







1、引言
2、 非阻塞I/O
- 系统调用分为两类:低速系统调用和其他系统调用。低速系统调用是可能会使进程永远阻塞的一类系统调用,包括:
- 如果某些文件类型(如读管道、终端设备和网络设备)的数据并不存在,读操作可能使调用者永远阻塞。
- 如果数据不能被相同的文件类型立即接受(如管道中无空间、网络流控制),写操作可能会使调用者永远阻塞。
- 在某种条件发生之前打开某些文件类型可能会发生阻塞(例如以只写模式打开FIFO,那么在没有其他进程用读模式打开该FIFO时也要等待)
- 对已经加上强制性记录锁的文件进行读写
- 某些ioctl操作
- 某些进程间通信函数
- 非阻塞
I/O使我们可以发出open、read和write这样的I/O操作,并使这些操作不会永远阻塞。如果这种操作不能完成,则调用立即出错返回,表示该操作如果继续进行将阻塞。 - 对于一个非阻塞的描述符如果无数据可读,则
read返回-1,errno为EAGAIN。 - 非阻塞
I/O指的是文件状态标志,即与文件表项有关。会影响使用同一文件表项的所有文件描述符(即使属于不同的进程)。 - 注意,
read函数阻塞的情况:read函数只是一个通用的读文件设备的接口。是否阻塞需要由设备的属性和设定所决定。一般来说,读字符终端、网络的socket描述字,管道文件等,这些文件的缺省read都是阻塞的方式。如果是读磁盘上的文件,一般不会是阻塞方式的。但使用锁和fcntl设置取消文件O_NOBLOCK状态,也会产生阻塞的read效果。 - 对于一个给定的文件描述符,有两种方式为其指定非阻塞
I/O:- 如果用
open获得描述符,指定O_NONBLOCK标志 - 对于一个已经打开的文件描述符,则可调用
fcntl,由该函数打开O_NONBLOCK文件状态标志int flag = fcntl(fd, F_GETFL); //获取文件状态标志 flag |= O_NONBLOCK; int ret = fcntl(fd, F_SETFL, flag); //设置文件状态标志
- 如果用
- 实例: 一个非阻塞
I/O的实例。它从标准输入读50000个字节,并试图将它们写到标准输出上。该程序先将标准输出设置为非阻塞的,然后用for循环进行输出,每次write调用的结果都在标准错误上打印。其中set_fl函数的介绍见3.14节,get_fl函数则类似于set_fl函数。#include "apue.h" #include <errno.h> #include <fcntl.h> char buf[500000]; int main(void) { int ntowrite, nwrite; char *ptr; ntowrite = read(STDIN_FILENO, buf, sizeof(buf)); fprintf(stderr, "read %d bytes\n", ntowrite); set_fl(STDOUT_FILENO, O_NONBLOCK); /* set nonblocking */ ptr = buf; while (ntowrite > 0) { errno = 0; nwrite = write(STDOUT_FILENO, ptr, ntowrite); fprintf(stderr, "nwrite = %d, errno = %d\n", nwrite, errno); if (nwrite > 0) { ptr += nwrite; ntowrite -= nwrite; } } clr_fl(STDOUT_FILENO, O_NONBLOCK); /* clear nonblocking */ exit(0); }-
若标准输出是普通文件,则
write一般只调用一次。这里的文件/etc/services大小为19605字节,小于程序中的50000字节,所以写入的大小也为19605字节。如果文件大小大于50000字节,那么写入的大小为50000字节。lh@LH_LINUX:~/桌面/apue.3e/advio$ ls -l /etc/services -rw-r--r-- 1 root root 19605 10月 25 2014 /etc/services lh@LH_LINUX:~/桌面/apue.3e/advio$ ./nonblockw < /etc/services > temp.file read 19605 bytes nwrite = 19605, errno = 0 lh@LH_LINUX:~/桌面/apue.3e/advio$ ls -l temp.file -rw-rw-r-- 1 lh lh 19605 8月 9 13:15 temp.file -
若标准输出是终端,则有时返回数字,有时返回错误,下面是运行结果。

- 该系统上,
errno的值35对应的是EAGAIN。终端驱动程序一次能接受的数据量随系统而变。 - 在此实例中,程序发出了
9000多个write调用,但是只有500个真正输出了数据,其余的都只返回了错误。这种形式的循环称为轮询,在多用户系统上用它会浪费CPU时间。14.4节会介绍非阻塞描述符的I/O多路转换,这是进行这种操作的一种比较有效的方法。 - 有时,可以将应用程序设计成多线程的,从而避免使用非阻塞
I/O。如若我们能在其他线程中继续进行,则可以允许单个线程在I/O调用中阻塞。但线程间的同步的开销有时却可能增加复杂性,于是导致得不偿失的后果。
- 该系统上,
-
3、 记录锁
- 当两个人同时编辑一个文件时,该文件的最后状态取决于写该文件的最后一个进程。但是对于有些应用程序如数据库,进程有时需要确保它正在单独写一个文件。因此可以使用记录锁机制。
- 记录锁的功能:当第一个进程正在读或者修改文件的某个部分时,使用记录锁可以阻止其他进程修改同一文件区。
- 其实应该称记录锁为 “字节范围锁” ,因为它锁定的只是文件中的一个区域(也可能是整个文件)
3.1、历史
- 这部分的内容不重要,略过。
3.2、fcntl记录锁
-
3.14节已经给出了该函数的原型int fcntl(int fd, int cmd, ... /* struct flock * flockptr */ );- 与记录锁相关的
cmd是F_GETLK、F_SETLK、F_SETLKW。F_GETLK:- 判断由
flockptr描述的锁是否会被另外一把锁排斥(阻塞)。如果存在一把锁阻止创建flockptr描述的锁,则该现有锁的信息将重写flockptr指向的信息。如果不存在这种情况,除了l_type设置为F_UNLCK之外,flockptr指向的结构中其他信息不变。 - 注意由于调用进程自己的锁并不会阻塞自己的下一次尝试加锁(因为新锁将替换旧锁),因此
F_GETLK不会报告调用进程自己持有的锁信息。因此不能用它来测试自己是否在某一文件区域持有一把锁。
- 判断由
F_SETLK:- 设置由
flockptr所描述的锁(共享读锁或独占写锁)。如果失败fcntl函数立即出错返回,errno设置为EACCES或EAGAGIN
- 设置由
F_SETLKW:- 这个命令是
F_SETLK的阻塞版本(w表示等待wait)。如果所请求的读锁或写锁因另一个进程当前已经对所请求部分进行了加锁而不能被授予,那么调用进程休眠。如果请求创建的锁已经可用,或者休眠被信号中断,则该进程被唤醒。
- 这个命令是
- 第三个参数是一个指向
flock结构的指针。struct flock { short int l_type; /* 记录锁类型: F_RDLCK, F_WRLCK, or F_UNLCK. */ short int l_whence; /* SEEK_SET、SEEK_CUR、SEEK_END */ __off_t l_start; /* Offset where the lock begins. */ __off_t l_len; /* Size of the locked area; zero means until EOF. */ __pid_t l_pid; /* Process holding the lock. */ };- 对
flock结构说明如下:l_type:所希望的锁类型。F_RDLCK(共享读锁)、F_WRLCK(独占性写锁)、F_UNLCK(解锁一个区域)l_whence:指示l_start从哪里开始。SEEK_SET(开头)、SEEK_CUR(当前位置)、SEEK_END(结尾)l_start:要加锁或解锁区域的起始字节偏移量l_len:要加锁或解锁区域字节长度l_pid:仅由F_GETLK返回,表示该pid进程持有的锁能阻塞当前进程。
- 关于加锁和解锁区域的说明还要注意以下事项:
- 锁可以在当前文件尾端处开始或者越过尾端处开始,但是不能在文件起始位置之前开始。
- 如果
l_len为0,则表示锁的范围可以扩展到最大可能偏移量。这意味着不管向该文件中追加写了多少数据,它们都可以处于锁的范围内(不必猜测会有多少字节被追加写到了文件之后) - 为了对整个文件加锁,设置
l_start和l_whence指向文件起始位置,并且指定长度l_len为0。
- 对
- 与记录锁相关的
-
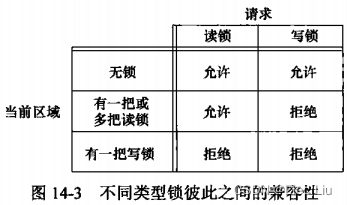
fcntl可以操作两种锁:共享读锁F_RDLCK和独占性写锁F_WRLCK- 任意多个进程在一个给定的字节上可以有一把共享的读锁
- 但是在一个给定字节上只能有一个进程有一把独占写锁。
- 如果在一个给定字节上已经有一把或多把读锁,则不能在该字节上再加写锁
- 如果在一个字节上已经有一把独占性写锁,则不能再对它加任何读锁。
- 如果一个进程对一个文件区间已经有了一把锁,后来该进程又企图在同一文件区间再加一把锁,那么新锁将替换已有锁。比如一个进程在某文件的
16-32字节区间有一把写锁,然后又试图在16-32字节区间加一把读锁,那么该请求成功执行,原来的写锁替换为读锁。 - 加读锁时,描述符必须是读打开;加写锁时,描述符必须是写打开。
-
需要注意以下两点:
- 用
F_GETLK测试能否建立一把锁,然后用F_SETLK或F_SETLKW企图建立那把锁,这两者不是一个原子操作。不能保证两次fcntl调用之间不会有另一个进程插入并建立一把锁 POSIX没有说明下列情况会发生什么:- 第一个进程在某文件区间设置一把读锁,第二个进程试图在同一文件区间加一把写锁时阻塞,然后第三个进程则试图在同一文件区间设置另一把读锁。如果允许第三个进程获得读锁,那么这种实现容易导致希望加写锁的进程饿死。
- 用
-
文件记录锁的组合和分裂
- 在设置或释放文件上的一把锁时,系统按照要求组合或分裂相邻区。
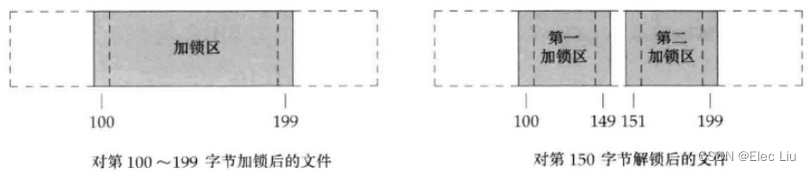
- 例如在
100-199字节是加锁区域,当需要解锁第150字节时,则内核将维持两把锁:一把用于100-149字节;另一把用于151-199字节。 - 如果我们又对第
150字节加锁,那么系统会把相邻的加锁区合并成一个区(100-199字节),和开始时又一样了。
- 例如在
- 在设置或释放文件上的一把锁时,系统按照要求组合或分裂相邻区。
-
实例:请求和释放一把锁。为了每次都避免分配
flock结构,然后又填入各项信息,可以用下图程序中的lock_reg来处理这些细节。

- 因为大多数锁调用时加锁或解锁一个文件区域(命令
F_GETLK很少使用),故通常使用下列5个宏中的一个。这5个宏都定义在apue.h中(见附录B)

- 因为大多数锁调用时加锁或解锁一个文件区域(命令
-
实例:测试一把锁。如果存在一把锁,它阻塞由参数指定的锁请求,则此函数返回持有这把现有锁的进程的进程
ID,否则此函数返回0。

- 通过用下面两个宏来调用此函数(它们也定义在
apue.h中)

- 注意,进程不能使用
lock_test函数测试它自己是否在文件的某一部分持有一把锁。F_GETLK命令的定义说明,返回信息指示是否有现有的锁阻止调用进程设置它自己的锁。因为F_SETLK和F_SETLKW命令总是替换调用进程现有的锁(若已存在),所以调用进程绝不会阻塞在自己持有的锁上。于是,F_GETLK命令绝不会报告调用进程自己持有的锁。
- 通过用下面两个宏来调用此函数(它们也定义在
-
实例:死锁。该例中子进程对第
0字节加锁,父进程对第1字节加锁。然后,它们中的每一个又试图对对方已经加锁的字节加锁。 程序中介绍了8.9节中介绍的父进程和子进程同步例程。#include "apue.h" #include <fcntl.h> static void lockabyte(const char *name, int fd, off_t offset) { if (writew_lock(fd, offset, SEEK_SET, 1) < 0) err_sys("%s: writew_lock error", name); printf("%s: got the lock, byte %lld\n", name, (long long)offset); } int main(void) { int fd; pid_t pid; /* * Create a file and write two bytes to it. */ if ((fd = creat("templock", FILE_MODE)) < 0) err_sys("creat error"); if (write(fd, "ab", 2) != 2) err_sys("write error"); TELL_WAIT(); /*set things up for TELL_xxx & WAIT_xxx */ if ((pid = fork()) < 0) { err_sys("fork error"); } else if (pid == 0) { /* child */ lockabyte("child", fd, 0); TELL_PARENT(getppid()); /*tell parent we're done */ WAIT_PARENT(); /*and wait for parent*/ lockabyte("child", fd, 1); } else { /* parent */ lockabyte("parent", fd, 1); TELL_CHILD(pid); /*tell child we're done */ WAIT_CHILD(); /*and wait for parent*/ lockabyte("parent", fd, 0); } exit(0); }运行该实例可以得到
lh@LH_LINUX:~/桌面/apue.3e/advio$ ./deadlock parent: got the lock, byte 1 child: got the lock, byte 0 parent: writew_lock error: Resource deadlock avoided child: got the lock, byte 1- 检测到死锁时,内核必须选择一个进程接收出错返回。在本实例中,选择了父进程。选择父进程还是子进程出错返回随操作系统而定。
3.3、锁的隐含继承和释放
- 关于记录锁的自动继承和释放有3条规则。
- 锁与进程和文件两者相关联:当一个进程终止时,它所建立的锁全部释放;无论一个描述符何时关闭,该进程通过这一描述符引用的文件上的任何一把锁都会释放(这些锁都是该进程设置的)。
- 例如,在
close(fd)后,在fd1设置的锁被释放。dup函数的使用方法见3.12节fd1 = open(pathname, ...); read_lock(fd1, ...); fd2 = dup(fd1); close(fd2); - 如果
dup替换成open,其效果也一样:fd1 = open(pathname, ...); read_lock(fd1, ...); fd2 = open(fd1); close(fd2);
- 例如,在
- 由
fork产生的子进程不继承父进程所设置的锁。因为对于父进程获得的锁而言,子进程被视为另一个进程。 - 执行
exec后,新程序可以继承原执行程序的锁。但是如果该文件描述符设置了close-on-exec标志,则exec之后释放相应文件的锁。
- 锁与进程和文件两者相关联:当一个进程终止时,它所建立的锁全部释放;无论一个描述符何时关闭,该进程通过这一描述符引用的文件上的任何一把锁都会释放(这些锁都是该进程设置的)。
3.4、FreeBSD实现
- 考虑一个进程,他执行下列语句(忽略出错返回)
在父进程和子进程暂停(执行fd1 = open(pathname,...); write_lock(fd1,0,SEEK_SET,1); // 该函数是自定义的,父进程在字节0上设置写锁 if((pid = fork()) > 0) { // 父进程 fd2 = dup(f1); fd3 = open(pathname,...); } else if(pid == 0) { // 子进程 read_lock(fd1,1,SEEK_SET,1); //该函数是自定义的,子进程在字节1上设置读锁 } pause();pause())之后,数据结构的情况如下
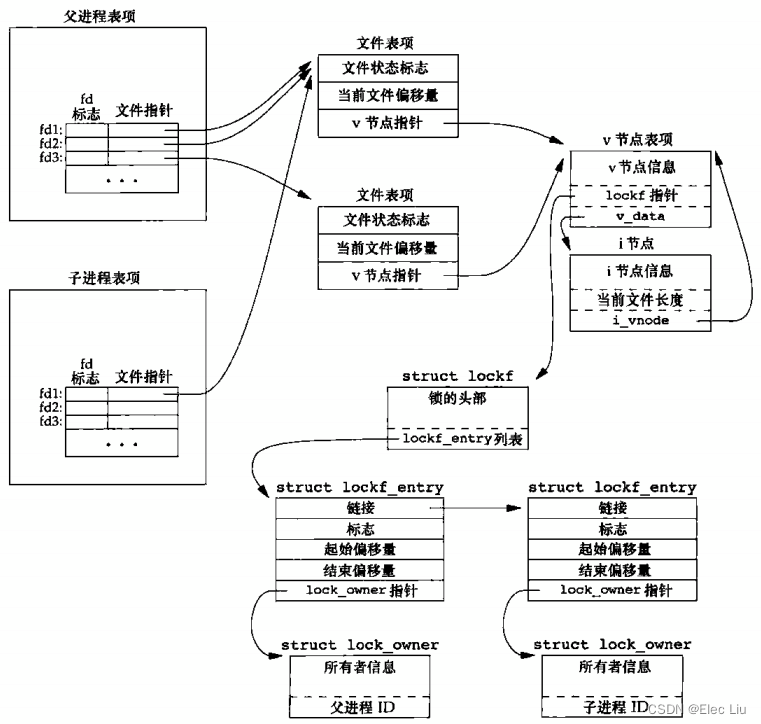
- 可以看出来,文件记录锁信息是保存在文件
v节点/inode节点上的(而不是在文件表项中的),其实现是通过一个链表记录该文件上的各个锁,因此能保证多个进程正确操作文件记录锁。在图中显示了两个lockf结构,一个是由父进程调用write_lock形成的,另一个则是子进程调用read_lock形成的。每一个结构都包含了相应的进程ID。 - 在父进程中,关闭
fd1、fd2、fd3中的任意一个都将释放由父进程设置的写锁。内核会从该描述符锁关联的inode节点开始,逐个检查lockf链表中的各项,并释放由调用进程持有的各把锁。
- 可以看出来,文件记录锁信息是保存在文件
- 实例:守护进程可用一把文件锁来保证只有该守护进程的唯一副本在运行,其
lockfile函数实现如下:守护进程可用该函数在文件整体上加独占写锁。
另一种方法是int lockfile(int fd) { struct flock fl; fl.l_type = F_WRLCK; fl.l_start = 0; fl.l_whence = SEEK_SET; fl.l_len = 0; return fcntl(fd,F_SETLK,&fl); }write_lock函数定义lockfile函数:#define lockfile(fd) write_lock((fd),0,SEEK_SET,0)
3.5、在文件的尾端加锁
- 在对相对于文件尾端的字节范围加锁解锁必须特别小心。如下面代码:
write_lock(fd,0,SEEK_END,0); write(fd,buf,1); un_lock(fd,0,SEEK_END); write(fd,buf,1);- 刚开始获得一把写锁,该锁从当前文件尾开始,包括以后可能追加写到该文件的任何数据。当文件偏移量处于文件尾时,
write一个字节将文件延伸了一个字节,因此该字节被加写锁。 - 但是其后的解锁是对当前文件尾开始包括以后可能追加写到该文件的任何数据进行解锁,因此刚才追加写入的一个字节保留加锁状态。之后又写入了一个字节,由此代码造成的文件锁状态如图。
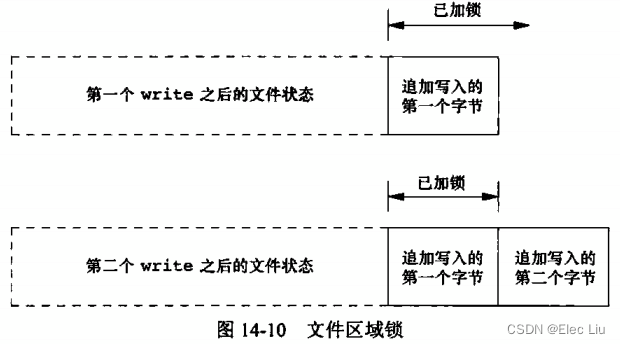
- 刚开始获得一把写锁,该锁从当前文件尾开始,包括以后可能追加写到该文件的任何数据。当文件偏移量处于文件尾时,
3.6、建议性锁和强制性锁
- 建议性锁
- 每个使用文件的进程都要主动检查该文件是否有锁存在,当然都是通过具体锁的
API,比如fcntl记录锁F_GETTLK来主动检查是否有锁存在。如果有锁存在并被排斥,那么就主动保证不再进行接下来的I/O操作。如果每一个进程都主动进行检查,并主动保证,那么就说这些进程都以一致性的方法处理锁。 - 但是这种一致性方法依赖于编写进程程序员的素质,也许有的程序员编写的进程程序遵守这个一致性方法,有的不遵守。不遵守的程序员编写的进程程序会怎么做呢?也许会不主动判断这个文件有没有加上文件记录锁,就直接对这个文件进行IO操作(例如某个拥有写权限的进程在不判断是否有锁的情况下直接写入该文件)。此时这种有破坏性的IO操作会不会成功呢?如果是在建议性锁的机制下,这种破坏性的IO就会成功。因为锁只是建议性存在的,并不强制执行。内核和系统总体上都坚持不使用建议性锁机制,它们依靠程序员遵守这个规定。(
Linux默认是采用建议性锁)
- 每个使用文件的进程都要主动检查该文件是否有锁存在,当然都是通过具体锁的
- 强制性锁
-
对一个特定文件打开其设置组
ID位、关闭其组执行位便开启了对该文件的强制性锁机制。因为当组执行位关闭时,设置组ID位不再有意义,因此定义以这两者组合来指定该文件的锁是强制性的而不是建议性的。 -
强制性锁机制是这样规定的:建议性锁中提到的破坏性
I/O操作可能会被内核禁止(即在该文件范围存在锁时强行进行I/O操作)。强制性锁会让内核检查每一个open、read、write操作,如果这些操作违背了该文件上的某一把锁,则I/O操作会被禁止(阻塞或直接出错返回)。也就是强制性锁机制,让锁变得名副其实,真正达到了锁的效果,而不是像建议性锁机制那样只是个纸老虎。 -
如下图所示,当一个进程试图
read、write一个强制性锁起作用的文件,而欲读、写的部分又由其他进程加上了锁,那么结果取决于三个方面:- 操作类型:
read或write - 其他进程持有的锁类型:共享读锁或独占写锁
read或write该描述符是阻塞还是非阻塞的。

- 操作类型:
-
注意,对于
open函数,即使正在打开的文件具有强制性记录锁,该open也会成功。随后的read或write依从与上图所示规则。除非open以O_TRUNC打开该文件,那么open出错返回,因为如果另一个进程拥有它的读锁或写锁,那么该文件就不能被截断为0。 -
回到最初的问题,如果两个人同时编辑同一个文件时将会怎样?一般的UNIX文本编辑器不使用记录锁,因此该文件的最后结果取决于写该文件的最后一个进程。但是如果该UNIX文本编辑器支持记录锁则不会是这样,具体结果会根据上面具体介绍的内容。
-
- 实例:确定一个系统是否支持强制性锁机制。
#include "apue.h" #include <errno.h> #include <fcntl.h> #include <sys/wait.h> int main(int argc, char *argv[]) { int fd; pid_t pid; char buf[5]; struct stat statbuf; if (argc != 2) { fprintf(stderr, "usage: %s filename\n", argv[0]); exit(1); } if ((fd = open(argv[1], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) < 0) err_sys("open error"); if (write(fd, "abcdef", 6) != 6) err_sys("write error"); /* turn on set-group-ID and turn off group-execute */ if (fstat(fd, &statbuf) < 0) err_sys("fstat error"); if (fchmod(fd, (statbuf.st_mode & ~S_IXGRP) | S_ISGID) < 0) err_sys("fchmod error"); TELL_WAIT(); if ((pid = fork()) < 0) { err_sys("fork error"); } else if (pid > 0) { /* parent */ /* write lock entire file */ if (write_lock(fd, 0, SEEK_SET, 0) < 0) err_sys("write_lock error"); TELL_CHILD(pid); if (waitpid(pid, NULL, 0) < 0) err_sys("waitpid error"); } else { /* child */ WAIT_PARENT(); /* wait for parent to set lock */ set_fl(fd, O_NONBLOCK); /* first let's see what error we get if region is locked */ if (read_lock(fd, 0, SEEK_SET, 0) != -1) /* no wait */ err_sys("child: read_lock succeeded"); printf("read_lock of already-locked region returns %d\n", errno); /* now try to read the mandatory locked file */ if (lseek(fd, 0, SEEK_SET) == -1) err_sys("lseek error"); if (read(fd, buf, 2) < 0) err_ret("read failed (mandatory locking works)"); else printf("read OK (no mandatory locking), buf = %2.2s\n", buf); } exit(0); }- 该程序首先创建一个文件,并使强制性锁对其起作用。然后程序分出一个父进程和一个子进程。父进程对整个文件设置一把写锁,子进程则先对该文件的描述符设置为非阻塞的,然后企图对该文件设置一把读锁,我们期望这会出错返回,并希望看到系统返回的是
EAGAIN或EACESS。接着,子进程将文件读、写位置调整到文件起点,并试图读(read)该文件。如果系统提供强制性锁,则read应返回EAGAIN或EACESS(因为该描述符是非阻塞的),否则read返回所读的数据。 - 命令行运行结果如下:
- 若在
Solaris 10上运行该程序(该系统支持强制性建议锁),将得到:

- 其中的
errno值11对应EAGAIN。
- 其中的
- 若在
FreeBSD 8.0上运行该程序,将得到:

- 其中的
errno值35对应EDEADLK,该系统不支持强制性锁。
- 其中的
- 若在
- 该程序首先创建一个文件,并使强制性锁对其起作用。然后程序分出一个父进程和一个子进程。父进程对整个文件设置一把写锁,子进程则先对该文件的描述符设置为非阻塞的,然后企图对该文件设置一把读锁,我们期望这会出错返回,并希望看到系统返回的是
4、I/O多路转换
- 当从一个描述符读,然后又写到另一个描述符时,可以在下列形式的循环中使用阻塞
I/Owhile((n = read(STDIN_FILENO,buf,BUFSIZ) > 0) { if(write(STDOUT_FILENO,buf,n) != n) err_sys("write error"); } - 考虑这种情况:要从两个描述符读,如果每个文件描述符都采用以上方式进行阻塞读,那么可能会因为被阻塞在一个描述符的读操作上而导致另一个描述符也无法处理。处理这种问题可以考虑用多进程、多线程、非阻塞I/O、异步I/O进行解决,但是都有各种限制。
- 因此可以使用
I/O多路转接技术:先构造一张我们感兴趣的描述符列表,然后调用一个函数,直到这些描述符中的一个已准备好进行I/O时,该函数才返回。poll、pselect、select、epoll函数可以使我们能够进行I/O多路转接。这些函数返回时,进程告诉我们哪些文件描述符已经准备好可以进行I/O
4.1、函数select和pselect
-
select可以进行I/O多路转接。传给select的参数告诉内核:- 我们所关心的描述符
- 对于每个描述符我们关心的条件(读、写、异常条件)
- 愿意等待多久
-
而
select返回时告诉我们:- 已准备好的描述符总数量
- 对于读、写、异常这三个条件,哪些描述符已经准备好
-
使用这些返回信息,就可调用相应的
I/O函数(一般是read和write),并且确知该函数不会阻塞。int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout); //返回准备就绪的描述符数目- 参数
nfds:- 最大文件描述符值+1。即为三个描述符集合中最大描述符编号+1(因为描述符编号从0开始)。通过该参数,内核就在此范围内寻找三个描述符集中打开的位,而不用在描述符集中的数百个没有使用的位内搜索。
- 参数
readfds/writefds/exceptfds- 指向描述符集
fd_set,我们它只是一个很大的字节数组。
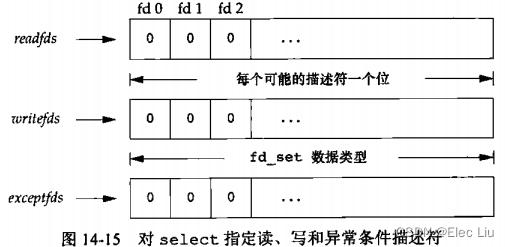
- 这三个集合说明了我们关心的可读、可写或处于异常条件的描述符集合。对于这个
fd_set描述符集合类型,可以使用以下函数进行操作:void FD_SET(int fd,fd_set* fdsetp); // 开启描述符集中的一位 void FD_CLR(int fd,fd_set* fdsetp); // 清除描述符集中的一位 int FD_ISSET(int fd,fd_set* fdsetp); // 测试描述符集中一位是否打开 void FD_ZERO(fd_set* fdsetp); // 将描述符集中所有位置0- 这些接口可以被实现为宏或函数。在创建一个
fd_set对象后,一定要使用FD_ZERO将这个描述符集置0。 - 当
select函数返回时,这三个描述符集将包含了所有满足条件的描述符,此时可以用FD_ISSET进行测试。
- 这些接口可以被实现为宏或函数。在创建一个
- 指向描述符集
- 参数
timeout:timeout == NULL:永远等待。当所指定的描述符中的一个已准备好或捕捉到一个信号则返回。如果捕捉到一个信号,返回-1,errno设为EINTR。timeout->tv_sec == 0 && timeout->tv_usec == 0:不等待,测试指定的描述符并立即返回timeout->tv_sec!=0 || timeout->tv_usec!=0:等待指定时间。当指定的描述符之一准备好,或指定时间超时时返回。如果超时时还没有一个描述符准备好则返回0。如果捕捉到一个信号则被中断返回-1。若在等待时间尚未到期时select返回,那么将用剩余时间值更新该结构。
- 返回值:
-1:出错(如捕捉到信号中断)。此时三个描述符集都不修改0:超时后没有描述符准备好。此时三个描述符集都置0>0:已经准备好的描述符数。此数字是三个描述符集中已准备好的描述符数目之和,所以如果同一描述符已准备好读和写,则返回值中对其计两次数。三个描述符集中仍然打开的位对应于已准备好的描述符。
- 对于文件描述符“准备好”的含义:
- 若对读集中的一个描述符进行
read操作不会阻塞 ,则认为此描述符是读准备好的。 - 若对写集中的一个描述符进行
write操作不会阻塞 ,则认为此描述符是写准备好的。 - 若对异常条件集中的一个描述符有一个未决异常条件,则认为此描述符是准备好的。这些异常条件包括:网络连接上到达的带外数据、处于数据包模式的伪终端上发生了某些条件
- 对于读、写、异常条件,普通文件的文件描述符总是返回准备好。注意,在一个描述符上碰到了文件尾端,则
select认为该描述符可读,然后调用read返回0,这是UNUX系统指示到达文件尾端的方法。
- 若对读集中的一个描述符进行
- 参数
-
pselect是select函数的变体int pselect(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, const struct timespec *timeout,const sigset_t *sigmask);- 除了以下几点,
pselect和select相同- 超时使用
timespec结构,提供纳秒级别精度 - 超时参数为
const类型,若未超时就返回,pselect并不会改变此值。 - 可使用可选信号屏蔽字。若
sigmask参数为NULL则和select相同;否则sigmask指向一信号屏蔽字,在调用pselect时,安装该信号屏蔽字,函数返回前恢复以前的信号屏蔽字。
- 超时使用
- 除了以下几点,
5、异步I/O
5.1、System V 异步I/O
5.2、 BSD 异步I/O
5.3、 POSIX 异步I/O
-
POSIX异步I/O接口为对不同类型的文件进行异步I/O提供了一套一致的方法,这些异步I/O接口使用AIO控制块来描述I/O操作。
aiocb结构定义了AIO控制块,它至少包括以下字段:/* Asynchronous I/O control block. */ struct aiocb { int aio_fildes; /* 被打开用来读写的文件描述符 */ off_t aio_offset; /* 读写操作从该偏移量开始 */ int aio_lio_opcode; /* 仅被 lio_listio() 函数使用 */ int aio_reqprio; /* 请求优先级 */ volatile void * aio_buf; /* 对于读操作,数据复制到该缓冲区;对于写操作,数据从该缓冲区中复制出来 */ size_t aio_nbytes; /* 要读写的字节数 */ struct sigevent aio_sigevent; /* I/O事件完成后如何通知程序 */ };- 注意,异步
I/O操作必须显式的指定偏移量aio_offset,因为异步I/O接口并不影响(或使用)由操作系统维护的文件表项中记录的偏移量。 - 如果使用异步
I/O向一个以追加模式(O_APPEND)open的文件中写入数据,则aio_offset字段被忽略。 aio_reqprio字段是异步I/O请求提示顺序(请求优先级)。但是系统对于该顺序只有有限的控制力,即不一定遵循。aio_lio_opcode字段只能用于基于列表的异步I/O(仅被lio_listio()函数使用)aio_sigevent字段控制I/O事件完成后,如何通知应用程序,通过sigevent结构体描述struct sigevent { int sigev_signo; /* 通知的信号编号 */ int sigev_notify; /* 通知类型 */ union sigval sigev_value; /* 通知参数 */ void(*sigev_notify_function)(union sigval); /* 通知函数 */ pthread_attr_t * sigev_notify_attributes; /* 线程属性 */ };sigev_notify字段:
控制通知的类型,取值为以下三个中的一个SIGEV_NONE:异步I/O请求完成后,不通知进程SIGEV_SIGNAL:异步I/O请求完成后,产生由sigev_signo字段指定的信号。如果应用程序要捕获该信号,且在sigaction时指定了SA_SIGINFO标志,那么该信号将被入队(如果支持排队信号)。信号处理程序sa_sigaction中第二个参数siginfo_t中的si_value字段值被置为sigev_value。SIGEV_THREAD:当异步I/O请求完成时,调用sigev_notify_function函数。该函数的sigval参数值为sigev_value。系统会自动将该函数在分离状态下的一个单独的线程中执行(该线程的属性是sigev_notify_attributes)。
- 注意,异步
-
aio_read和aio_write函数- 在初始化了
aiocb结构体后,就可以调用aio_read函数来进行异步读操作,或调用aio_write函数来进行异步写操作。/*对 aiocbp 描述的异步I/O 请求进行排队。这个函数是 read(2) 的异步模拟。*/ int aio_read(struct aiocb *aiocbp); /*对由 aiocbp 描述的异步 I/O 请求进行排队。此函数是 write(2) 的异步模拟*/ int aio_write(struct aiocb *aiocbp);- 当函数返回成功时,异步
I/O请求便已经被操作系统放入等待处理的队列中了。 - 这些返回值与实际
I/O操作的结果没有任何关系。 I/O操作在等待时,必须保证aiocb对象中的缓冲区等资源始终是可用的。
- 当函数返回成功时,异步
- 在初始化了
-
aio_fsync函数- 如果想强制(排队中)等待的异步操作不等待,而直接写入持久化的存储中,可以建立一个
AIO控制块并调用aio_fsync函数。 - 注意,同
aio_read和aio_write一样,该函数只是一个请求(即一个同步请求),它并不等待I/O结束(只是将同步请求入队),而是立即返回int aio_fsync(int op, struct aiocb *aiocbp);aiocbp参数- 其中的
aio_fildes字段指定了要同步的异步写操作的文件。 - 除去由
aiocbp指向的结构体成员aio_fildes之外唯一被本函数使用成员是aio_sigevent,这个成员指出在操作完成时希望收到哪种异步通知。所有其它字段都被忽略。
- 其中的
op参数O_DSYNC:所有当前在队的异步I/O操作好比调用了fdatasync(2)一样将会完成O_SYNC:所有当前在队的 异步I/O操作好比调用了fsync(2)一样将会完成
- 同
aio_read和aio_write一样,在安排了同步后(即同步请求成功排队),aio_fsync函数立即返回。如果返回0说明成功,失败返回-1并置位errno。
- 如果想强制(排队中)等待的异步操作不等待,而直接写入持久化的存储中,可以建立一个
-
aio_error函数- 获知一个异步读、写或者同步操作的完成状态,可以通过
aio_error函数int aio_error(const struct aiocb *aiocbp);- 返回值:
0:异步操作成功完成,需要调用aio_return函数获取操作返回值-1:失败,并置位errnoEINPROGRESS:异步读、写或同步操作仍在等待- 其他情况:相关异步操作失败返回的错误码。如
ECANCELED代表该异步I/O被取消了
- 返回值:
- 获知一个异步读、写或者同步操作的完成状态,可以通过
-
aio_return函数- 如果异步操作成功,可以调用
aio_return函数来获取异步操作的返回值ssize_t aio_return(struct aiocb *aiocbp);- 异步操作完成之前,都不要调用该函数
- 异步操作完成之后,对每个异步操作只能调用一次该函数。因为一旦调用了该函数,操作系统就释放掉了包含I/O操作返回值的记录。
- 返回值
-1:调用失败,置位errno- 其他情况:返回异步操作结果,即会返回
read、write或者fsync在被成功调用时可能返回的结果
- 如果异步操作成功,可以调用
-
aio_suspend函数- 可以通过
aio_suspend函数阻塞进程,直到异步I/O操作结束int aio_suspend(const struct aiocb * const aiocb_list[],int nitems, const struct timespec *timeout);- 参数
aiocb_list:阻塞的异步I/O操作数组,数组元素必须指向已用于初始化异步I/O操作的aiocb控制块。 nitems参数:阻塞的异步I/O操作数组元素个数timeout参数:等待的时间,NULL代表永远等待- 返回值
- 被信号中断返回
-1,errno置位EINTR - 超过
timeout时间限制,返回-1,errno置位EAGAIN - 如果有任何异步
I/O操作完成,该函数返回0。 - 如果调用该函数时所有异步
I/O操作已经完成,则不阻塞直接返回
- 被信号中断返回
- 参数
- 可以通过
-
aio_cancel函数- 当我们不想再完成等待中的异步
I/O操作时,可以尝试用aio_cancel函数取消它们。注意,系统无法保证能够取消该异步I/O操作,所以是尝试。int aio_cancel(int fd, struct aiocb *aiocbp);- 参数
fd:未完成的异步I/O操作的文件描述符 aiocbp参数:如果为NULL,系统会尝试取消该文件的所有未完成异步I/O操作;否则,系统会尝试取消由aiocbp控制块描述的单个异步I/O操作。- 返回值:
AIO_ALLDONE:所有操作在尝试取消它们之前已经完成AIO_CANCELED:所有要求的操作已被取消AIO_NOTCANCELED:至少一个要求的操作没有被取消-1:调用失败,置位errno
- 参数
- 如果异步
I/O成功被取消,对相应的AIO控制块调用aio_error会返回错误ECANCELED。
- 当我们不想再完成等待中的异步
-
lio_listio函数- 一次提交一系列由一个
aiocb控制块列表描述的I/O请求。注意该函数可以指定是异步还是同步。int lio_listio(int mode, struct aiocb *const aiocb_list[], int nitems, struct sigevent *sevp);- 参数
mode:决定I/O是否真的是异步的LIO_WAIT:同步I/O,即该函数在所有由列表指定的I/O操作完成后返回。此时sevp参数被忽略LIO_NOWAIT:异步I/O。该函数在I/O请求入队后立即返回。进程将在所有I/O操作完成后,按照sevp参数指定的被异步的通知。
sevp参数- 所有异步
I/O完成后,按照该参数进行通知。需要与aiocb_list数组中每个aiocb的aio_sigevent字段区分开来,每个元素的aio_sigevent字段是在该异步I/O完成后进行通知的,而sevp参数针对的是所有异步I/O完成之后。
- 所有异步
aiocb_list参数和nitems参数- 指定要运行的
I/O操作。(aiocb_list是aiocb数组,nitems是数组元素个数) - 每个
aiocb中的aio_lio_opcode只在该函数中使用,aio_lio_opcode字段值:LIO_READ:读操作,按照对应的aiocb控制块传给aio_read处理LIO_WRITE:写操作,按照对应的aiocb控制块传给aio_write处理LIO_NOP:将被忽略的空操作
- 指定要运行的
- 参数
- 一次提交一系列由一个
-
实例:展示两个程序,分别是不采用和采用异步I/O的两种写法。程序中包含是
ROT-13算法,该算法将文本中的英文字符a~z和A~Z分别循环向右偏移13个字母位移。#include "apue.h" #include <ctype.h> #include <fcntl.h> #define BSZ 4096 unsigned char buf[BSZ]; unsigned char translate(unsigned char c) { if (isalpha(c)) { if (c >= 'n') c -= 13; else if (c >= 'a') c += 13; else if (c >= 'N') c -= 13; else c += 13; } return(c); } int main(int argc, char* argv[]) { int ifd, ofd, i, n, nw; if (argc != 3) err_quit("usage: rot13 infile outfile"); if ((ifd = open(argv[1], O_RDONLY)) < 0) err_sys("can't open %s", argv[1]); if ((ofd = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE)) < 0) err_sys("can't create %s", argv[2]); while ((n = read(ifd, buf, BSZ)) > 0) { for (i = 0; i < n; i++) buf[i] = translate(buf[i]); if ((nw = write(ofd, buf, n)) != n) { if (nw < 0) err_sys("write failed"); else err_quit("short write (%d/%d)", nw, n); } } fsync(ofd); exit(0); }程序中的I/O部分非常直接:从输入文件中读取一个块,翻译之,然后再把这个块写到输出文件中。重复该步骤直到遇到文件尾端,
read返回0。下面展示如果使用等价的异步I/O做同样的任务。#include "apue.h" #include <ctype.h> #include <fcntl.h> #include <aio.h> #include <errno.h> #define BSZ 4096 /*使用了8个缓冲区,可以有最多8个异步I/O请求处于等待状态,这实际上可能会降低性能。 因为如果读操作是以无序的方式提交给文件系统的,操作系统会在提前读的算法便会失效*/ #define NBUF 8 enum rwop { UNUSED = 0, READ_PENDING = 1, WRITE_PENDING = 2 }; struct buf { enum rwop op; int last; struct aiocb aiocb; unsigned char data[BSZ]; }; struct buf bufs[NBUF]; unsigned char translate(unsigned char c) { /* same as before */ if (isalpha(c)) { if (c >= 'n') c -= 13; else if (c >= 'a') c += 13; else if (c >= 'N') c -= 13; else c += 13; } return(c); } int main(int argc, char* argv[]) { int ifd, ofd, i, j, n, err, numop; struct stat sbuf; const struct aiocb *aiolist[NBUF]; off_t off = 0; if (argc != 3) err_quit("usage: rot13 infile outfile"); if ((ifd = open(argv[1], O_RDONLY)) < 0) err_sys("can't open %s", argv[1]); if ((ofd = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE)) < 0) err_sys("can't create %s", argv[2]); if (fstat(ifd, &sbuf) < 0) err_sys("fstat failed"); /* initialize the buffers */ for (i = 0; i < NBUF; i++) { bufs[i].op = UNUSED; bufs[i].aiocb.aio_buf = bufs[i].data; bufs[i].aiocb.aio_sigevent.sigev_notify = SIGEV_NONE; aiolist[i] = NULL; } numop = 0; for (;;) { for (i = 0; i < NBUF; i++) { /*这一部分与老朋友状态机有异曲同工之妙,注意UNUSED、READ_PENDING和WRITE_PENDING是枚举变量*/ switch (bufs[i].op) { case UNUSED: /* * Read from the input file if more data * remains unread. */ if (off < sbuf.st_size) { bufs[i].op = READ_PENDING; bufs[i].aiocb.aio_fildes = ifd; bufs[i].aiocb.aio_offset = off; off += BSZ; if (off >= sbuf.st_size) bufs[i].last = 1; bufs[i].aiocb.aio_nbytes = BSZ; if (aio_read(&bufs[i].aiocb) < 0) err_sys("aio_read failed"); aiolist[i] = &bufs[i].aiocb; numop++; } break; case READ_PENDING: /*异步读、写或同步操作仍在等待*/ if ((err = aio_error(&bufs[i].aiocb)) == EINPROGRESS) continue; if (err != 0) { if (err == -1) err_sys("aio_error failed"); else err_exit(err, "read failed"); } /* * A read is complete; translate the buffer * and write it. */ if ((n = aio_return(&bufs[i].aiocb)) < 0) err_sys("aio_return failed"); if (n != BSZ && !bufs[i].last) err_quit("short read (%d/%d)", n, BSZ); for (j = 0; j < n; j++) bufs[i].data[j] = translate(bufs[i].data[j]); bufs[i].op = WRITE_PENDING; bufs[i].aiocb.aio_fildes = ofd; bufs[i].aiocb.aio_nbytes = n; if (aio_write(&bufs[i].aiocb) < 0) err_sys("aio_write failed"); /* retain our spot in aiolist */ break; case WRITE_PENDING: if ((err = aio_error(&bufs[i].aiocb)) == EINPROGRESS) continue; if (err != 0) { if (err == -1) err_sys("aio_error failed"); else err_exit(err, "write failed"); } /* * A write is complete; mark the buffer as unused. */ if ((n = aio_return(&bufs[i].aiocb)) < 0) err_sys("aio_return failed"); if (n != bufs[i].aiocb.aio_nbytes) err_quit("short write (%d/%d)", n, BSZ); aiolist[i] = NULL; bufs[i].op = UNUSED; numop--; break; } } if (numop == 0) { if (off >= sbuf.st_size) break; } else { if (aio_suspend(aiolist, NBUF, NULL) < 0) err_sys("aio_suspend failed"); } } bufs[0].aiocb.aio_fildes = ofd; if (aio_fsync(O_SYNC, &bufs[0].aiocb) < 0) err_sys("aio_fsync failed"); exit(0); }- 在检查操作的返回值之前,必须确认操作已经完成。
- 当
aio_error返回的值既非EINPROGRESS也非-1时,表明操作完成。 - 当
aio_error返回的值是0以外的任何值,表明操作失败。
在经过上述检查过程后,就可以安全地调用aio_return来获取I/O操作的返回值了。
- 当
- 只要还有事情要做,就可以提交异步I/O操作。
- 当存在未使用的AIO控制块时,可以提交一个异步读操作。
- 读操作完成后,翻译缓冲区中的内容并将它提交给一个异步写请求。
- 当所有的AIO控制块都在使用中时,通过调用
aio_suspend等待。
- 在把一个块写入输出文件时,我们保留了在从输入文件读取数据时的偏移量,因而写的顺序并不重要。这种策略的前提是文件中的字符数量没有改变。
- 注意这个实例中没有使用异步通知,具体使用场景以后再说。
- 在检查操作的返回值之前,必须确认操作已经完成。
6、函数readv和writev
- 如果要从文件中读一片连续的数据至进程的不同区域,有两种方案:①使用
read()一次将它们读至一个较大的缓冲区中,然后将它们分成若干部分复制到不同的区域; ②调用read()若干次分批将它们读至不同区域。同样,如果想将程序中不同区域的数据块连续地写至文件,也必须进行类似的处理。 UNIX提供了另外两个函数——readv()和writev(),它们只需一次系统调用就可以实现在文件和进程的多个缓冲区之间传送数据,免除了多次系统调用或复制数据的开销。
6.1、readv分散读
- 可以将文件描述符的数据读入多个缓冲区中。readv总是先填满一个缓冲区,然后再填写下一个。
ssize_t readv(int fd, const struct iovec *iov, int iovcnt); struct iovec { void *iov_base; /* 缓冲区地址 */ size_t iov_len; /* 缓冲区大小 */ };fd:要读的文件描述符iov:iovec结构体数组,每个结构体代表一个缓冲区
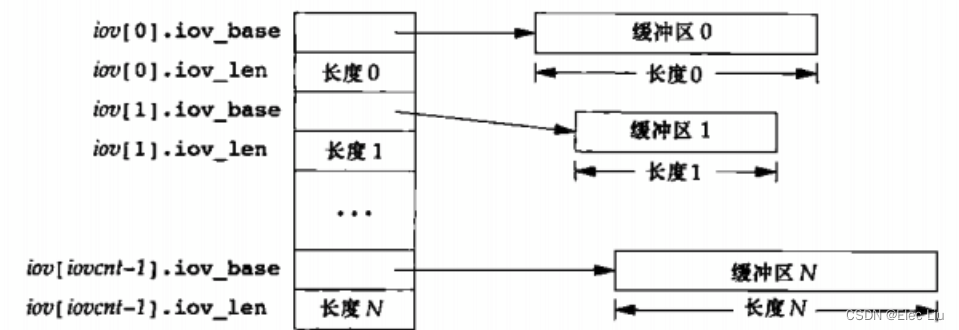
iovcnt:第二个参数数组元素个数- 返回值:
readv返回读到的总字节数。如果遇到文件结尾,已无数据可读,则返回0。出错时返回-1并设置相应的errno。
- 使用示例:
int main() { char buf1[8] = { 0 }; char buf2[8] = { 0 }; struct iovec iov[2]; ssize_t nread; iov[0].iov_base = buf1; iov[0].iov_len = sizeof(buf1); iov[1].iov_base = buf2; iov[1].iov_len = sizeof(buf2); nread = readv(STDIN_FILENO, iov, 2); printf("%ld bytes read.\n", nread); printf("buf1: %s\n", buf1); printf("buf2: %s\n", buf2); exit(EXIT_SUCCESS); }
6.2、writev分散写
- 可以将数据从多个缓冲区写入文件描述符。
writev将多个数据存储在一起,将驻留在两个或更多的不连接的缓冲区中的数据一次写出去。writev以顺序iov[0]、iov[1]至iov[iovcnt-1]从各缓冲区中聚集输出数据到fd。ssize_t writev(int fd, const struct iovec *iov, int iovcnt); struct iovec { void *iov_base; /* 缓冲区地址 */ size_t iov_len; /* 缓冲区大小 */ };fd:要写入的文件描述符iov:iovec结构体数组,每个结构体代表一个缓冲区iovcnt:第二个参数数组元素个数- 返回值:返回写入的总字节数,出错时返回
-1并设置相应的errno。
- 示例:
int main() { char *str0 = "hello "; char *str1 = "world\n"; struct iovec iov[2]; ssize_t nwritten; iov[0].iov_base = str0; iov[0].iov_len = strlen(str0) + 1; iov[1].iov_base = str1; iov[1].iov_len = strlen(str1) + 1; nwritten = writev(STDOUT_FILENO, iov, 2); printf("%ld bytes written.\n", nwritten); exit(EXIT_SUCCESS); }
7、函数readn和writen
-
管道、FIFO以及某些设备(特别是终端和网络)有下列两种性质。
- 一次
read操作所返回的数据可能小于所要求的数据,即使还没达到文件尾端也可能是这样。这不是一个错误,应当继续读该设备。 - 一次
write操作的返回值也可能少于指定输出的字节数,可能的原因例如:内核输出缓冲区变满。这也不是错误,应当继续写余下的数据。(通常,只有非阻塞描述符,或捕捉到一个信号时,才会出现write的中途返回)。
- 一次
-
为了考虑上述特性,需要引入函数
readn和writen。这两个函数的功能分别是读、写指定的N字节数据,并处理返回值可能小于要求值的情况。这两个函数只是按需多次调用read和write直至读、写了N字节数据。#include "apue.h" ssize_t readn(int fd,void* buf,size nbytes); ssize_t writen(int fd,void* buf,size_t nbytes); -
实例:
readn和writen函数的实现。ssize_t /* Read "n" bytes from a descriptor */ readn(int fd, void *ptr, size_t n) { size_t nleft; ssize_t nread; nleft = n; while (nleft > 0) { if ((nread = read(fd, ptr, nleft)) < 0) { if (nleft == n) return(-1); /* error, return -1 */ else break; /* error, return amount read so far */ } else if (nread == 0) { break; /* EOF */ } nleft -= nread; ptr += nread; } return(n - nleft); /* return >= 0 */ } ssize_t /* Write "n" bytes to a descriptor */ writen(int fd, const void *ptr, size_t n) { size_t nleft; ssize_t nwritten; nleft = n; while (nleft > 0) { if ((nwritten = write(fd, ptr, nleft)) < 0) { if (nleft == n) return(-1); /* error, return -1 */ else break; /* error, return amount written so far */ } else if (nwritten == 0) { break; } nleft -= nwritten; ptr += nwritten; } return(n - nleft); /* return >= 0 */ }
8、存储映射I/O
- 存储映射
I/O能将一个磁盘文件映射到存储空间中的一个缓冲区上。于是当从缓冲区中取数据时,就相当于读文件中的相应字节;将数据存入缓冲区时,相应字节就自动写入文件。就可以在不使用read和write的情况下执行I/O。
8.1、mmap函数
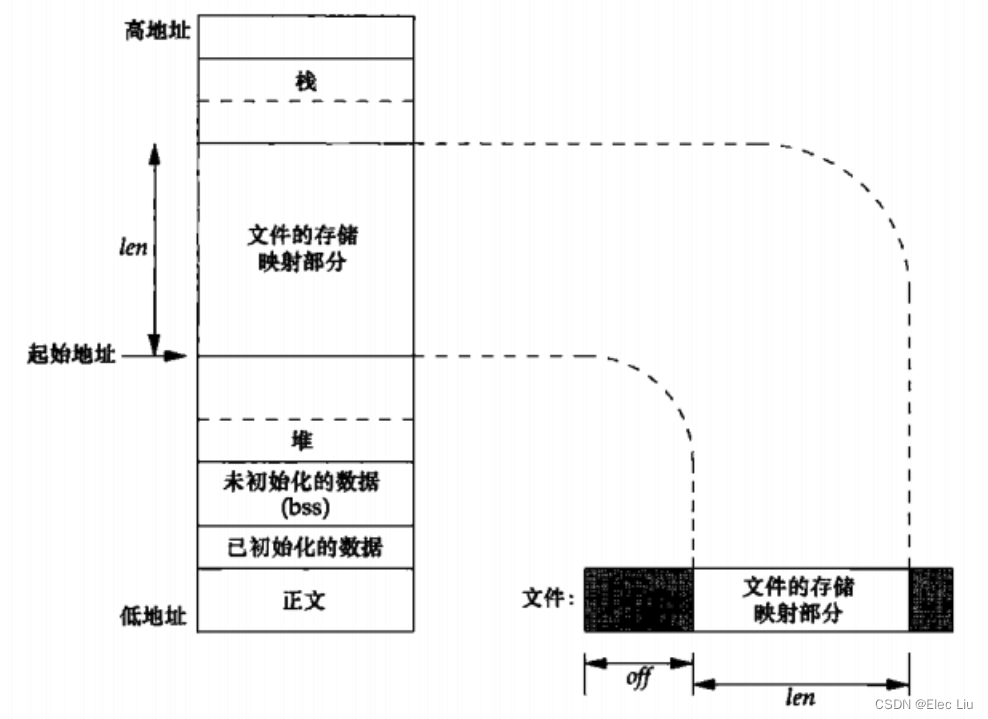
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。mmap()系统调用使得进程之间通过映射同一个普通文件实现共享内存。- 存储映射文件示意图:可见映射存储区位于堆和栈之间(各种实现可能不同)
mmap函数告诉内核将一个给定的文件映射到一个存储区域中void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset); //成功返回映射区起始地址;失败返回MAP_FAILED- 参数
addr:- 指定映射存储区起始地址(即进程中的一块内存区域)。如果为
NULL,则由系统选择该映射区起始地址,且函数返回值是该地址。
- 指定映射存储区起始地址(即进程中的一块内存区域)。如果为
- 参数
length:- 映射区的长度(字节)。可以通过
stat系统调用获得打开文件的大小信息,然后设置为这个参数
- 映射区的长度(字节)。可以通过
- 参数
prot:- 期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以是
PROT_NONE,也可以是其他三个值的按位或。PROT_EXEC映射区可以被执行PROT_READ映射区可以被读取PROT_WRITE映射区可以被写入PROT_NONE映射区不可访问
- 期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以是
- 参数
flag:- 指定映射对象的类型,映射选项和映射页是否可以共享。
MAP_FIXED:返回值必须等于addr参数。该标志不建议使用。因为如果addr非0,则内核只把该参数当做一种建议,但是不保证会使用所要求的地址。因此建议将addr设置为NULLMAP_PRIVATE:多进程间数据共享,修改不反应到磁盘实际文件,是一个copy-on-write(写时复制)的映射方式。即内存区域的写入不会影响到原文件MAP_SHARED:多进程间数据共享,修改反应到磁盘实际文件中,相当于输出到文件- 等等
- 指定映射对象的类型,映射选项和映射页是否可以共享。
- 参数
fd:- 要被映射的文件描述符。必须先打开该文件。
- 参数
offset:- 被映射内容的起点(即
fd文件内容偏移量)
- 被映射内容的起点(即
- 参数
- 使用
mmap函数需要注意以下几点:- 注意,
addr和offset的值通常被要求是系统虚拟存储页长度的倍数(可以通过sysconf(_SC_PAGESIZE)得到)。但是addr和offset常被设置为0,因此该要求不重要。 - 注意,映射区长度通常是页长的整数倍。假定文件长为12字节,系统页长为512字节,则系统通常提供512字节的映射区,只不过后500字节都被置0。可以修改后面的这500字节,但是任何变动不会在文件中反映出来。因此不能用mmap将数据添加到文件从而改变文件长度,而是必须先加长该文件再修改文件内容。
- 与映射区相关信号有
SIGSEGV和SIGBUS。 fork后子进程继承存储映射区exec之后的新程序不继承存储映射区
- 注意,
8.2、mprotect函数
- 修改一个现有映射的权限
int mprotect(void *addr, size_t len, int prot);prot参数值与mmap的prot参数一样。PROT_EXEC映射区可以被执行PROT_READ映射区可以被读取PROT_WRITE映射区可以被写入PROT_NONE映射区不可访问
- 地址参数
addr必须是系统页长整数倍
- 如果要修改的页是通过
MAP_SHARED标志映射到地址空间的,那么修改并不会立即写回到文件中。何时写回脏页面由内核的守护进程决定。 - 如果只修改了一页中的一个字节,当修改被写回到文件中时,整个页都被写回。
8.3、msync函数
- 进程在映射空间的对共享内容的改变并不直接写回到磁盘文件中,如果共享映射中的页已修改(
MAP_SHARED),那么可以调用msync将该页冲洗到被映射的文件中。msync类似于fsync,但作用于存储映射区。如果映射是私有的(MAP_PRIVATE),那么不修改被映射的文件。int msync(void *addr, size_t length, int flags);flags参数:MS_ASYNC:异步。调用会立即返回,不等到更新的完成;MS_SYNC:同步。在该函数返回之前等待写操作完成。如果要确保数据安全的写到了文件中,则需要在进程终止前以MS_SYNC标志调用msync函数
8.4、munmap函数函数
- 进程终止时,会自动解除存储映射区的映射,或者直接调用
munmap函数解除映射区。注意,close映射存储区时使用的文件描述符并不解除映射区。int munmap(void *addr, size_t length);munmap函数并不会使映射区的内容写到磁盘文件上。- 对于
MAP_SHARED映射的磁盘文件的更新,会在我们将数据写到存储映射区后的某个时刻,按照内存虚拟存储算法自动进行。 - 在存储区解除映射后,对
MAP_PRIVATE存储区的修改会被丢弃。
- 实例:用存储映射I/O复制文件(类似于
cp(1)命令)。#include "apue.h" #include <fcntl.h> #include <sys/mman.h> #define COPYINCR (1024*1024*1024) /* 1 GB */ int main(int argc, char *argv[]) { int fdin, fdout; void *src, *dst; size_t copysz; struct stat sbuf; off_t fsz = 0; if (argc != 3) err_quit("usage: %s <fromfile> <tofile>", argv[0]); if ((fdin = open(argv[1], O_RDONLY)) < 0) err_sys("can't open %s for reading", argv[1]); if ((fdout = open(argv[2], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) < 0) err_sys("can't creat %s for writing", argv[2]); if (fstat(fdin, &sbuf) < 0) /* need size of input file */ err_sys("fstat error"); if (ftruncate(fdout, sbuf.st_size) < 0) /* set output file size */ err_sys("ftruncate error"); while (fsz < sbuf.st_size) { if ((sbuf.st_size - fsz) > COPYINCR) copysz = COPYINCR; else copysz = sbuf.st_size - fsz; if ((src = mmap(0, copysz, PROT_READ, MAP_SHARED, fdin, fsz)) == MAP_FAILED) err_sys("mmap error for input"); if ((dst = mmap(0, copysz, PROT_READ | PROT_WRITE, MAP_SHARED, fdout, fsz)) == MAP_FAILED) err_sys("mmap error for output"); memcpy(dst, src, copysz); /* does the file copy */ munmap(src, copysz); munmap(dst, copysz); fsz += copysz; } exit(0); }- 该程序首先打开两个文件,然后调用
fstat得到输入文件的长度。在为输入文件调用mmap和设置输出文件长度时都需使用输入文件长度。可以调用ftruncate设置输出文件的长度。如果不设置输出文件的长度,则对输出文件调用mmap也可以,但是对相关存储区的第一次引用会产生SIGBUS信号。 - 然后对每个文件调用
mmap,将文件映射到内存,最后调用memcpy将输入缓冲区的内容复制到输出缓冲区。为了限制使用内存的量,我们每次最多复制1GB的数据(如果系统没有足够的内存,可能无法把一个很大的文件中的所有内容都映射到内存中)。在映射文件中的后一部分数据之前,我们需要解除前一部分数据的映射。 - 在从输入缓冲区(
src)读数据字节时,内核自动读入文件;在将数据存入输出缓冲区时(dst),内核自动将数据写到输出文件中。 - 数据被写到文件的确切时间依赖于系统的页管理算法。某些系统设置了守护进程,在系统运行期间,它慢条斯理地将改写过的页写到磁盘上。如果想要确保数据安全地写到文件中,则需在进程终止前以
MS_SYNC标志调用msync。
- 该程序首先打开两个文件,然后调用
补充:read与write 和 mmap和memcpy 的对比
- 在Linux中,用户时间的结果很相似,但是
read与write消耗的系统时间要比使用mmap和memcpy略好一些。
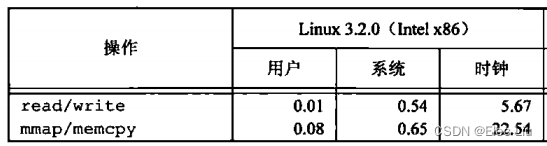
- 两者的主要区别在于,与
mmap和memcpy相比,read与write执行了耕更多的系统调用,并做了更多的复制。read与write将数据从内核缓冲区中复制到应用缓冲区(read),然后再把数据从应用缓冲区复制到内核缓冲区(write)。mmap和memcpy直接把数据从映射到地址空间的一个内核缓冲区复制到另一个内核缓冲区。当引用不存在的内存页时,这样的复制过程就会作为处理页错误的结果而出现(每次错页读和错页写均会发生错误)。
















 8013
8013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











