







1. Motivation
针对机器学习中的出现的数据隐私泄露的风险,提出了线性回归、逻辑回归以及简单神经网络的隐私保护模型。
2. Contributions
2.1 为线性回归、逻辑回归以及神经网络设计安全计算协议
2.1.1.1 线性回归
线性回归损失函数为:
,
采用SGD算法处理损失函数,权重w的更新公式为:
式子只有加法、乘法运算,秘密分享的形式为:
写成向量的形式为:
根据Beaver's triple 计算矩阵乘法:
这里需要注意的是文章中说明的是两个服务器
,都以获得数据的一个份额,并不是各方持有一份完整的数据。
可得:
,之后的乘法运算都依据这个式子。
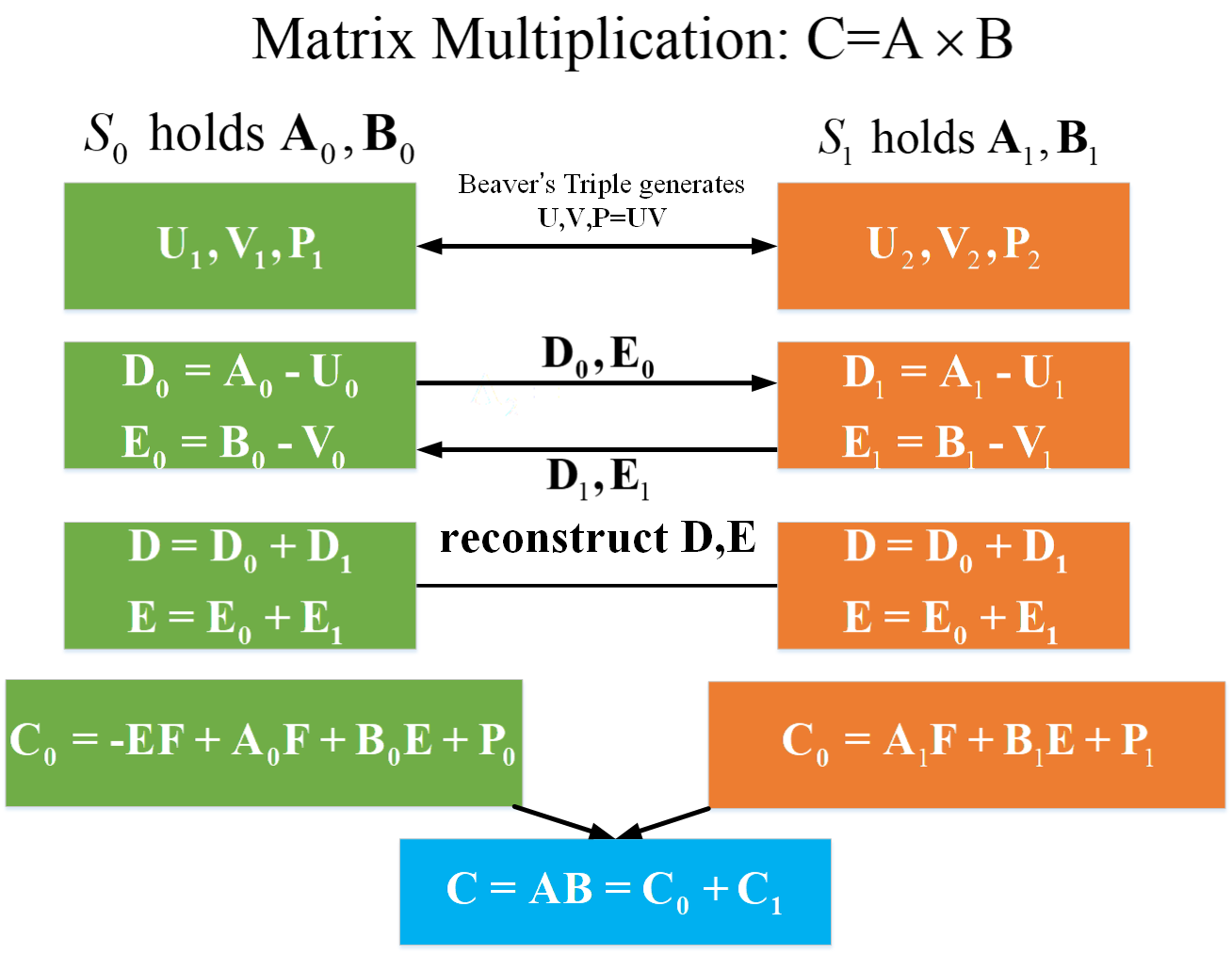
完整过程如下:

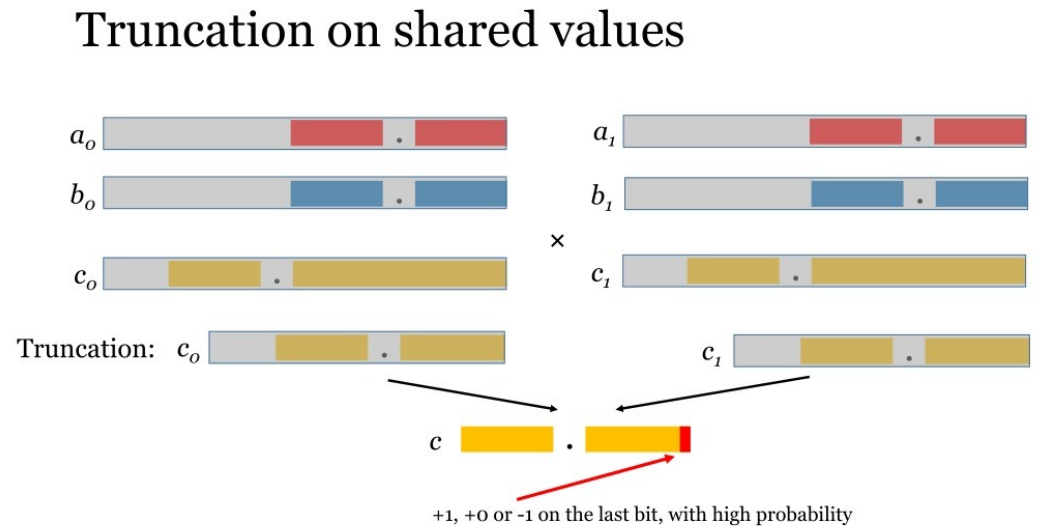
2.2 运算中小数的处理
计算小数乘法,x*y,假设x和y都最多有D为小数。
(1)将x和y进行扩大
,
(2)截断小数
扩大后结果为,小数位数最多D为,所以将最后D位截取,截断后的结果可写为
,用
表示截断操作则最的相乘结果为
。
2.3 优化激活函数
在逻辑回归算法中,有函数,其中在实数域中,该函数包含的除法和求幂运算很难支持2PC和布尔运算,比之前工作用多项式去逼近函数不同的是,作者提出一个Friendly activation function,函数为f(u),f(u)图像如下图所示。

构造的灵感来源于:
(1)函数值应该收敛在0和1之间;(2)RELU函数
2.4 引入了面向秘密共享的向量化计算
线性回归下模型权重更新公式为,仅涉及加法和乘法。秘密分享形式下的加法在本地即可计算,而乘法需要借助Beavers Triple。但是元素级别的运算效率太低,这里优化为矩阵乘法
,由2.1节可知C的Share为:
,这样可以大大加快计算效率。
3. Q&R
3.1 为什么加法秘密共享是环上,shamir是在域上?
答:加法秘密分享只需要加减法就可以定义分享和恢复算法;shamir的恢复算法需要计算离散空间的除法,环中因为有些元素没有逆元,所以没法保证恢复算法能成功。域中元素都有逆元,可以计算除法。
3.2 隐私计算往往要求在有限域上运算,实际问题怎么去应用?
答:需要转化为将实际的运算转化到有限域的代数系统中。
4. Summary
优化一个问题,可以从各个方面入手,有的对结果有直接影响,有的是间接影响;有的直接影响大,有的直接影响小。
Reference
1.论文阅读笔记:SecureML: A System for Scalable Privacy-Preserving Machine Learning - 知乎















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









