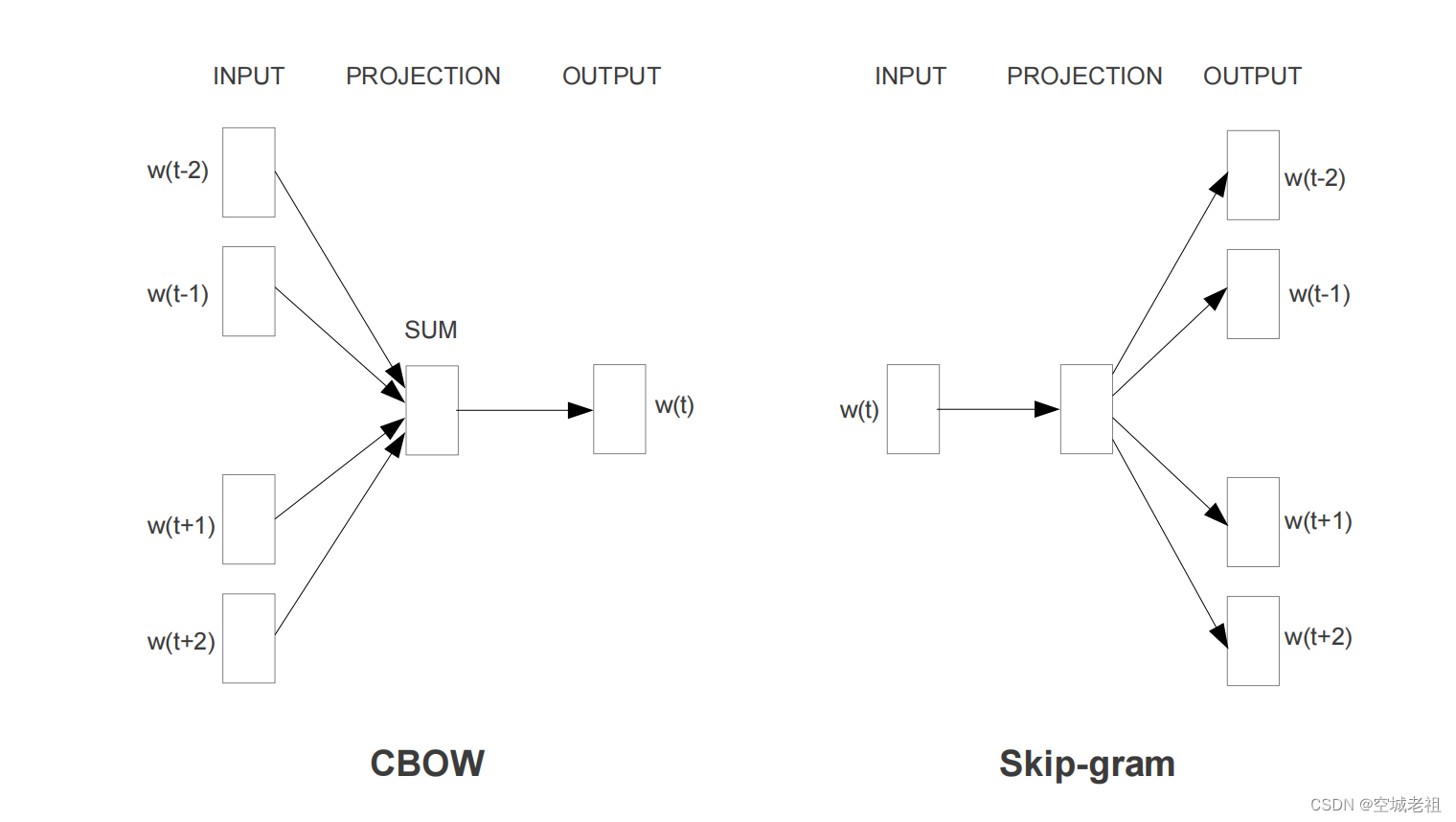
word2vec是一种将word转为向量的方法,其包含两种算法,分别是skip-gram和CBOW,它们的最大区别是skip-gram是通过中心词去预测中心词周围的词,而CBOW是通过周围的词去预测中心词。
为什么要把单词转化为向量呢?这是由于在进行自然语言处理时,我们有可能要比较两个短语或者语句的相似性,比较他们的语义信息行,而让机器理解句子就比较困难,所以要转化成计算机能看懂的语言——数字,从而我们就能进后面的一系列操作。这种方法更像是自然语言处理的一个前序工作、一个桥梁,有了这种方法,文本与后面的研究就被连接了起来。
它是一种语言模型,使用向量表示单词,向量空间表示句子。在将单词转化为向量之后,句子也就可以被表示成一个矩阵,这样就把现实中的语言成功转化成了数字。
它是一种词嵌入模型,简单来说,就是可以通过训练词嵌入模型将文本由原来的高维表示形式转化为低维表示形式,每一个维度代表着当前单词与其它单词在该维度下的不同,多个维度的数共同来表示这个单词。
2、word2vec的原理是什么?
图解词嵌入、语言模型、Word2Vec![]() https://blog.csdn.net/kun_csdn/article/details/89061689word2vec简介、原理、缺陷及应用。
https://blog.csdn.net/kun_csdn/article/details/89061689word2vec简介、原理、缺陷及应用。![]() https://blog.csdn.net/qq_43160348/article/details/124313872
https://blog.csdn.net/qq_43160348/article/details/124313872
词嵌入来龙去脉 word embedding、word2vec![]() https://blog.csdn.net/u012052268/article/details/77170517
https://blog.csdn.net/u012052268/article/details/77170517
3、 one-hot 编码
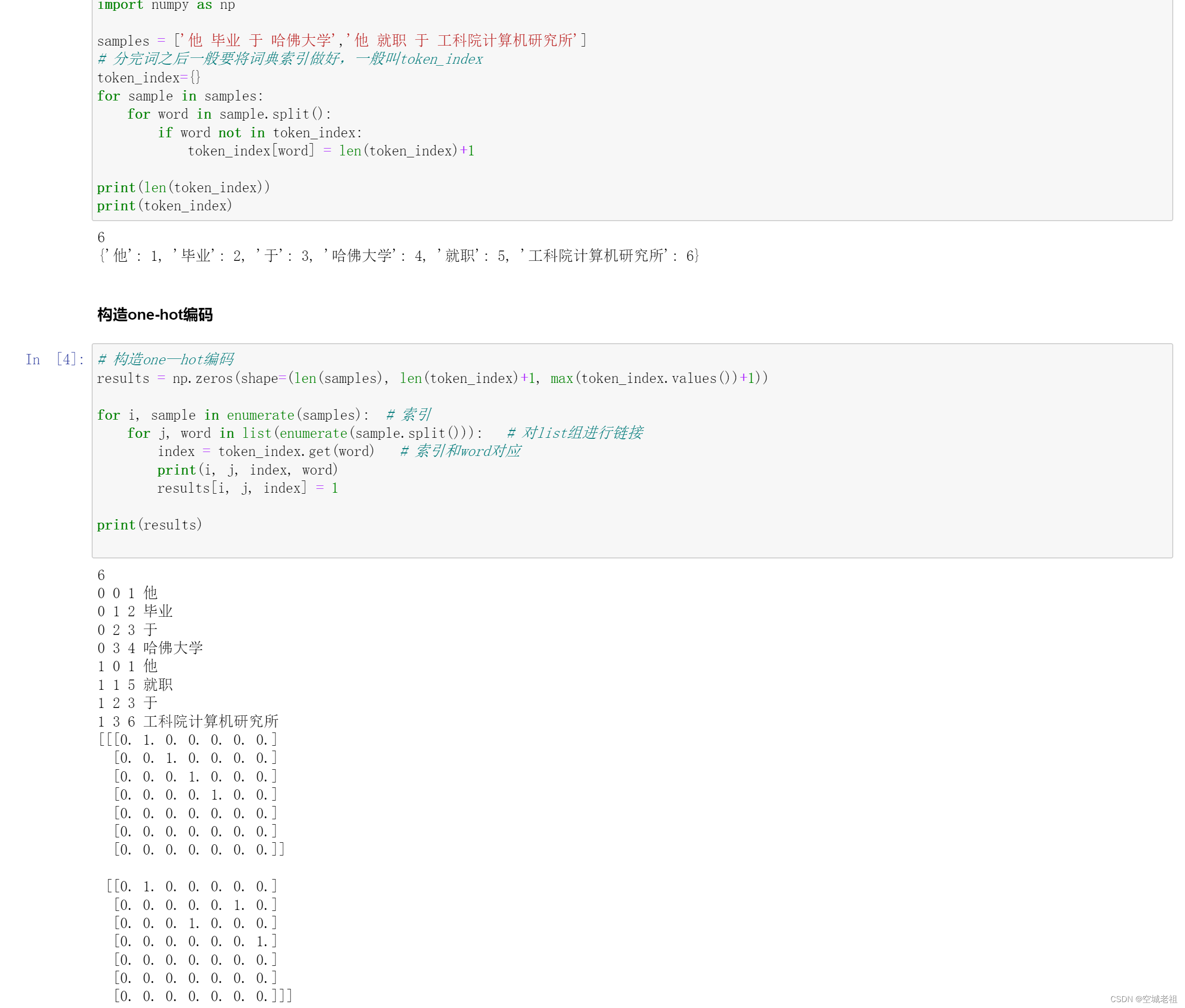
将词语或者字向量化可以使用 one-hot 编码,one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。例如我们有一句话为:“我爱北京天安门”,我们分词后对其进行one-hot编码,结果可以是:
“我”: [ 1,0,0,0 ]
“爱”: [ 0,1,0,0 ]
“北京”: [ 0,0,1,0 ]
“天安门”: [ 0,0,0,1 ]
one-hot 在提取特征文本上面的应用
one-hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
- 我爱中国
- 爸爸妈妈爱我
- 爸爸妈妈爱中国
我们首先对预料库分词,并获取其中所有的词,然后对每个此进行编号:1我;2爱;3爸爸;4妈妈;5中国

优缺点分析
优点:
- 一是解决了分类器不好处理离散数据的问题
- 二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:
- 它是一个词袋模型,不考虑词与词之间的顺序
- 它假设词与词相互独立(在大多数情况下,词与词是相互影响的)
- 它得到的特征是离散稀疏的;
实验:手写one-hot编码
回归主题:ont-hot编码在大量数据的情况下会出现维度灾难,通过观察我们可以知道上面的one-hot编码例子中,如果不同的词语不是4个而是n个,则one-hot编码的向量维度为1*n,也就是说,任何一个词的one-hot编码中,有一位为1,其他n-1位为0,这会导致数据非常稀疏(0特别多,1很少),存储开销也很大(n很大的情况下)。
那有什么办法可以解决这个问题呢?分布式表示
通过训练,将每个词都映射到一个较短的词向量上来。常见的如300维
在展示的这些维度中的数字已经不是1和0了,而是一些其他的浮点数。这种将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入(word embedding)。
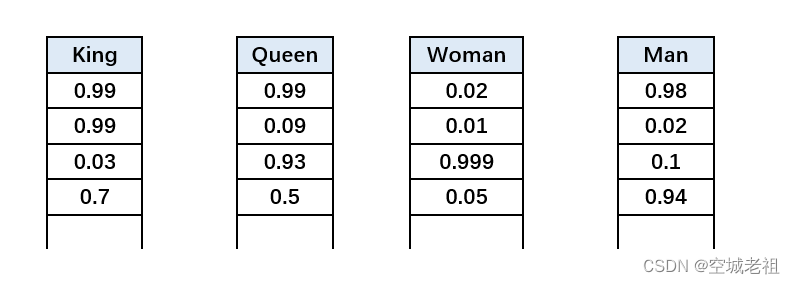
有个有意思的发现是,当我们使用词嵌入后,词之间可以存在一些关系,例如:
k i n g kingking的词向量减去m a n manman的词向量,再加上w o m a n womanwoman的词向量会等于q u e e n queenqueen的词向量!

出现这种神奇现象的原因是,我们使用的分布式表示的词向量包含有词语上下文信息。
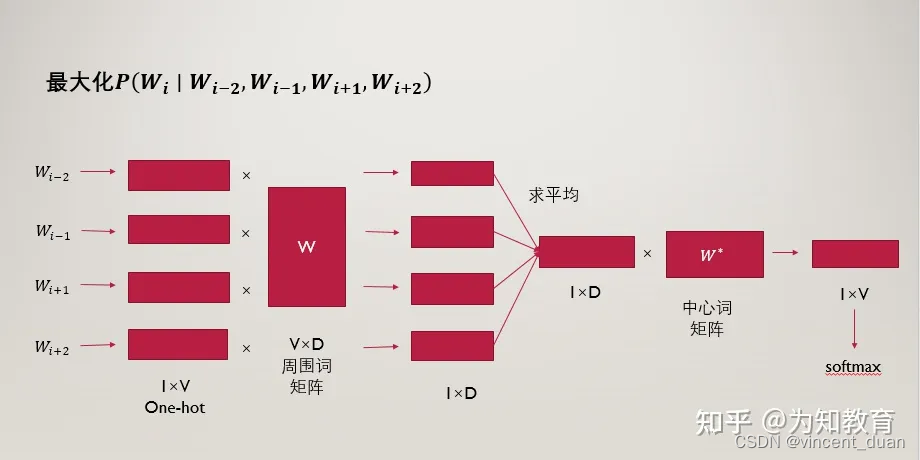
2、CBOW模型
CBOW模型结构
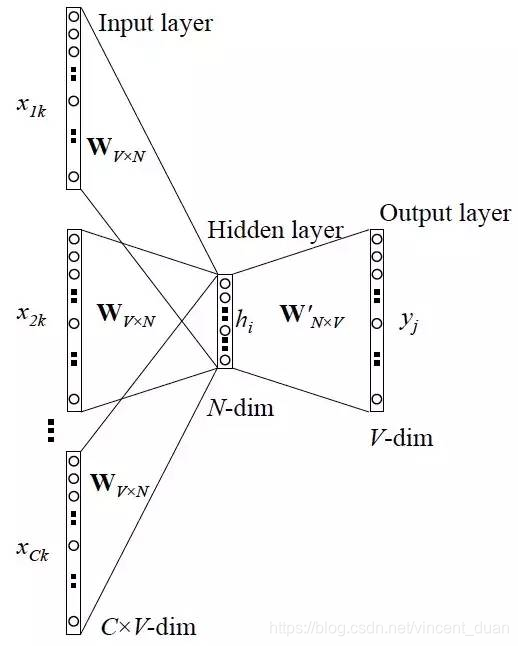
最左边的一列是当前词的上下文词语,例如当前词的前两个词和后两个词,一共4个上下文词。 这些上下文词即为图中的
这些词是one-hot编码表示,维度为 1*V。(其中V 为词空间的大小,也就是有多少个不同的词,则one-hot编码的维度为多少,也就是V 个不同的词)
CBOW模型的前向计算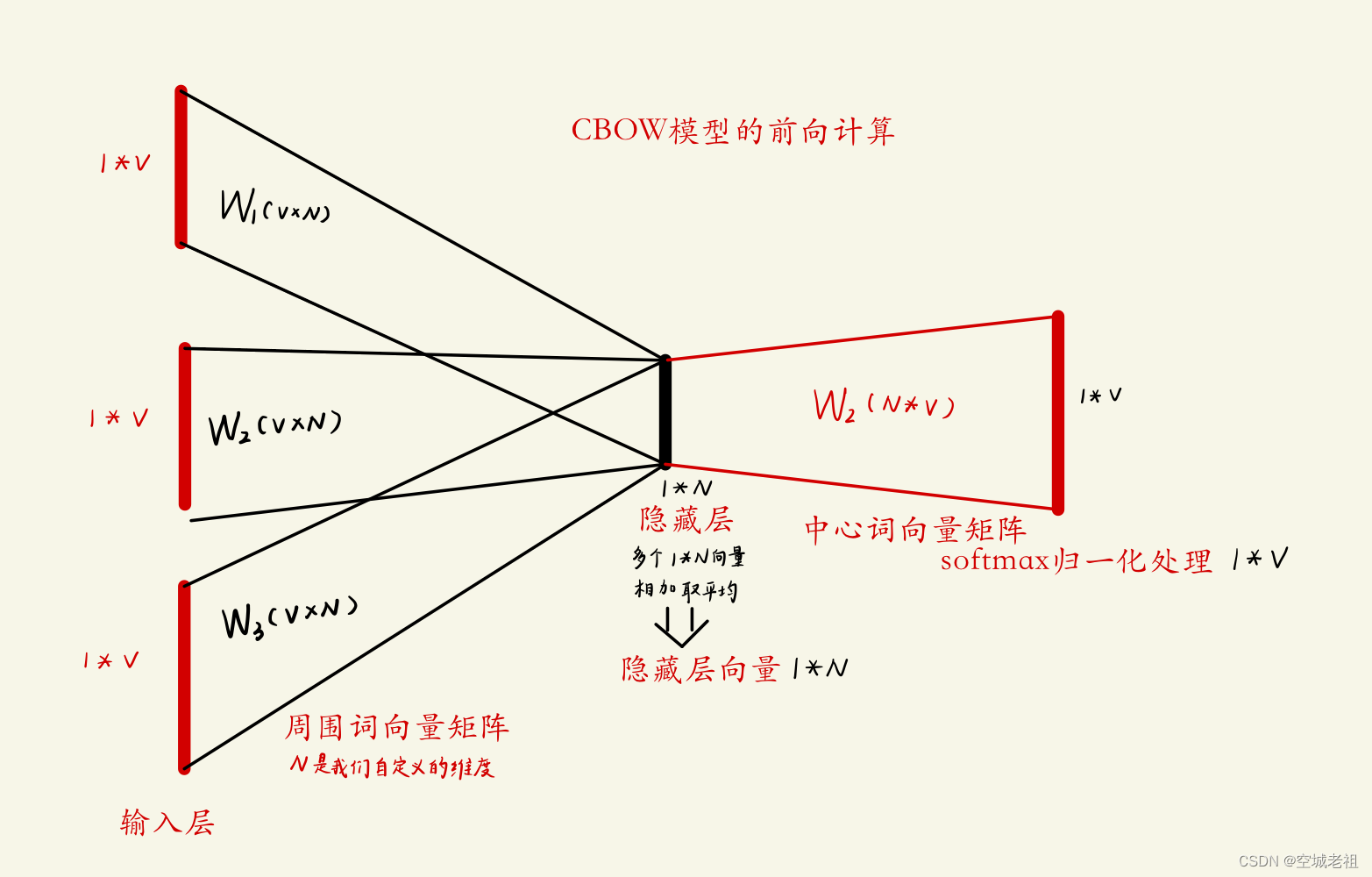
- 当前词的上下文词语的one-hot编码输入到输入层
- 这些词分别乘以同一个矩阵
周围词向量矩阵)后分别得到各自的1 ∗ N 向量
- 将这些1 ∗ N 向量取平均为一个1 ∗ N 向量
- 将这个1 ∗ N 向量乘矩阵W2 ,变成一个1 ∗ V向量
- 将1 ∗ V 向量softmax归一化后输出取每个词的概率向量1 ∗ V
- 将概率值最大的数对应的词作为预测词
- 将预测的结果1 ∗ V 向量和真实标签1 ∗ V向量(真实标签中的V个值中有一个是1,其他是0)计算误差,一般是交叉熵
- 在每次前向传播之后反向传播误差,不断调整
矩阵的值
你可能会想,word2vec不是要将词转为分布式表示的词嵌入么?怎么变成预测中心词了?
其实我们在做CBOW时,最终要的是这个V ∗ N 矩阵,想想这是为什么呢?
因为我们是要将词转换为分布式表示的词嵌入,我们先将词进行one-hot编码,每个词的向量表示是1 ∗ V 的,经过乘以 后,根据矩阵乘法的理解,假设1 ∗ V 向量中第 n 位是1,其他是0,则矩阵乘法结果是得到了
矩阵中的第n行结果,也就是将词表示为了一个1 ∗ N 的向量,一般N 远小于V ,这也就将长度为V 的one-hot编码稀疏词向量表示转为了稠密的长度为N 的词向量表示。
3、 skip-gram模型
skip-gram模型的概念是在每一次迭代中都取一个词作为中心词汇,尝试去预测它一定范围内的上下文词汇。连续词袋模型与skip-gram模型类似,最大的不同在于,连续词袋模型假设基于某中心词在文本序列前后的背景词来生成该中心词。
例如:‘我’,‘爱’,‘红色’,‘这片’,‘土地’,窗口大小为2,就是用‘我’,‘爱’,‘这片’,‘土地’这四个背景词,来预测生成 ‘红色’ 这个中心词的条件概率,即: P(红色|我,爱,这片,土地)
我们接下来说说模型的训练过程。(前向传播)
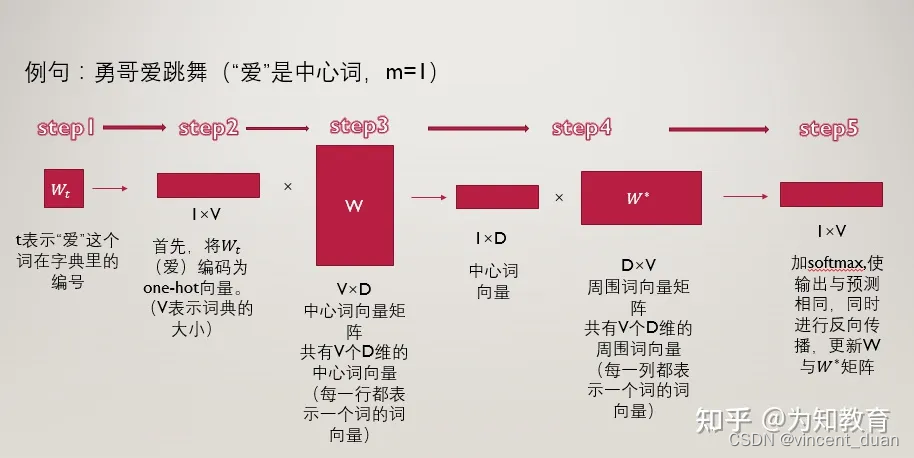
- 将“爱”这个词首先表示为one-hot编码输入到输入层。
- 接下来我们构建两个参数矩阵,分别为中心词矩阵和周围词矩阵,这两个矩阵分别是V × N 维和N × V 维,其中V 跟介绍CBOW模型一样,表示词典的大小,N 表示我们要构建的词向量的维度,是一个超参数,我们暂时认为其是固定的,不去管它。以中心词矩阵为例,其为V × N 维的,而我们的词表里一共有V 个词,也就是说,该矩阵的每一行都表示一个单词的中心词向量(低维、稠密的),同理,周围词向量矩阵是N × V 维的,每一列表示一个单词的周围词向量表示。
- 用第二步中的得到的,“爱”的one-hot编码乘以中心词向量矩阵
- 用该中心词向量乘以周围词向量矩阵
- 对于最终的得到的向量,我们再进一步的做softmax归一化,归一化之后的概率越大,表示该词与“爱”的相关性越大,现在我们的目标就是要使得:“北京”这个词的概率较大,我们如何去实现这个目标呢?那就是通过调整参数矩阵
- 对于“爱”这个词,我们要迭代两次,第一次是使得“我”这个词的概率尽量大,第二次使得“北京”这个词的概率尽量大。然后“爱”这个词迭代完了之后,我们再去遍历这个词表里的所有词,通过一次次的迭代,逐步降低损失函数。
4、实验
word2vec实验![]() https://github.com/KongChengCode/2203Guet/blob/master/word2vec/word2vecByMyself.ipynb
https://github.com/KongChengCode/2203Guet/blob/master/word2vec/word2vecByMyself.ipynb
参考文献















 7421
7421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









