









HUAWEI – C++二面面经
公众号:阿Q技术站
文章目录
- HUAWEI -- C++二面面经
- 1、C和C++的区别,C++的特性,怎么实现多态?
- 2、介绍下虚函数,追问在继承中子类虚函数表怎么生成?
- 3、构造和构析函数能不能写为虚函数,为什么?
- 4、stl中set和map使用的是什么数据结构存储,追问红黑树结构是什么?
- 5、简单说一下工厂模式?
- 6、C++11了解多少,追问智能指针有几种?为什么要使用智能指针?
- 7、内存泄露是什么意思?怎么避免内存泄露?
- 8、指针传递和引用传递的区别?
- 9、代码编译运行的过程?
- 10、include<>和“”的区别?
- 11、对Linux系统了解多少,说几个你知道的Linux命令?
- 12、进程和线程的区别?
- 13、为什么会出现死锁问题?
- 14、栈和队的区别有哪些,实际开发的过程中有哪里会用到栈和队?
- 15、图的深度优先遍历算法?
- 16、介绍一下分治算法?
- 17、介绍一下tcp的三次握手和四次挥手?
- 18、tcp如何保证可靠性,什么情况下会重发?
- 19、手撕代码:本地IDE做,dfs的问题,应该是力扣中等难度
来源:https://www.nowcoder.com/feed/main/detail/b8113ff340d7444985b32a73c207c826
1、C和C++的区别,C++的特性,怎么实现多态?
C和C++的区别
1. 编程范式:
- C语言是一种过程式编程语言,主要强调函数调用和顺序执行。
- **C++**是一种多范式编程语言,支持过程式编程、面向对象编程和泛型编程。
2. 面向对象编程:
- C语言不支持面向对象编程,没有类和对象的概念。
- **C++**引入了类、对象、继承、封装和多态等面向对象编程特性。
3. 标准库:
- C语言的标准库比较简单,主要提供一些基本的输入输出、字符串操作、内存管理等功能。
- **C++**的标准库更为丰富,包含STL(标准模板库),提供了大量的容器类(如
vector、list、map等)和算法(如sort、find等)。
4. 函数重载和运算符重载:
- C语言不支持函数重载和运算符重载。
- **C++**支持函数重载和运算符重载,可以对同名函数进行不同参数的重载,也可以定义自定义的运算符。
5. 内存管理:
- C语言主要通过
malloc和free进行动态内存分配和释放。 - **C++**引入了
new和delete操作符来进行动态内存管理,此外,C++还支持RAII(资源获取即初始化)惯用法,通过构造函数和析构函数自动管理资源。
6. 引用和指针:
- C语言只有指针,没有引用。
- **C++**除了指针之外,还引入了引用,可以简化参数传递和返回值。
7. 命名空间:
- C语言没有命名空间的概念,容易产生全局命名冲突。
- **C++**引入了命名空间,可以有效地避免命名冲突。
C++的特性
- 类和对象: C++引入了类和对象,使得面向对象编程成为可能。
- 继承: 通过继承可以实现代码的复用和扩展。
- 多态: 通过虚函数机制实现多态,可以在运行时决定调用哪个函数。
- 封装: 通过访问控制(public, protected, private)实现数据的封装。
- 运算符重载: 可以对内置运算符进行重载,使得自定义类型的操作更加直观。
- 模板: 提供了泛型编程的能力,可以编写类型无关的代码。
- 异常处理: 通过
try,catch,throw语句实现异常处理。 - STL(标准模板库): 提供了丰富的容器、算法和迭代器,极大地提高了编程效率。
实现多态
在C++中,多态是通过虚函数(virtual function)机制实现的。多态允许我们在运行时决定调用哪个函数。下面是一个实现多态的示例:
#include <iostream>
using namespace std;
// 基类
class Shape {
public:
// 纯虚函数,使得Shape成为抽象类
virtual void draw() = 0;
};
// 派生类 - 圆形
class Circle : public Shape {
public:
void draw() override {
cout << "Drawing Circle" << endl;
}
};
// 派生类 - 矩形
class Rectangle : public Shape {
public:
void draw() override {
cout << "Drawing Rectangle" << endl;
}
};
int main() {
// 创建对象的指针数组
Shape* shapes[2];
shapes[0] = new Circle();
shapes[1] = new Rectangle();
// 多态调用
for (int i = 0; i < 2; ++i) {
shapes[i]->draw();
}
// 释放内存
for (int i = 0; i < 2; ++i) {
delete shapes[i];
}
return 0;
}
2、介绍下虚函数,追问在继承中子类虚函数表怎么生成?
虚函数是C++中实现多态的一种机制。虚函数允许在继承关系中通过基类指针或引用来调用派生类的函数。虚函数的声明使用关键字virtual。如果一个类中有虚函数,那么这个类会包含一个虚函数表(Virtual Table,简称vtable)。
虚函数的特点:
- 动态绑定: 在运行时根据对象的实际类型决定调用哪个函数,而不是在编译时。
- 多态性: 通过基类指针或引用可以调用派生类的重写函数。
虚函数示例:
#include <iostream>
using namespace std;
class Base {
public:
virtual void show() {
cout << "Base class show function called" << endl;
}
};
class Derived : public Base {
public:
void show() override { // override关键字可选,但推荐使用以增强可读性
cout << "Derived class show function called" << endl;
}
};
int main() {
Base* basePtr;
Derived derivedObj;
basePtr = &derivedObj;
// 基类指针调用虚函数,实际调用的是派生类的函数
basePtr->show();
return 0;
}
在这个例子中,基类Base定义了一个虚函数show,派生类Derived重写了这个虚函数。在main函数中,通过基类指针basePtr指向派生类对象derivedObj,调用show函数时,会实际调用Derived类的show函数。
虚函数表(vtable)
当一个类中定义了虚函数,编译器会为这个类生成一个虚函数表(vtable)。虚函数表是一个指针数组,存储了虚函数的地址。在对象创建时,每个对象包含一个指向虚函数表的指针,称为虚指针(vptr)。
虚函数表的生成过程:
- 基类: 如果基类包含虚函数,编译器会为基类生成一个虚函数表,表中存储基类虚函数的地址。
- 派生类: 当派生类重写了基类的虚函数,编译器会为派生类生成一个新的虚函数表。这个表包含派生类重写的虚函数的地址,如果派生类没有重写某个虚函数,则该表项指向基类的对应虚函数。
虚函数表的结构:
-
基类虚函数表:
Base_vtable: &Base::show -
派生类虚函数表:
Derived_vtable: &Derived::show
在运行时,当通过基类指针调用虚函数时,程序会先通过对象的虚指针(vptr)找到虚函数表(vtable),然后根据函数的位置从表中找到实际调用的函数地址。
虚函数表的例子:
#include <iostream>
using namespace std;
class Base {
public:
virtual void show() {
cout << "Base class show function called" << endl;
}
virtual void display() {
cout << "Base class display function called" << endl;
}
};
class Derived : public Base {
public:
void show() override {
cout << "Derived class show function called" << endl;
}
};
int main() {
Base baseObj;
Derived derivedObj;
baseObj.show(); // 调用Base::show
baseObj.display(); // 调用Base::display
derivedObj.show(); // 调用Derived::show
derivedObj.display(); // 调用Base::display
return 0;
}
在这个例子中,Base类有两个虚函数show和display,而Derived类只重写了show函数。虚函数表会如下生成:
-
Base类的vtable:
Base_vtable: &Base::show &Base::display -
Derived类的vtable:
Derived_vtable: &Derived::show &Base::display
当调用baseObj.show()时,会调用Base::show。当调用derivedObj.show()时,会调用Derived::show。当调用derivedObj.display()时,因为Derived类没有重写display函数,所以会调用Base::display。
3、构造和构析函数能不能写为虚函数,为什么?
构造函数不能是虚函数
原因:
- 对象创建过程: 在创建对象时,需要先调用构造函数来初始化对象的成员。如果构造函数是虚函数,在调用构造函数之前,虚函数表(vtable)还没有被初始化,无法正确地进行虚函数调用。
- 虚函数表初始化: 虚函数表的指针(vptr)是在对象的构造过程中初始化的。如果构造函数本身是虚函数,在构造函数调用时,虚函数表还未建立,导致无法确定应该调用哪个构造函数。
- 设计逻辑: 构造函数的目的是初始化对象的状态,而虚函数的目的是支持多态行为。在对象未完全构造之前,多态行为是不可用的。因此,从设计角度来看,构造函数不适合作为虚函数。
析构函数可以是虚函数
原因:
- 多态删除: 如果一个基类指针指向派生类对象,通过基类指针删除对象时,为了确保调用派生类的析构函数,需要将基类的析构函数声明为虚函数。这可以保证对象被正确地销毁,释放所有资源。
- 资源释放: 虚析构函数确保了在删除对象时,先调用派生类的析构函数,再调用基类的析构函数,从而正确地释放资源,避免内存泄漏。
虚析构函数的示例:
#include <iostream>
using namespace std;
class Base {
public:
Base() {
cout << "Base constructor called" << endl;
}
virtual ~Base() { // 虚析构函数
cout << "Base destructor called" << endl;
}
};
class Derived : public Base {
public:
Derived() {
cout << "Derived constructor called" << endl;
}
~Derived() {
cout << "Derived destructor called" << endl;
}
};
int main() {
Base* basePtr = new Derived();
delete basePtr; // 调用派生类的析构函数,然后调用基类的析构函数
return 0;
}
输出:
Base constructor called
Derived constructor called
Derived destructor called
Base destructor called
4、stl中set和map使用的是什么数据结构存储,追问红黑树结构是什么?
在C++标准模板库(STL)中,set和map都是使用红黑树(Red-Black Tree)来实现的。红黑树是一种自平衡的二叉搜索树,能够在最坏情况下提供高效的插入、删除和查找操作,时间复杂度均为 (O(log n))。
红黑树结构
红黑树是一种自平衡的二叉搜索树。
性质:
- 每个节点是红色或黑色的。
- 根节点是黑色的。
- 每个叶节点(NIL节点,通常是空节点)是黑色的。
- 如果一个节点是红色的,则它的两个子节点都是黑色的(即不允许两个连续的红色节点)。
- 从任一节点到其每个叶节点的所有路径都包含相同数目的黑色节点(黑色高度相同)。
红黑树的基本操作
插入操作:
插入新节点时:
- 新节点首先插入为红色。
- 可能会违反红黑树的性质,因此需要进行调整。通过旋转和重新着色来恢复红黑树的性质。
删除操作:
删除节点时:
- 被删除的节点可能是红色或黑色,可能会破坏红黑树的平衡。
- 需要通过旋转和重新着色来恢复红黑树的性质。
旋转操作:
旋转分为左旋和右旋两种,用于调整红黑树的结构:
左旋:
x y
/ \ / \
a y ==> x c
/ \ / \
b c a b
在左旋操作中,节点x下沉,节点y上升,子树b成为x的右子树。
右旋:
y x
/ \ / \
x c ==> a y
/ \ / \
a b b c
在右旋操作中,节点y下沉,节点x上升,子树b成为y的左子树。
红黑树的优点
平衡性:红黑树通过旋转和重新着色保持自平衡,确保所有基本操作的时间复杂度为 (O(log n))。
高效性:在最坏情况下,红黑树的高度最多是普通二叉搜索树高度的两倍,依然保证了高效的查找、插入和删除操作。
5、简单说一下工厂模式?
工厂模式(Factory Pattern)是一种创建型设计模式,用于创建对象的实例,允许类的实例化推迟到子类中进行。它提供了一种将对象的创建过程与其使用过程分离的方式,增强了系统的灵活性和可扩展性。
工厂模式有几种变体,包括简单工厂模式(Simple Factory)、工厂方法模式(Factory Method)和抽象工厂模式(Abstract Factory)。
简单工厂模式
简单工厂模式不是GoF的23种设计模式之一,但它是工厂模式的基础。它通过一个工厂类负责创建对象的实例,根据传入的参数决定创建哪一个具体类的实例。
示例代码:
#include <iostream>
#include <string>
// 产品抽象类
class Product {
public:
virtual void show() = 0; // 纯虚函数
};
// 具体产品A
class ProductA : public Product {
public:
void show() override {
std::cout << "ProductA" << std::endl;
}
};
// 具体产品B
class ProductB : public Product {
public:
void show() override {
std::cout << "ProductB" << std::endl;
}
};
// 工厂类
class SimpleFactory {
public:
static Product* createProduct(const std::string& type) {
if (type == "A") {
return new ProductA();
} else if (type == "B") {
return new ProductB();
} else {
return nullptr;
}
}
};
int main() {
Product* product1 = SimpleFactory::createProduct("A");
if (product1) {
product1->show();
delete product1;
}
Product* product2 = SimpleFactory::createProduct("B");
if (product2) {
product2->show();
delete product2;
}
return 0;
}
在这个示例中,SimpleFactory类根据传入的类型参数创建并返回具体的产品对象(ProductA或ProductB)。客户端通过调用SimpleFactory::createProduct方法来获取具体产品的实例,而不需要直接实例化具体产品类。
工厂方法模式
工厂方法模式定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个。工厂方法将对象的创建延迟到子类中。
示例代码:
#include <iostream>
#include <string>
// 产品抽象类
class Product {
public:
virtual void show() = 0; // 纯虚函数
};
// 具体产品A
class ProductA : public Product {
public:
void show() override {
std::cout << "ProductA" << std::endl;
}
};
// 具体产品B
class ProductB : public Product {
public:
void show() override {
std::cout << "ProductB" << std::endl;
}
};
// 工厂抽象类
class Factory {
public:
virtual Product* createProduct() = 0; // 纯虚函数
};
// 具体工厂A
class FactoryA : public Factory {
public:
Product* createProduct() override {
return new ProductA();
}
};
// 具体工厂B
class FactoryB : public Factory {
public:
Product* createProduct() override {
return new ProductB();
}
};
int main() {
Factory* factoryA = new FactoryA();
Product* productA = factoryA->createProduct();
productA->show();
delete productA;
delete factoryA;
Factory* factoryB = new FactoryB();
Product* productB = factoryB->createProduct();
productB->show();
delete productB;
delete factoryB;
return 0;
}
在这个示例中,每个具体工厂类(FactoryA和FactoryB)负责创建一个具体产品实例(ProductA和ProductB)。客户端通过具体工厂来创建产品对象,避免了直接依赖具体产品类。
6、C++11了解多少,追问智能指针有几种?为什么要使用智能指针?
1. 自动类型推导 (auto)
auto 关键字允许编译器根据初始化表达式推导变量的类型,从而简化代码书写,特别是在需要声明复杂类型时。
auto x = 42; // int
auto y = 3.14; // double
auto z = "Hello"; // const char*
2. 统一初始化
C++11 引入了一种新的初始化语法,可以统一地对数组、结构体、类等进行初始化。
int arr[] = {1, 2, 3, 4};
std::vector<int> vec = {1, 2, 3, 4};
struct Point { int x, y; };
Point p = {1, 2};
3. Lambda 表达式
Lambda 表达式提供了一种简洁的方式来定义匿名函数,可以在需要函数对象的地方直接使用。
auto add = [](int a, int b) { return a + b; };
int result = add(2, 3); // result = 5
4. 右值引用和移动语义
右值引用 (&&) 和移动语义允许更高效地管理资源,减少不必要的拷贝操作。
class MyClass {
public:
MyClass(const MyClass& other); // 拷贝构造函数
MyClass(MyClass&& other); // 移动构造函数
};
std::vector<int> v1 = {1, 2, 3, 4};
std::vector<int> v2 = std::move(v1); // v1 的资源被移动到 v2
5. 智能指针
C++11 引入了智能指针 (std::unique_ptr 和 std::shared_ptr),用于自动管理动态内存,避免内存泄漏。
std::unique_ptr<int> p1(new int(10));
std::shared_ptr<int> p2 = std::make_shared<int>(20);
6. nullptr 关键字
nullptr 引入了一个明确表示空指针的值,代替传统的 NULL。
int* p = nullptr;
7. 常量表达式 (constexpr)
constexpr 关键字用于声明在编译时求值的常量表达式,可以提高程序的运行效率。
constexpr int square(int x) {
return x * x;
}
constexpr int result = square(5); // result 在编译时计算
8. 范围循环
范围循环提供了一种遍历容器元素的简洁语法。
std::vector<int> vec = {1, 2, 3, 4};
for (int x : vec) {
std::cout << x << " ";
}
9. 类成员初始化
可以直接在类定义中对成员变量进行初始化。
class MyClass {
int x = 10;
int y = 20;
};
10. 标准库增强
C++11 对标准库进行了大量增强,包括新容器(如 std::array)、多线程支持(<thread>、<mutex>)、正则表达式(<regex>)、随机数库(<random>)等。
std::array<int, 4> arr = {1, 2, 3, 4};
std::thread t([]{ std::cout << "Hello from thread!"; });
t.join();
11. 新的函数声明
包括 noexcept 指定函数不会抛出异常,以及 override 和 final 用于更好地控制虚函数的行为。
void func() noexcept {
// 不会抛出异常的函数
}
class Base {
virtual void foo() const;
};
class Derived : public Base {
void foo() const override; // 确保是重写基类的虚函数
};
12. 模板增强
包括变长模板参数(Variadic Templates)和别名模板(Alias Templates)。
template<typename... Args>
void print(Args... args) {
(std::cout << ... << args) << std::endl; // C++17 折叠表达式
}
template<typename T>
using Vec = std::vector<T>;
13. 强类型枚举
enum class 提供了强类型的枚举,避免与其他枚举类型或整数类型混淆。
enum class Color { Red, Green, Blue };
Color c = Color::Red;
14. decltype 关键字
decltype 关键字用于查询表达式的类型,可以用于声明与表达式类型一致的变量。
int x = 10;
decltype(x) y = 20; // y 的类型是 int
15. 静态断言
static_assert 在编译时进行条件检查,提供更好的调试和错误提示。
static_assert(sizeof(int) == 4, "Unexpected int size");
这些特性使 C++11 成为一个更加现代化、高效和易用的编程语言,同时保持了 C++ 的强大和灵活性。
智能指针
智能指针通过自动管理动态内存的生命周期,帮助防止内存泄漏和悬挂指针的问题。
1. std::unique_ptr
- 特点: 独占所有权,不能共享。一个对象只能有一个
std::unique_ptr拥有者。 - 用法: 用于需要独占控制权的资源管理。
- 示例:
#include <iostream>
#include <memory>
int main() {
std::unique_ptr<int> p1(new int(10)); // 或 std::make_unique<int>(10) 在C++14及之后
std::cout << *p1 << std::endl;
std::unique_ptr<int> p2 = std::move(p1); // 转移所有权
if (!p1) {
std::cout << "p1 is now null" << std::endl;
}
return 0;
}
2. std::shared_ptr
- 特点: 共享所有权,可以有多个
std::shared_ptr指向同一个对象。通过引用计数来管理对象的生命周期。 - 用法: 用于需要共享资源的场景。
- 示例:
#include <iostream>
#include <memory>
int main() {
std::shared_ptr<int> p1 = std::make_shared<int>(20);
std::shared_ptr<int> p2 = p1; // 共享所有权
std::cout << "p1: " << *p1 << ", p2: " << *p2 << std::endl;
std::cout << "p1 use count: " << p1.use_count() << std::endl; // 输出引用计数
return 0;
}
3. std::weak_ptr
- 特点: 弱引用,不增加引用计数。用于解决
std::shared_ptr的循环引用问题。 - 用法: 用于观察
std::shared_ptr而不干扰其生命周期。 - 示例:
#include <iostream>
#include <memory>
int main() {
std::shared_ptr<int> p1 = std::make_shared<int>(30);
std::weak_ptr<int> wp = p1; // 弱引用,不增加引用计数
if (auto sp = wp.lock()) { // 检查 `std::shared_ptr` 是否仍然存在
std::cout << *sp << std::endl;
} else {
std::cout << "p1 has been deleted" << std::endl;
}
return 0;
}
为什么要使用智能指针
- 防止内存泄漏: 智能指针自动管理对象的生命周期,确保动态分配的内存在不再需要时被释放,防止内存泄漏。
- 防止悬挂指针: 当对象被销毁时,智能指针将其置为
nullptr,防止悬挂指针的出现。 - 简化代码: 使用智能指针可以减少显式的内存管理代码,使代码更加简洁和可读。
- 异常安全性: 智能指针在异常发生时仍然能正确释放资源,提供了异常安全性。
7、内存泄露是什么意思?怎么避免内存泄露?
内存泄漏是指程序在动态分配内存之后未能正确释放已分配的内存,导致这些内存无法被再次使用或回收。当内存泄漏发生时,程序会逐渐耗尽可用内存资源,最终可能导致程序崩溃或系统性能下降。
内存泄漏的典型特征包括:
- 程序的内存使用持续增长
- 程序在长时间运行后变得缓慢
- 最终系统内存不足导致程序崩溃
避免内存泄漏的方法
-
使用智能指针
使用C++11引入的智能指针(如
std::unique_ptr、std::shared_ptr)自动管理内存的生命周期,确保内存能够在不再需要时被释放。示例:
#include <iostream> #include <memory> void foo() { std::unique_ptr<int> ptr = std::make_unique<int>(10); // ptr 指向的内存在函数结束时自动释放 } -
成对使用
new和delete每次使用
new分配内存时,确保有相应的delete释放内存。使用delete释放对象时要特别小心,防止重复释放或未释放内存。示例:
void foo() { int* ptr = new int(10); // 记得在不再需要时释放内存 delete ptr; } -
避免使用原始指针进行动态内存管理
尽量避免直接使用原始指针进行动态内存管理,使用容器(如
std::vector、std::string等)和智能指针来管理动态内存。示例:
void foo() { std::vector<int> vec = {1, 2, 3, 4, 5}; // vec 的内存在函数结束时自动释放 } -
定期检查和测试
使用工具(如 Valgrind、AddressSanitizer)检测内存泄漏。定期运行这些工具可以帮助识别和修复内存泄漏问题。
Valgrind 使用示例:
valgrind --leak-check=full ./your_program -
RAII(资源获取即初始化)
使用RAII原则管理资源。通过构造函数获取资源,通过析构函数释放资源,确保资源在对象的生命周期内正确管理。
示例:
class Resource { public: Resource() { // 获取资源 } ~Resource() { // 释放资源 } }; void foo() { Resource res; // res 在函数结束时自动释放资源 } -
遵循智能指针的使用规则
- 使用
std::unique_ptr管理独占所有权的资源 - 使用
std::shared_ptr管理共享所有权的资源 - 使用
std::weak_ptr防止std::shared_ptr的循环引用问题
- 使用
8、指针传递和引用传递的区别?
指针传递
指针传递是通过传递指向数据的指针来实现的。
特点:
- 传递的是指针(地址),可以通过指针修改原始数据。
- 需要显式地解引用指针来访问或修改数据。
- 可以传递
nullptr来表示空指针。 - 传递指针本身有可能导致悬挂指针或野指针问题,需要小心管理指针的生命周期。
示例:
#include <iostream>
void modifyValue(int* ptr) {
if (ptr != nullptr) {
*ptr = 20;
}
}
int main() {
int value = 10;
modifyValue(&value);
std::cout << "Modified value: " << value << std::endl; // 输出 20
return 0;
}
引用传递
引用传递是通过传递变量的引用来实现的。
特点:
- 传递的是引用,引用是被引用对象的别名。
- 不需要显式地解引用,可以直接使用引用来访问或修改数据。
- 引用必须初始化,不能传递空引用。
- 引用更安全,因为引用始终引用合法的对象,不会有悬挂引用的问题。
示例:
#include <iostream>
void modifyValue(int& ref) {
ref = 20;
}
int main() {
int value = 10;
modifyValue(value);
std::cout << "Modified value: " << value << std::endl; // 输出 20
return 0;
}
9、代码编译运行的过程?
1. 预处理
预处理器负责处理以 # 开头的指令,如宏定义、文件包含等。预处理的结果是一个纯文本文件,其中包含了所有的头文件和替换了所有的宏。
- 宏替换:所有的宏定义(用
#define定义的)会被替换成对应的值。 - 文件包含:所有的
#include语句会被替换成包含文件的内容。 - 条件编译:处理所有的条件编译指令(如
#ifdef、#ifndef、#if、#else和#endif)。 - 注释移除:移除所有的注释。
预处理器生成的文件通常以 .i 为扩展名。
2. 编译
编译器将预处理后的源代码转换为汇编代码。这个阶段,编译器会进行语法和语义检查,并将高层次的 C++ 代码转换为对应的低层次汇编代码。
- 语法检查:检查代码的语法是否正确。
- 语义分析:检查代码的逻辑是否正确,例如类型检查、变量定义和作用域检查等。
- 优化:编译器可能会对代码进行优化,以提高生成代码的性能。
- 生成汇编代码:将 C++ 代码转换为汇编代码。
编译器生成的汇编文件通常以 .s 为扩展名。
3. 汇编
汇编器将汇编代码转换为机器代码(目标代码)。目标代码是特定于目标处理器的二进制代码,但还不是可执行文件。
- 生成机器代码:将汇编指令转换为机器指令。
- 生成目标文件:目标文件包含了机器代码和一些元数据(如符号表和重定位信息)。
汇编器生成的目标文件通常以 .o(Unix 系统)或 .obj(Windows 系统)为扩展名。
4. 链接
链接器负责将一个或多个目标文件和库文件链接在一起,生成最终的可执行文件。
- 符号解析:解析所有的符号,确保所有的函数和变量都能找到定义。
- 地址分配:为所有的符号分配内存地址。
- 库链接:将所需的库文件(静态库或动态库)链接到目标文件中。
- 生成可执行文件:将所有的目标代码合并,生成最终的可执行文件。
链接器生成的可执行文件通常在 Unix 系统中没有扩展名,在 Windows 系统中以 .exe 为扩展名。
10、include<>和“”的区别?
#include <>
- 用法:
#include <header>,其中header是标准库头文件或编译器预定义的头文件。 - 搜索路径:编译器将在标准系统目录中搜索头文件。
#include ""
- 用法:
#include "header",其中header是用户自定义的头文件或外部库的头文件。 - 搜索路径:编译器首先在当前源文件的目录中搜索头文件,如果未找到,则在其他标准系统目录中搜索。
11、对Linux系统了解多少,说几个你知道的Linux命令?
之前总结过比较详细的Linux命令:
12、进程和线程的区别?
- 定义:
- 进程(Process): 进程是计算机中的一个独立的执行环境,它包含了一个程序的代码、数据、资源、以及一个执行线程。每个进程都有独立的内存空间,相互之间不会直接共享数据,需要通过进程间通信(Inter-Process Communication,IPC)来进行数据交换。
- 线程(Thread): 线程是进程内的执行单元,一个进程可以包含多个线程。线程共享进程的内存空间和资源,它们可以直接访问相同的数据,因此线程之间的通信相对容易。
- 资源占用:
- 进程: 每个进程都有独立的内存空间和系统资源(如文件描述符、网络连接等),因此进程的资源占用相对较高。
- 线程: 线程共享进程的内存空间和资源,因此线程的资源占用相对较低。
- 创建和销毁:
- 进程: 创建和销毁进程相对较重,需要分配和释放独立的资源,通常比线程开销大。
- 线程: 创建和销毁线程相对较轻量,因为它们共享进程的资源,通常比进程开销小。
- 切换代价:
- 进程: 进程切换的代价相对较高,因为需要保存和恢复进程的完整上下文信息,包括内存空间、寄存器状态等。
- 线程: 线程切换的代价相对较低,因为线程共享同一进程的地址空间和资源,切换时只需切换线程的上下文。
- 并发性:
- 进程: 进程是独立的执行单元,不同进程之间的并发性相对较低,它们通常需要通过进程间通信来协调和共享数据。
- 线程: 线程是进程内的执行单元,不同线程之间的并发性相对较高,它们可以直接共享数据,但需要注意线程同步问题,以避免竞争条件和死锁。
- 安全性:
- 进程: 进程之间的数据隔离较好,一个进程崩溃通常不会影响其他进程。
- 线程: 线程之间共享相同的内存空间,因此一个线程的错误可能会影响整个进程的稳定性。
- 平台支持:
- 进程: 进程是操作系统级别的概念,可以跨平台使用。
- 线程: 线程通常依赖于特定的线程库和操作系统支持,跨平台性可能有限。
13、为什么会出现死锁问题?
死锁是指两个或多个进程或线程在争夺系统资源时互相等待,导致它们都无法继续执行的情况。死锁的发生需要满足以下四个条件,称为“必要条件”:
-
互斥条件(Mutual Exclusion):
资源不能被共享,每次只能一个进程使用。
-
占有并等待条件(Hold and Wait):
进程已经获得了一些资源,但在等待其他资源的同时,不释放已获得的资源。
-
不可剥夺条件(No Preemption):
已获得的资源不能被强制剥夺,只能由持有该资源的进程自愿释放。
-
循环等待条件(Circular Wait):
存在一个进程集合 {P1, P2, …, Pn},其中 P1 等待 P2 占有的资源,P2 等待 P3 占有的资源,直到 Pn 等待 P1 占有的资源,形成一个环形等待链。
防止死锁的方法
防止死锁的方法主要有四种:
-
破坏互斥条件:
使资源可以共享。例如,将一些资源变为可重入的资源。
-
破坏占有并等待条件:
进程请求资源时不占有其他资源,可以采用以下方法:
- 进程在开始执行时一次性申请所有需要的资源。
- 进程在申请资源时,如果无法获得所有资源,则释放已占有的资源,稍后重新尝试。
-
破坏不可剥夺条件:
允许资源被强制剥夺。例如:
- 进程可以主动释放资源,稍后重新申请。
- 如果某进程占有的资源被其他进程请求,可以强制该进程释放资源。
-
破坏循环等待条件:
破坏循环等待条件可以通过以下方法:
- 资源有序分配法:为系统中的每类资源分配一个全局唯一的编号。进程必须按编号顺序申请资源,且只能按升序申请资源。
- 一次性申请法:进程在开始执行时一次性申请所有资源。
- 银行家算法:这是最著名的避免死锁的算法之一。它根据资源的当前可用量和进程的最大需求量,动态地分配资源,以避免死锁。
14、栈和队的区别有哪些,实际开发的过程中有哪里会用到栈和队?
栈和队列的区别
- 数据结构:
- 栈是一种后进先出(Last In, First Out,LIFO)的数据结构,类似于一摞叠放的盘子,只能在顶部插入和删除元素。
- 队列是一种先进先出(First In, First Out,FIFO)的数据结构,类似于排队,只能在队尾插入元素,在队首删除元素。
- 操作:
- 栈的基本操作包括入栈(push)和出栈(pop),入栈将元素压入栈顶,出栈将栈顶元素弹出。
- 队列的基本操作包括入队(enqueue)和出队(dequeue),入队将元素插入队尾,出队将队首元素删除并返回。
- 应用场景:
- 栈常用于实现函数调用栈、表达式求值、括号匹配等场景,以及需要后进先出特性的问题。
- 队列常用于任务调度、缓冲区管理、广度优先搜索等场景,以及需要先进先出特性的问题。
实际开发中的应用
- 栈的应用:
- 函数调用栈:保存函数调用过程中的局部变量、参数和返回地址。
- 表达式求值:通过后缀表达式(逆波兰表达式)计算表达式的值。
- 括号匹配:检查表达式中的括号是否匹配。
- 浏览器的前进后退功能:使用两个栈分别存储前进和后退的页面。
- 队列的应用:
- 任务调度:多个任务按照先后顺序依次执行。
- 缓冲区管理:生产者消费者模型中的任务队列。
- 广度优先搜索(BFS):按层级遍历图或树。
15、图的深度优先遍历算法?
图的深度优先遍历(Depth First Search,DFS)是一种用于遍历或搜索图的算法,其基本思想是尽可能深地搜索图的分支。
具体步骤:
- 访问起始顶点: 从图中选择一个顶点作为起始顶点,并将其标记为已访问。
- 递归访问相邻顶点: 对于起始顶点的每个未访问过的相邻顶点,递归地应用深度优先遍历算法。
- 标记顶点: 在访问相邻顶点之前,标记当前顶点为已访问。
- 回溯: 当无法继续深入时(即当前顶点没有未访问的相邻顶点),回溯到上一个顶点,继续尝试访问其他未访问的相邻顶点。
递归实现深度优先遍历
以下是一个使用递归实现深度优先遍历的示例代码(假设图的表示采用邻接表):
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
// 图的邻接表表示
vector<vector<int>> graph = {
{1, 2}, // 0 的相邻顶点为 1 和 2
{0, 3, 4}, // 1 的相邻顶点为 0、3 和 4
{0, 5}, // 2 的相邻顶点为 0 和 5
{1}, // 3 的相邻顶点为 1
{1}, // 4 的相邻顶点为 1
{2} // 5 的相邻顶点为 2
};
// 记录顶点是否已经访问过的数组
vector<bool> visited(graph.size(), false);
// 深度优先遍历函数
void dfs(int v) {
visited[v] = true; // 标记当前顶点为已访问
cout << v << " "; // 输出当前顶点
// 递归访问当前顶点的所有相邻顶点
for (int u : graph[v]) {
if (!visited[u]) {
dfs(u);
}
}
}
int main() {
cout << "深度优先遍历结果:" << endl;
dfs(0); // 从顶点 0 开始深度优先遍历
cout << endl;
return 0;
}
16、介绍一下分治算法?
基本思想是将一个复杂的问题分解成多个相同或相似的子问题,然后递归地解决这些子问题,最后合并子问题的解得到原问题的解。
分治算法的三个步骤:
- 分解: 将原问题分解成若干个规模较小、相互独立且与原问题形式相同的子问题。
- 解决: 递归地求解各个子问题。若子问题规模较小且容易解决,则直接求解;否则,继续分解子问题,递归地解决。
- 合并: 将各个子问题的解合并为原问题的解。
17、介绍一下tcp的三次握手和四次挥手?
三次握手
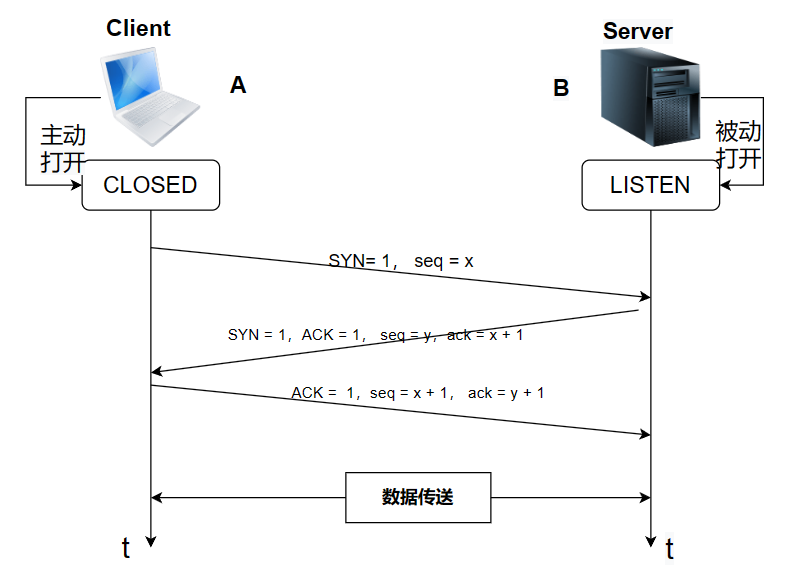
在建立连接之前,Client处于CLOSED状态,而Server处于LISTEN的状态。
- 第一次握手(SYN-1):
- 客户端发送一个带有 SYN 标志的 TCP 报文段给服务器,表示客户端请求建立连接。
- 客户端选择一个初始序列号(ISN)并将其放入报文段中,进入 SYN_SENT 状态。
- 第二次握手(SYN + ACK):
- 服务器收到客户端发送的 SYN 报文段后,如果同意建立连接,会发送一个带有 SYN 和 ACK 标志的报文段给客户端,表示服务器接受了客户端的请求,并带上自己的 ISN。
- 服务器进入 SYN_RCVD 状态。
- 第三次握手(ACK):
- 客户端收到服务器发送的 SYN+ACK 报文段后,会发送一个带有 ACK 标志的报文段给服务器,表示客户端确认了服务器的响应。
- 客户端和服务器都进入 ESTABLISHED 状态,连接建立成功,可以开始进行数据传输。
四次挥手
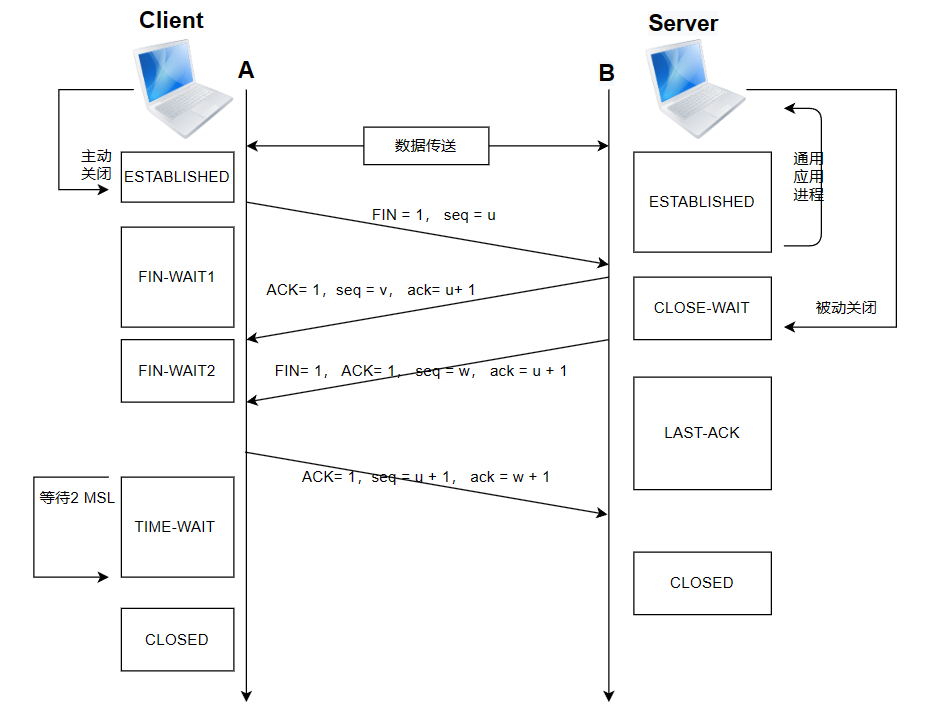
- 第一次挥手(FIN-1):
- 客户端发送一个 FIN 报文段给服务器,表示客户端已经没有数据要发送了,请求关闭连接。
- 客户端进入 FIN_WAIT_1 状态,等待服务器的确认。
- 第二次挥手(ACK):
- 服务器收到客户端的 FIN 报文段后,发送一个 ACK 报文段作为应答,表示已经接收到了客户端的关闭请求。
- 服务器进入 CLOSE_WAIT 状态,等待自己的数据发送完毕。
- 第三次挥手(FIN-2):
- 服务器发送一个 FIN 报文段给客户端,表示服务器也没有数据要发送了,请求关闭连接。
- 服务器进入 LAST_ACK 状态,等待客户端的确认。
- 第四次挥手(ACK):
- 客户端收到服务器的 FIN 报文段后,发送一个 ACK 报文段作为应答,表示已经接收到了服务器的关闭请求。
- 客户端进入 TIME_WAIT 状态,等待可能出现的延迟数据。
- 服务器收到客户端的 ACK 报文段后,完成关闭,进入 CLOSED 状态。
- 客户端在 TIME_WAIT 状态结束后,关闭连接,进入 CLOSED 状态。
18、tcp如何保证可靠性,什么情况下会重发?
- 序号和确认应答: TCP 使用序号和确认应答机制来保证数据的可靠传输。发送方将每个发送的数据包都标记上一个序号,接收方收到数据后会发送一个确认应答,确认收到的数据的序号。如果发送方在一定时间内没有收到确认应答,则会重发数据包。
- 超时重传: 当发送方发送数据后,在规定的时间内没有收到确认应答,则会认为数据丢失,触发超时重传机制,重新发送数据包。
- 流量控制: TCP 使用滑动窗口(Sliding Window)机制进行流量控制。接收方会告诉发送方自己的接收窗口大小,发送方根据接收窗口大小来控制发送的数据量,避免发送过多数据导致接收方无法处理。
- 拥塞控制: TCP 使用拥塞控制算法来避免网络拥塞。当网络拥塞时,会发生丢包现象,TCP 会根据丢包情况调整发送速率,避免拥塞加剧。
- 重传机制: TCP 使用重传机制来保证数据的可靠传输。如果发送的数据包丢失或损坏,接收方会丢弃该数据包,并在下次发送的确认应答中通知发送方需要重传的数据包。
















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









