【问题1】 时间不是一段连续的时间戳,而是分散的。怎么办?
(1)若要对时间段降采样:
首先要设置为索引,然后才能调用 data = df.resample('M').count()['title']
(2)转化为时间类型有2种方式:
方法1:时间戳 -----连续的时间段
df['timeStamp'] = pd.to_datetime(df['timeStamp'])
df.set_index('timeStamp', inplace=True)
count_by_month = df.resample('M').count()['title']
方法2:非时间戳-----非连续的时间段
period = pd.PeriodIndex(year=df['year'],month=df['month'],day=df['day'],hour=df['hour'],freq='H')
df['datetime'] = period
df.set_index('date_time',inplace=True)
data = df.resample('7D').mean()['PM_US Post']
(3)注意:、
先添加“时间类型”列
再设置为索引
最后降采样----即时间序列的分组聚合
(4)处理缺失值
1)删除缺失值:
df['PM_US Post'].dropna()----当时间类型时,不应该用dropna方法:因为中国是前面数据缺失,若drop后,后端数据就前移了。则时间不一致。
new_df = df[ pd.notnull(df['release_data']) ]
2)填充为0
temp_grouped = temp_grouped.fiilna(0)
3)填充为均值
'''
“PM_Dongsi”,“PM_Dongsihuan”,“PM_Nongzhanguan”均为中国PM2.5的监测地点
“PM_US Post”为美国监测点
“year”,“month”,“day”,“hour”为非时间戳(分开的时间段)
'''
import pandas as pd
df = pd.read_csv('./code5(PM2.5)/BeijingPM20100101_20151231.csv')
print('\n【df.head()】')
print(df.head())
print('\n【df.info()】')
print(df.info())
print('**(1)**'*10)
period = pd.PeriodIndex(year=df['year'], month=df['month'], day=df['day'], hour=df['hour'], freq='H')
df['datetime'] = period
df.set_index('datetime', inplace=True)
print('\n【df:添加“datetime”列,并设置为索引,删除原列】')
print(df)
data = df['PM_US Post']
print('\n【未对“PM_US Post”列处理缺失值:data = df["PM_US Post"]】')
print(data)
data1 = df['PM_US Post'].dropna()
print('\n【对“PM_US Post”列处理缺失值:data1 = df["PM_US Post"].dropna()】')
print(data1)
print('**(2)**'*10)
df = df.resample('7D').mean()
print('\n【df:按照“每7天”计算平均值,代表pm2.5的值】')
print(df)
data = df['PM_US Post']
print('\n【未对“PM_US Post”列处理缺失值:data = df["PM_US Post"]】')
print(data)
data1 = df['PM_US Post'].dropna()
print('\n【对“PM_US Post”列处理缺失值:data1 = df["PM_US Post"].dropna()】')
print(data1)
print('**(3)**'*10)
【df.head()】
No year month day hour season PM_Dongsi PM_Dongsihuan \
0 1 2010 1 1 0 4 NaN NaN
1 2 2010 1 1 1 4 NaN NaN
2 3 2010 1 1 2 4 NaN NaN
3 4 2010 1 1 3 4 NaN NaN
4 5 2010 1 1 4 4 NaN NaN
PM_Nongzhanguan PM_US Post DEWP HUMI PRES TEMP cbwd Iws \
0 NaN NaN -21.0 43.0 1021.0 -11.0 NW 1.79
1 NaN NaN -21.0 47.0 1020.0 -12.0 NW 4.92
2 NaN NaN -21.0 43.0 1019.0 -11.0 NW 6.71
3 NaN NaN -21.0 55.0 1019.0 -14.0 NW 9.84
4 NaN NaN -20.0 51.0 1018.0 -12.0 NW 12.97
precipitation Iprec
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.0
4 0.0 0.0
【df.info()】
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 52584 entries, 0 to 52583
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 No 52584 non-null int64
1 year 52584 non-null int64
2 month 52584 non-null int64
3 day 52584 non-null int64
4 hour 52584 non-null int64
5 season 52584 non-null int64
6 PM_Dongsi 25052 non-null float64
7 PM_Dongsihuan 20508 non-null float64
8 PM_Nongzhanguan 24931 non-null float64
9 PM_US Post 50387 non-null float64
10 DEWP 52579 non-null float64
11 HUMI 52245 non-null float64
12 PRES 52245 non-null float64
13 TEMP 52579 non-null float64
14 cbwd 52579 non-null object
15 Iws 52579 non-null float64
16 precipitation 52100 non-null float64
17 Iprec 52100 non-null float64
dtypes: float64(11), int64(6), object(1)
memory usage: 7.2+ MB
None
**(1)****(1)****(1)****(1)****(1)****(1)****(1)****(1)****(1)****(1)**
【df:添加“datetime”列,并设置为索引,删除原列】
No year month day hour season PM_Dongsi \
datetime
2010-01-01 00:00 1 2010 1 1 0 4 NaN
2010-01-01 01:00 2 2010 1 1 1 4 NaN
2010-01-01 02:00 3 2010 1 1 2 4 NaN
2010-01-01 03:00 4 2010 1 1 3 4 NaN
2010-01-01 04:00 5 2010 1 1 4 4 NaN
... ... ... ... ... ... ... ...
2015-12-31 19:00 52580 2015 12 31 19 4 140.0
2015-12-31 20:00 52581 2015 12 31 20 4 157.0
2015-12-31 21:00 52582 2015 12 31 21 4 171.0
2015-12-31 22:00 52583 2015 12 31 22 4 204.0
2015-12-31 23:00 52584 2015 12 31 23 4 NaN
PM_Dongsihuan PM_Nongzhanguan PM_US Post DEWP HUMI \
datetime
2010-01-01 00:00 NaN NaN NaN -21.0 43.0
2010-01-01 01:00 NaN NaN NaN -21.0 47.0
2010-01-01 02:00 NaN NaN NaN -21.0 43.0
2010-01-01 03:00 NaN NaN NaN -21.0 55.0
2010-01-01 04:00 NaN NaN NaN -20.0 51.0
... ... ... ... ... ...
2015-12-31 19:00 157.0 122.0 133.0 -8.0 68.0
2015-12-31 20:00 199.0 149.0 169.0 -8.0 63.0
2015-12-31 21:00 231.0 196.0 203.0 -10.0 73.0
2015-12-31 22:00 242.0 221.0 212.0 -10.0 73.0
2015-12-31 23:00 NaN NaN 235.0 -9.0 79.0
PRES TEMP cbwd Iws precipitation Iprec
datetime
2010-01-01 00:00 1021.0 -11.0 NW 1.79 0.0 0.0
2010-01-01 01:00 1020.0 -12.0 NW 4.92 0.0 0.0
2010-01-01 02:00 1019.0 -11.0 NW 6.71 0.0 0.0
2010-01-01 03:00 1019.0 -14.0 NW 9.84 0.0 0.0
2010-01-01 04:00 1018.0 -12.0 NW 12.97 0.0 0.0
... ... ... ... ... ... ...
2015-12-31 19:00 1031.0 -3.0 SE 7.14 0.0 0.0
2015-12-31 20:00 1030.0 -2.0 SE 8.03 0.0 0.0
2015-12-31 21:00 1030.0 -6.0 NE 0.89 0.0 0.0
2015-12-31 22:00 1030.0 -6.0 NE 1.78 0.0 0.0
2015-12-31 23:00 1029.0 -6.0 NE 2.67 0.0 0.0
[52584 rows x 18 columns]
【未对“PM_US Post”列处理缺失值:data = df["PM_US Post"]】
datetime
2010-01-01 00:00 NaN
2010-01-01 01:00 NaN
2010-01-01 02:00 NaN
2010-01-01 03:00 NaN
2010-01-01 04:00 NaN
...
2015-12-31 19:00 133.0
2015-12-31 20:00 169.0
2015-12-31 21:00 203.0
2015-12-31 22:00 212.0
2015-12-31 23:00 235.0
Freq: H, Name: PM_US Post, Length: 52584, dtype: float64
【对“PM_US Post”列处理缺失值:data1 = df["PM_US Post"].dropna()】
datetime
2010-01-01 23:00 129.0
2010-01-02 00:00 148.0
2010-01-02 01:00 159.0
2010-01-02 02:00 181.0
2010-01-02 03:00 138.0
...
2015-12-31 19:00 133.0
2015-12-31 20:00 169.0
2015-12-31 21:00 203.0
2015-12-31 22:00 212.0
2015-12-31 23:00 235.0
Freq: H, Name: PM_US Post, Length: 50387, dtype: float64
**(2)****(2)****(2)****(2)****(2)****(2)****(2)****(2)****(2)****(2)**
【df:按照“每7天”计算平均值,代表pm2.5的值】
No year month day hour season PM_Dongsi \
datetime
2010-01-01 84.5 2010.0 1.000000 4.000000 11.5 4.000000 NaN
2010-01-08 252.5 2010.0 1.000000 11.000000 11.5 4.000000 NaN
2010-01-15 420.5 2010.0 1.000000 18.000000 11.5 4.000000 NaN
2010-01-22 588.5 2010.0 1.000000 25.000000 11.5 4.000000 NaN
2010-01-29 756.5 2010.0 1.571429 14.285714 11.5 4.000000 NaN
... ... ... ... ... ... ... ...
2015-11-27 51828.5 2015.0 11.428571 17.142857 11.5 3.428571 257.719512
2015-12-04 51996.5 2015.0 12.000000 7.000000 11.5 4.000000 151.024096
2015-12-11 52164.5 2015.0 12.000000 14.000000 11.5 4.000000 85.587879
2015-12-18 52332.5 2015.0 12.000000 21.000000 11.5 4.000000 201.113772
2015-12-25 52500.5 2015.0 12.000000 28.000000 11.5 4.000000 206.271084
PM_Dongsihuan PM_Nongzhanguan PM_US Post DEWP HUMI \
datetime
2010-01-01 NaN NaN 71.627586 -18.255952 54.395833
2010-01-08 NaN NaN 69.910714 -19.035714 49.386905
2010-01-15 NaN NaN 163.654762 -12.630952 57.755952
2010-01-22 NaN NaN 68.069307 -17.404762 34.095238
2010-01-29 NaN NaN 53.583333 -17.565476 34.928571
... ... ... ... ... ...
2015-11-27 174.142857 246.585366 242.642857 -6.646707 70.622754
2015-12-04 193.800000 155.072289 145.437500 -4.535714 68.714286
2015-12-11 13.020000 90.367470 88.750000 -9.446429 52.869048
2015-12-18 227.260870 201.128049 204.139241 -6.095238 73.708333
2015-12-25 219.377358 199.566265 209.244048 -8.559524 70.136905
PRES TEMP Iws precipitation Iprec
datetime
2010-01-01 1027.910714 -10.202381 43.859821 0.066667 0.786905
2010-01-08 1030.035714 -10.029762 45.392083 0.000000 0.000000
2010-01-15 1030.386905 -4.946429 17.492976 0.000000 0.000000
2010-01-22 1026.196429 -2.672619 54.854048 0.000000 0.000000
2010-01-29 1025.273810 -2.083333 26.625119 0.000000 0.000000
... ... ... ... ... ...
2015-11-27 1024.383234 -1.113772 25.372635 0.000000 0.000000
2015-12-04 1028.517857 1.511905 36.210655 0.000000 0.000000
2015-12-11 1027.886905 0.136905 77.940595 0.007186 0.010180
2015-12-18 1029.119048 -1.446429 3.948631 0.000000 0.000000
2015-12-25 1029.934524 -3.202381 8.713750 0.000000 0.000000
[313 rows x 17 columns]
【未对“PM_US Post”列处理缺失值:data = df["PM_US Post"]】
datetime
2010-01-01 71.627586
2010-01-08 69.910714
2010-01-15 163.654762
2010-01-22 68.069307
2010-01-29 53.583333
...
2015-11-27 242.642857
2015-12-04 145.437500
2015-12-11 88.750000
2015-12-18 204.139241
2015-12-25 209.244048
Freq: 7D, Name: PM_US Post, Length: 313, dtype: float64
【对“PM_US Post”列处理缺失值:data1 = df["PM_US Post"].dropna()】
datetime
2010-01-01 71.627586
2010-01-08 69.910714
2010-01-15 163.654762
2010-01-22 68.069307
2010-01-29 53.583333
...
2015-11-27 242.642857
2015-12-04 145.437500
2015-12-11 88.750000
2015-12-18 204.139241
2015-12-25 209.244048
Freq: 7D, Name: PM_US Post, Length: 313, dtype: float64
**(3)****(3)****(3)****(3)****(3)****(3)****(3)****(3)****(3)****(3)**
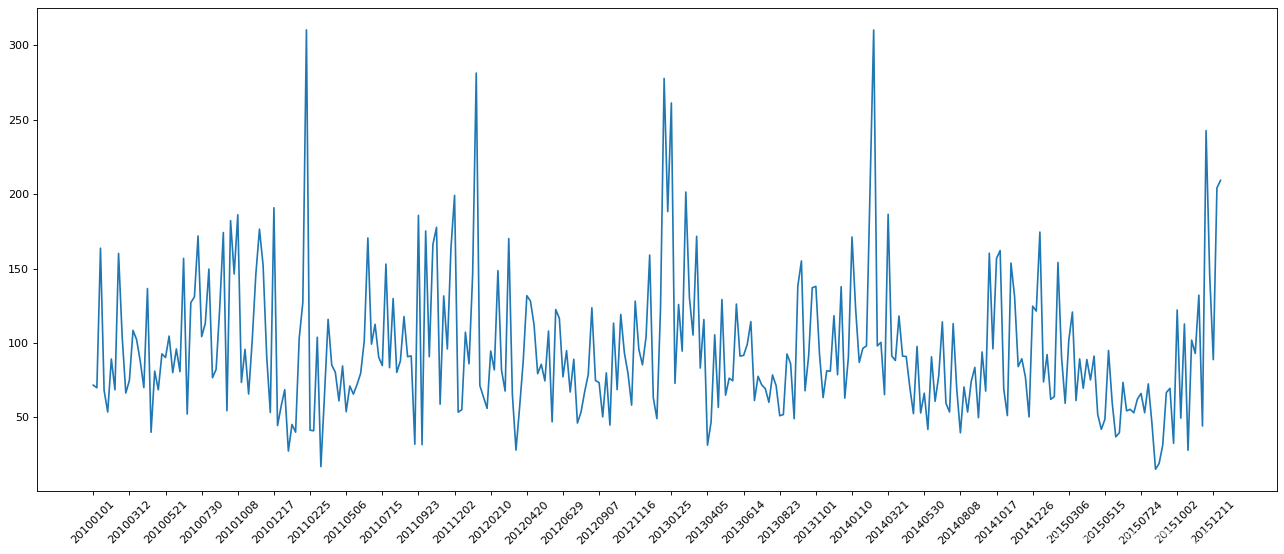
【问题2】PM2.5案例(1)------非连续时间段
问题1:
北京的PM2.5随时间的变化情况----折线图
注意:
美国监测中国
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv('./code5(PM2.5)/BeijingPM20100101_20151231.csv')
period = pd.PeriodIndex(year=df['year'], month=df['month'], day=df['day'], hour=df['hour'], freq='H')
df['datetime'] = period
df.set_index('datetime', inplace=True)
df = df.resample('7D').mean()
print(df.shape)
data = df['PM_US Post'].dropna()
_x = data.index
_y = data.values
_x = [i.strftime('%Y%m%d') for i in _x]
plt.figure(figsize=(20,8), dpi=80)
plt.plot(range(len(_x)), _y)
plt.xticks(list(range(len(_x)))[::10], list(_x)[::10], rotation=45)
plt.show()
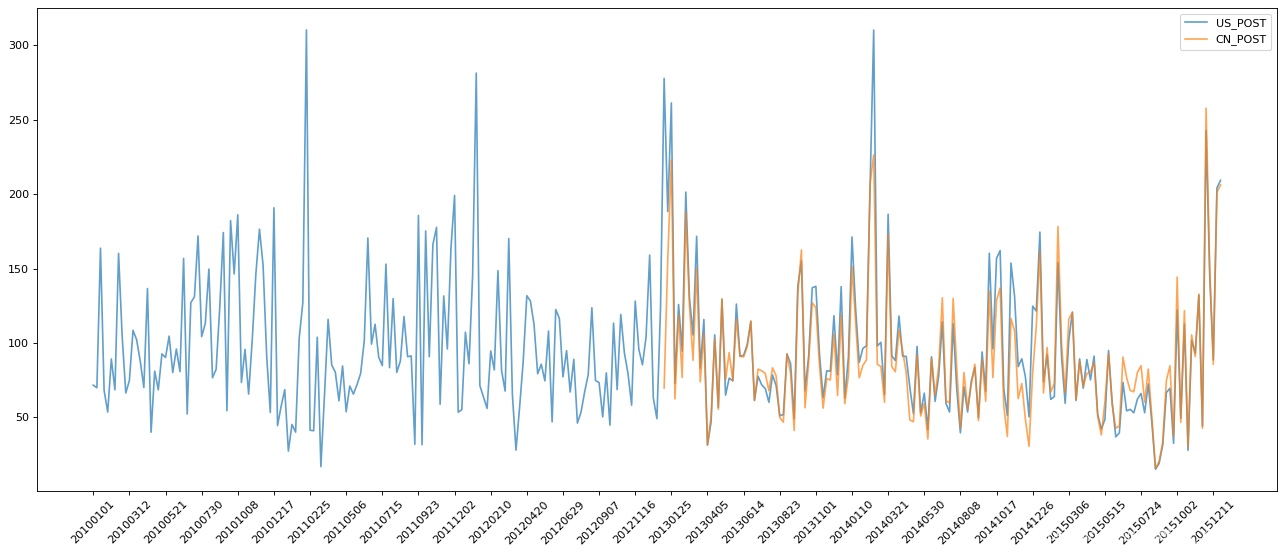
【问题3】PM2.5案例(2)------非连续时间段
问题2:
北京的PM2.5随时间的变化情况-----折线图
注意:
中国自己的监测点
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv('./code5(PM2.5)/BeijingPM20100101_20151231.csv')
period = pd.PeriodIndex(year=df['year'], month=df['month'], day=df['day'], hour=df['hour'], freq='H')
df['datetime'] = period
df.set_index('datetime', inplace=True)
df = df.resample('7D').mean()
data_us = df['PM_US Post']
data_china = df['PM_Dongsi']
print(df['PM_US Post'].tail(20))
print('*'*30)
print(df['PM_Dongsi'].tail(20))
_x = data_us.index
_y = data_us.values
_x = [i.strftime('%Y%m%d') for i in _x]
_x_china = data_china.index
_y_china = data_china.values
_x_china = [i.strftime('%Y%m%d') for i in _x_china]
print(len(_x), len(_x_china))
plt.figure(figsize=(20,8), dpi=80)
plt.plot(range(len(_x)), _y, label='US_POST', alpha=0.7)
plt.plot(range(len(_x_china)), _y_china, label='CN_POST', alpha=0.7)
plt.xticks(list(range(len(_x)))[::10], list(_x)[::10], rotation=45)
plt.legend(loc='best')
plt.show()
datetime
2015-08-14 46.365269
2015-08-21 15.142857
2015-08-28 19.029762
2015-09-04 31.339286
2015-09-11 66.662651
2015-09-18 69.500000
2015-09-25 32.531646
2015-10-02 122.142857
2015-10-09 49.453333
2015-10-16 112.732143
2015-10-23 27.886905
2015-10-30 101.875000
2015-11-06 92.946429
2015-11-13 132.101190
2015-11-20 44.220238
2015-11-27 242.642857
2015-12-04 145.437500
2015-12-11 88.750000
2015-12-18 204.139241
2015-12-25 209.244048
Freq: 7D, Name: PM_US Post, dtype: float64
******************************
datetime
2015-08-14 49.886228
2015-08-21 15.732143
2015-08-28 20.541667
2015-09-04 33.333333
2015-09-11 74.635802
2015-09-18 84.702381
2015-09-25 37.173913
2015-10-02 144.238095
2015-10-09 46.575758
2015-10-16 121.739394
2015-10-23 30.381818
2015-10-30 105.428571
2015-11-06 90.779762
2015-11-13 132.839286
2015-11-20 42.631250
2015-11-27 257.719512
2015-12-04 151.024096
2015-12-11 85.587879
2015-12-18 201.113772
2015-12-25 206.271084
Freq: 7D, Name: PM_Dongsi, dtype: float64
313 313























 8373
8373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









