






一、MPI概述及程序编译运行
MPI(Message Passing Interface),消息传递接口。主要用于进程间的消息传递(或者数据传递),主要发起者为2022年图灵奖获得者——Jack j. dongarra。
MPI编译命令
Intel MPI
Fortran: mpiifort
C: mpiicc
C++: mpiicpc
Mpich/OpenMPI
Fortran: mpif90
f77: mpif77
C: mpicc
C++: mpicxx
MPI程序运行命令:
mpirun -n cup个数
MPI的四个基本接口
MPI_Init(&argc, &argv):初始化MPI环境,MPI系统将通过argc,argv得到命令行参数
MPI_Comm_rank(MPI_COMM_WORLD, &myrank):缺省的通信域为MPI_COMM_WORLD获得进程在缺省通信域的编号,赋值给myrank
MPI_Comm_size(MPI_COMM_WORLD, &size):获得缺省通信域内所有进程数目,赋值给size
MPI_Finalize():一般放在程序最后一行。如果没有此行,MPI程序将不会终止。
MPI程序并行模式
相并行
主从并行
分治并行
流水线并行
工作池并行
一、MPI点对点通信
阻塞型
MPI_Send(buffer, count, datatype, destination, tag, communicator)
• 第一个参数指明消息缓存的起始地址,即存放要发送的数据信息。
• 第二个参数指明消息中给定的数据类型有多少项,数据类型由第三个参数给定。
• 数据类型要么是基本数据类型,要么是导出数据类型,后者由用户生成指定一个可能是由混合数据类型组成的非连续数据项。
• 第四个参数是目的进程的标识符(进程编号)。
• 第五个是消息标签。
• 第六个参数标识进程组和通信上下文,即通信域。通常,消息只在同组的进程间传送。但是MPI允许通过intercommunicators在组间通信。
MPI_Recv(address, count, datatype,source, tag, communicator, status)
• 第一个参数指明接收消息缓冲的起始地址,即存放接收消息的内存地址。
• 第二个参数指明给定数据类型可以被接收的最大项数。
• 第三个参数指明接收的数据类型。
• 第四个参数是源进程标识符 (编号)。
• 第五个是消息标签。
• 第六个参数标识一个通信域。
• 第七个参数是一个指针, 指向一个结构:MPI_Status Status,存放有关接收消息的各种信息。(Status.MPI_SOURCE, Status.MPI_TAG)
• MPI_Get_count(&Status, MPI_INT, &C)读出实际接收到的数据项数。
非阻塞型
int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest, int tag,MPI_Comm comm, MPI_Request *request)
IN buf 发送缓冲区的起始地址(可选数据类型)
IN count 发送数据的个数(整型)
IN datatype 发送数据的数据类型(句柄)
IN dest 目的进程号(整型)
IN tag 消息标志(整型)
IN comm 通信域(句柄)
OUT request 返回的非阻塞通信对象(句柄)
int MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source, int tag,MPI_Comm comm, MPI_Request *request)
OUT buf 接收缓冲区的起始地址(可选数据类型)
IN count 接收数据的最大个数(整型)
IN datatype 每个数据的数据类型(句柄)
IN source 源进程标识(整型)
IN tag 消息标志(整型)
IN comm 通信域(句柄)
OUT request 非阻塞通信对象(句柄)
int MPI_Wait(MPI_Request *request, MPI_Status *status)阻塞直到非阻塞通信完成
INOUT request 非阻塞通信对象 (句柄)
OUT status 返回的状态 (状态类型)
int MPI_Test(MPI_Request*request, int *flag, MPI_Status *status)检测非阻塞通信是否完成,不必等待
INOUT request 非阻塞通信对象(句柄)
OUT flag 操作是否完成标志(逻辑型)
OUT status 返回的状态 (状态类型)
*Tag和source的特殊情况
MPI_ANT_TAG:如果给tag一个任意值MPI_ANY_TAG 则任何tag都是可接收的
MPI_ANY_SOURCE:标识任何进程发送的消息都可以接收,即本接收操作可以匹配任何进程发送的消息,但其它的要求还必须满足,比如tag的匹配。
捆绑发送接收
int MPI_Sendrecv(void *sendbuf,
int sendcount,
MPI_Datatype sendtype,
int dest,
int sendtag,
void *recvbuf,
int recvcount,
MPI_Datatype recvtype,
int source,
int recvtag,
MPI_Comm comm,
MPI_Status *status)
MPI提供了MPI_Sendrecv(捆绑发送和接收)操作,可以在一条MPI语句中同时实现向其它进程的数据发送和从其它进程接收数据操作。
• 把发送一个消息到一个目的地和从另一个进程接收一个消息合并到一个调用中,源和目的可以相同
• 在语义上等同于一个发送操作和一个接收操作的结合
• 可以有效地避免由于单独书写发送或接收操作时,由于次序的错误而造成的死锁
• 因为该操作由通信系统来实现,系统会优化通信次序从而有效地避免不合理的通信次序,最大限度避免死锁的产生
• 捆绑发送接收操作是不对称的,即一个由捆绑发送接收调用发出的消息可以被一个普通接收操作接收,一个捆绑发送接收调用可以接收一个普通发送操作发送的消息。
• 该操作执行一个阻塞的发送和接收,接收和发送使用同一个通信域。
• 发送缓冲区和接收缓冲区必须分开,可以是不同的数据长度和不同的数据类型。
*虚拟进程
虚拟进程(MPI_PROC_NULL) 是不存在的假想进程,在MPI中的主要作用是充当真实进程通信的目或源。
• 引入虚拟进程的目的是为了在某些情况下编写通信语句的方便。
• 当一个真实进程向一个虚拟进程发送数据或从一个虚拟进程接收
数据时,该真实进程会立即正确返回,如同执行了一个空操作。
• 一个真实进程向虚拟进程MPI_PROC_NULL发送消息时,会立即成功返回。
• 一个真实进程从虚拟进程MPI_PROC_NULL的接收消息时,也会立即成功返回,并且对接收缓冲区没有任何改变。
重复非阻塞通信
int MPI_Send_init(void* buf, int count, MPI_Data type,int dest, int tag,MPI_Comm comm, MPI_Request *request);
IN buf 发送缓冲区起始地址(可选数据类型)
IN count 发送数据个数(整型)
IN datatype 发送数据的数据类型(句柄)
IN dest 目标进程标识(整型)
IN tag 消息标识(整型)
IN comm 通信域(句柄)
OUT request 非阻塞通信对象(句柄)
int MPI_Recv_init(void* buf,int count,MPI_Datatype datatype,int source, int tag,MPI_Comm comm,MPI_Request *request)
OUT buf 接收缓冲区初始地址(可选数据类型)
IN count 接收数据的最大个数(整型)
IN datatype 接收数据的数据类型(句柄)
IN source 发送进程的标识或任意进程MPI_ANY_SOURCE(整型)
IN tag 消息标识或任意标识MPI_ANY_TAG(整型)
IN comm 通信域(句柄)
OUT request 非阻塞通信对象(句柄)
如果一个通信会被重复执行,比如循环结构内的通信调用,MPI提供了特殊的实现方式,这样的通信进行优化,以降低不必要的通信开销,它将通信参数和MPI的内部对象建立固定的联系,然后通过该对象完成重复通信的任务,这样的通信方式在MPI中都是非阻塞通信。
重复非阻塞通信步骤
A.通信初始化,比如MPI_Send_init
B.启动通信,MPI_Startall
C.等待通信完成,MPI_Waitall
D.释放查询对象,MPI_Request_free
B和C在循环体中重复调用
MPI组通信
Broadcast
MPI_Bcast(Address, Count, Datatype, Root, Comm)
• 标号为Root的进程发送相同的消息给标记为Comm的通信子中的所
有进程。
• 消息的内容如同点对点通信一样由三元组(Address, Count, Datatype)
标识。对Root进程来说,这个三元组既定义了发送缓冲也定义了接
收缓冲。对其它进程来说,这个三元组只定义了接收缓冲。
Scatter
MPI_Scatter (SendAddress,SendCount,SendDatatype,
RecvAddress,RecvCount,RecvDatatype,Root,Comm)
• Root进程发送给所有n个进程各发送一个不同的消息,包括自已。
• 这n个消息在Root进程的发送缓冲区中按标号的顺序有序地存放。每个接收缓冲由三元组(RecvAddress, RecvCount, RecvDatatype)标识。非Root进程忽略发送缓冲。
• 对Root进程,发送缓冲由三元组(SendAddress, SendCount, SendDatatype)标识。
Gather
MPI_Gather (SendAddress,SendCount,SendDatatype,
RecvAddress,RecvCount,RecvDatatype,Root,Comm)
• Root进程接收各个进程(包括它自已)的消息。这n个消息的连接按序号rank进行,存放在Root进程的接收缓冲中。
• 每个发送缓冲由三元组(SendAddress, SendCount, SendDatatype) 标识。
• 非Root进程忽略接收缓冲。对Root进程,发送缓冲由三元组(RecvAddress, RecvCount, RecvDatatype)标识。RecvCount是自每个进程接收数据个数。
Allgather
MPI_Allgather ( SendAddress, SendCount, SendDatatype,
RecvAddress, RecvCount, RecvDatatype, Comm )
• 每个进程都从其他进程收集数据,存入自己的缓冲区内,没有root进程。
Reduce
MPI_Reduce(sendbuf,recvbuf,recvcount,datatype,op,root,comm)
• 所有进程向同一进程发送消息,与broadcast的消息发送方向相反。
• 接收进程对所有收到的消息进行归约处理。
• 归约操作:
• MAX, MIN, SUM, PROD, LAND, BAND, LOR, BOR, LXOR, BXOR, MAXLOC, MINLOC
Allreduce
MPI_Allreduce(sendbuf,recvbuf,recvcount,datatype,op,comm)
• 语法与reduce类似,但无root参数
• 所有进程都将获得结果
Reduce_scatter
MPI_Reduce_scatter(sendbuf,recvbuf,recvcount,datatype,op,comm)
• 将归约结果散播到所有进程中,给所有进程发送对应的规约结果,类似scatter。
Scan
MPI_Scan(sendbuf,recvbuf,recvcount,datatype,op,comm)
• 每一个进程都对排在它前面的进程进行归约操作。
• MPI_SCAN调用的结果是,对于每一个进程i,它对进程0,...,i的发送缓冲
区的数据进行指定的归约操作,结果存入进程i的接收缓冲区。
Alltoall
MPI_Alltoall(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype,MPI_Comm comm)
• 每个进程依次将它的发送缓冲区的第i块数据发送给第i个进程,同时每个进程又都依次从第j个进程接收数据放到各自接收缓冲区的第j块数据区的位置。
Barrier
MPI_Barrier(MPI_COMM_WORLD);
• 同步组内的所有进程。
MPI并行性能
加速比: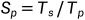
并行效率:
负载不均衡
• 由于进程间计算任务量不一致,导致并行效率不高,甚至很差。
• 需要做负载均衡。
• 根据实际情况选择合适的并行粒度。
MPI通信模式
MPI缓存区是MPI自行维护的一块内存区域,也可由用户自行维护
标准通信模式
• MPI_Send:是否缓存由MPI自行决定
缓存通信模式
• MPI_Bsend:当用户对标准通信模式不满意 希望直接对通信缓冲区进行控制时,可采用缓存通信模式,在这种模式下,由用户直接对通信缓冲区进行申请使用和释放,因此,缓存模式下对通信缓冲区的合理与正确使用是由程序设计人员自己保证的
• int MPI_Bsend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
• int MPI_Buffer_attach( void* buffer, int size) // 用户自行管理缓冲区
优缺点:
Ø 1、由于需要将数据从消息缓冲区拷贝到用户提供的缓冲区,这会产生额外的系统开销。
Ø 2、在发送方上消除了同步开销,消息发送能否进行及能否正确返回不依赖于接收进程,接收方仍然可能产生同步开销。
Ø 3、一个好处是用户可以为程序需要发送的消息提供缓冲区。但是,用户负责管理该缓冲区。如果该缓冲区大小不足以存储消息缓冲区中待发送的数据,这将会导致错误,默认情况下程序将退出。
同步通信模式
• MPI_Ssend:同步通信模式的开始不依赖于接收进程相应的接收操作是否已经启动,但是同步发送却必须等到相应的接收进程开始后才可以正确返回。
• int MPI_Ssend(void* buf, int count, MPI_Datatype datatype, int dest,int tag, MPI_Comm comm)
不足点:
Ø 1、系统开销来自将消息数据从发送方的消息缓冲区复制到网络上,以及将消息数据从网络复制到接收方的消息缓冲区中。
Ø 2、同步开销是等待另一个任务发生事件所花费的时间。发送方必须等待接收方执行 MPI_Recv 和握手到达才能传输消息。接收方在等待握手完成时也会产生一些同步开销。在同步模式下,同步开销可能很大。一种情况是MPI_Ssend比 MPI_Recv 先到达,因此发送方需要等待更长的时间;不过也有可能是MPI_Recv 比 MPI_Ssend 先到达,此时接受方需要等待更长的时间。
就绪通信模式
• MPI_Rsend:在就绪通信模式,只有当接收进程的接收操作已经启动时才可以在发送进程启动发送操作,否则,当发送操作启动而相应的接收还没有启动时,发送操作将出错,对于非阻塞发送操作的正确返回,并不意味着发送已完成,但对于阻塞发送的正确返回,则发送缓冲区可以重复使用。
• int MPI_Rsend(void* buf, int count, MPI_Datatype datatype, int dest,int tag, MPI_Comm comm)
不足点:
Ø 1、如果“准备接收”的消息尚未到达,则将会将引发错误。默认情况下,代码将退出。程序员可以将不同的错误处理程序与通信器(communicator)相关联以覆盖此默认行为。
Ø 2、就绪模式目的在于最小化发送方的系统开销和同步开销。发送方唯一需要等待的就是直到所有数据都已从发送方的消息缓冲区传输出去。接收方仍然会产生大量的同步开销,这取决于它比相应的发送早多少执行。 除非用户确定相应的接收已准备好,否则不应使用此模式。
MPI虚拟进程拓扑
在许多并行应用程序中,进程的线性排列不能充分地反映进程间在逻辑上的通信模型,通常由问题几何和所用的算法决定,进程经常被排列成二维或三维网格形式的拓扑模型,通常用一个图来描述逻辑进程排列,我们指这种逻辑进程排列为虚拟拓扑,拓扑是组内通信域上的额外、可选的属性,它不能附加在组间通信域(inter-communicator)上。拓扑能够提供一种方便的命名机制,对于有特定拓扑要求的算法使用起来直接、自然而方便。拓扑还可以辅助运行时系统,将进程映射到实际的硬件结构之上。
笛卡尔拓扑
int MPI_Cart_create(MPI_Comm comm_old, int ndims, int *dims, int *periods, int reorder, MPI_Comm *comm_cart)
IN comm_old 输入通信域,句柄
IN ndims 笛卡尔网格的维数,整数
IN dims 大小为ndims的整数,数组定义每一维的进程数,整数数组
IN periods 大小为ndims的逻辑数组,定义在一维上网格的周期性
IN reorder 标识数是否可以重排序,逻辑型
OUT comm_cart 带有新的笛卡尔拓扑的通信域,句柄
获取周围进程的坐标
int MPI_Cart_shift(MPI_Comm comm, int direction, int disp, int *rank_source, int *rank_dest)
IN comm 带有笛卡尔结构的通信域,句柄
IN direction 需要平移的坐标维,整数
IN disp 偏移量,整数
OUT rank_source 源进程的卡氏坐标
OUT rank_dest 目标进程的卡氏坐标
MPI_Cart_shift将有拓扑结构的通信域comm中的一个笛卡儿坐标rank_source 沿着指定的维direction 以偏移量disp进行平移,得到的是调用进程的笛卡儿坐标值,而调用进程的笛卡儿坐标经过同样的平移后,得到的是rank_dest。对于非周期性的拓扑,当超出范围后,rank_source与rank_dest返回为MPI_PROC_NULL,即虚拟进程。















 5014
5014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









