







一、第一章 绪论
1.1引言
1.2基本术语
表示包含m个样本(示例)的数据集,每个样本由d个特征(属性)描述,其中每个样本
是d维样本空间X的中的一个向量,故一个样本也称为一个特征向量,d是样本
的维数。
- 用于训练过程中的数据称为训练数据,训练样本组成的集合称为训练集。模型有时也称为学习器,可看作学习算法在给定数据和参数空间上的实例化,学习过程是为了找出或逼近真相(ground-truth)。
- 除了有示例数据之外,还需要示例结果——“好瓜”与“坏瓜”,即标记(label)。拥有label的
称为样例,表示第i个样例,其中
是示例
是所有标记的集合,称为“标记空间”或“输出空间”。
- 若预测的是连续值,则称此类学习任务为“回归”;若预测的是离散值,则称此类学习任务为“分类”,分类可分为二分类和多分类。预测任务旨在通过训练集进行学习,建立一个从输入空间X到输出空间Y的映射。被预测的样本为测试样本,其集合称为测试集。
- 根据标记信息(label)的有无,学习任务大致可分为两大类:监督学习和无监督学习。回归与分类属于前者,聚类(将训练集按照某种标准划分为若干组,每组都有某种相似特性)属于后者。
- 模型适用于新样本的能力称为“泛化能力”。一般来说,训练集越大,模型学习的关于未知分布D(假设样本空间全体样本服从该分布)的信息越多,其泛化能力强的可能性越大。
1.3假设空间
该小节对我来说有点晦涩,按照我的理解,将“瓜”的一个样本,一个特征向量,例如(色泽=,根蒂=,敲声=)的一个取值视为一个假设,所有可能取值组合成一个假设空间。模型要做的就是在学习过程中根据训练集一步步搜索每个假设,删除不对的假设,最终的得到一个和训练集一致,即能判断所有训练样本的假设。
此外,原文中写到“搜索过程中可以不断删除与正例不一致的假设、和(或)与反例一致的假设”。应该是说三种方式,一是删除与正例不一致且和反例一致的假设,二是只删除与正例不一致的假设,三是只删除与反例一致的假设。书中采取的应该是第一种,最终版本空间中有三个假设,这三个假设每一个都可以判断书中数据集的每一个样本是好瓜还是坏瓜,但是不同的假设判断新的数据结果却可能不同。至于选哪一个假设来判断新数据,属于“归纳偏好”问题。
1.4归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”。该小节提到要根据具体问题判断算法的相对优劣,NFL定理让我们意识到脱离具体问题,谈什么算法更好是毫无意义的。
1.5发展历程
从样例中学习涵盖了监督学习、无监督学习等,在二十世纪八十年代,符号主义学习(代表算法:决策树)和基于神经网络的连接主义学习是其两大主流技术。二十世纪九十年代中期,统计学习成为主流,代表算法是支持向量机(SVM)以及更一般的“核方法”。二十一世纪初,连接主义学习卷土重来,深度学习开始蓬勃发展。
二、第二章 模型评估与选择
2.1经验误差与过拟合
- 学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称为“泛化误差”。
- 若学习器把训练样本学得过于优越,很可能把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,也就是说错误的把训练集本身的特性当作所有数据的一般特性,这样就会导致泛化性能下降,该现象称为“过拟合”,反之就是“欠拟合”。下图为西瓜书中过拟合与欠拟合的直观类比。

2.2评估方法
- 假设测试集是从样本真实分布中独立同分布采样得到,且尽可能与训练集互斥,可将学习器在测试集上的测试误差作为泛化误差的近似,来评估学习器对新样本的判别能力。
- 通过对数据集D采取适当的处理,从中产生训练集S和测试集T。一般有以下几种方法:
(1)留出法:直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T。需要注意两个问题,一是训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响;二是即便在给定训练/测试集的样本比例后,仍存在多种划分方式对初始数据集D进行分割,一般采用若干次随机划分、重复进行实验评估后去平均值作为留出法的评估结果。
(2)交叉验证法:“交叉验证法”先将数据集D划分为k个大小相似的互斥子集,即。每个子集都尽可能保持数据分布的一致性,即从D中分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集。这样就可获得k组训练/测试集,从而可进行k次训练和测试。最终返回的是这k个测试结果的均值。通常把交叉验证法称为“k折交叉验证”,k常用取值为10。下图为西瓜书中10折交叉验证示意图。
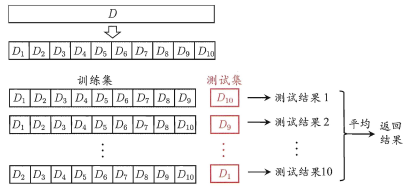
k折交叉验证通常要随机使用不同的划分重复p次,最终的评估结果是这p次k折交叉验证结果的均值,例如常见的有“10次10折交叉验证”。此外,交叉验证法还有个特例——留一法。
(3)自助法:以自助采样法为基础,在给定包含m个样本的数据集D,我们对它进行采样产生数据集D1:每次随机从D中挑选一个样本,将其拷贝放入D1,然后将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被猜到,重复操作m次,就得到包含m个样本的数据集D1.约有36.8%的样本不会出现在D1中,可将D1作为训练集,D\D1作为测试集。不过,在初始数据量足够时,留出法和交叉验证法更常用一些。
- 调参与最终模型:算法一般有许多参数需要配置,而调参对最终模型的性能的重要性不言而喻,有关键性影响。此外,在对比不同算法的泛化性能时,用测试集上的判别效果来估计模型在实际使用时的泛化能力,而把训练数据另外划分为训练集和验证集,基于验证集上的性能来进行模型选择和调参。
2.3性能度量
回归任务中常用的性能度量是“均方误差”,如下所示:
|
|
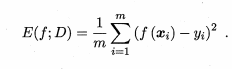
该节主要介绍分类任务中常用的性能度量
2.3.1错误率与精度
错误率是分类错误的样本数占样本总数的比例,如下所示:
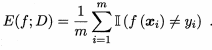
精度是分类正确的样本数占样本总数的比例,如下所示:
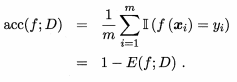
2.3.2查准率、查全率与F1
- 对于二分类问题,样例根据其真实类别和预测类别的组合可划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四类,分别用TP、FP、TN、FN表示,四类数量总和等于样例总数。分类结果混淆矩阵如下表所示。
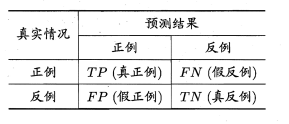
查准率P(precision)定义如下
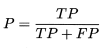
查全率R(recall)定义如下
![]()
简单来说,查准率是指算法选出的西瓜中好瓜占了多少比例,查全率是指全部好瓜中有多少比例被算法选出(算法选出的西瓜是指算法预测结果为好瓜的西瓜)。查准率和查全率是一对矛盾的度量,通常来说,查准率高时,查全率低;而查全率高时,查准率往往偏低。
若希望西瓜中的好瓜可能多被选出(即希望查全率高),则可以极端点让算法选出所有西瓜,这样好瓜必然包含在内(查全率等于100%,因为此时只有TP和FP),但这样查准率必然会较低,因为此时TP+FP与TP均变大,而前者变大的程度比后者高。
若希望算法选出的好瓜比例尽可能高(即希望查准率高),则可只挑选最有把握的瓜(这样会减少选瓜的数量,即TP+FP减少),难免漏掉不少好瓜(TP也会减少),相比之下TP+FP减少的更快(因为有把握选好瓜),因此查准率变高。而查全率中TP+FN不变(好瓜总数不变),在TP减少的情况下,查全率变低。
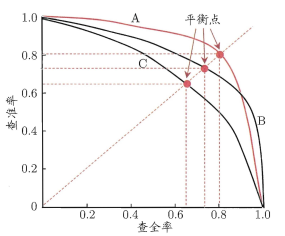
- P-R曲线以查准率为纵轴、查全率为横轴,其直观地显示出学习器在样本总体上的查全率、查准率。若一个学习器的P-R曲线被另一个学习器的曲线完全包裹,则后者性能优于前者。若两条曲线交叉,则可利用平衡点BEP(查准率=查全率时的取值)衡量优劣。下图为西瓜书中P-R曲线与平衡点示意图。
F1度量更为常用,其定义如下
![]()
F1还有一般形式——,其定义如下
![]()
其中B>0度量了查全率对查准率的相对重要性。B=1时退化为标准的F1;B>1时查全率有更大影响;B<1时查准率有更大影响。

2.3.3ROC与AUC
- ROC曲线以真正例率(TPR)为纵轴,以假正例率(FPR)为横轴,两者分别定义为

与P-R图相似,若一个学习器的ROC曲线被另一个学习器的曲线完全包裹,则后者性能优于前者。若两条曲线交叉,则可利用AUC(ROC曲线下的面积)衡量优劣。下图为西瓜书中ROC曲线与AUC示意图。
















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









