







问题
根据气象局网站下载的真实观测数据,使用线性回归或者其它方法预测PM2.5的数值。
数据
数据分为train.csv和test_X.csv:
- train.csv:下面是原始数据

# 注:我把原始数据的列标签换成了英文,显示如下
import pandas as pd
train = pd.read_csv("train.csv")
print train.head(1)
'''
Date Location Observation 0 1 2 3 4 5 6 ... 14 15 16 17 18 19 20 21 22 23
0 2014/1/1 豐原 AMB_TEMP 14 14 14 13 12 12 12 ... 22 22 21 19 17 16 15 15 15 15
'''- test_X.csv:下面是原始数据
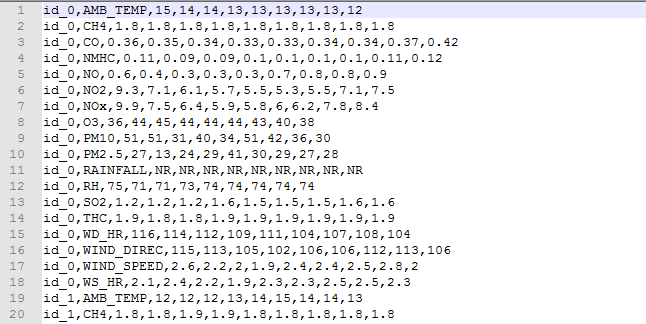
# 注:我给原始数据添加了列标签,显示如下
test = pd.read_csv("test_X.csv")
print test.head(1)
'''
Date Observation 0 1 2 3 4 5 6 7 8
0 id_0 AMB_TEMP 15 14 14 13 13 13 13 13 12
'''需要解释下数据集:关于训练数据,列标签显示的日期,地点,指标,以及24个小时该指标的测量值;横标签标示的是指标的名称,总共有18个指标,所以一天的数据就是18行;关于测试集,列标签显示的是日期,指标,以及9个小时该指标的测量值;横标签同训练集,总共有18个指标,所以一天的数据也是18行。
训练数据总共有12个月*20天*18条 = 4320条
测试数据是从每个月剩余的10天中随机抽取的不重复的240条连续九个小时的每个指标的观测数据。那么就是240*18 = 4320行。
数据处理
题目要求,用前九个小时的测量值,预测第十个小时的PM2.5的值。最简单的尝试就是,先提取出训练数据中所有的连续十个小时内的PM2.5的值将其作为训练集输入到模型中。
- 去掉无关的两列:Date Location
train = train.drop(['Date','Location'], 1)
print train.head(1)
'''
Observation 0 1 2 3 4 5 6 7 8 ... 14 15 16 17 18 19 20 21 22 23
0 AMB_TEMP 14 14 14 13 12 12 12 12 15 ... 22 22 21 19 17 16 15 15 15 15
'''- 首先提取出所有的PM2.5的数据
pm25 = train[train['Observation']=='PM2.5']
# 删除Observation列标签,便于后面提取数据
pm25.drop('Observation',1,inplace=True)
print pm25.head(3)
'''
0 1 2 3 4 ... 14 15 16 17 18 22 23
9 26 39 36 35 31 ... 36 45 42 49 45 24 13
27 21 23 30 30 22 ... 53 43 43 45 46 22 26
45 19 25 27 20 16 ... 32 36 34 45 40 23 37
''' - 由于测试数据给的是连续九个小时的PM2.5的观测数据,因此需要从训练数据中同样提取出连续十个小时的观测数据,最后一个小时的PM2.5作为该条数据的类标签,而前九个小时的PM2.5值作为特征。一天24个小时,一天内总共有24-10+1 =15条记录。
dfList = []
for i in range(15):
df = pm25.iloc[:,i:i+10]
df.columns = np.array(range(10))
dfList.append(df)
pm25 = pd.concat(dfList)
print pm25.head(3)
'''
0 1 2 3 4 5 6 7 8 9
9 26 39 36 35 31 28 25 20 19 30
27 21 23 30 30 22 18 13 13 11 22
45 19 25 27 20 16 14 15 8 4 9
'''
print pm25.shape
'''
(3600, 10)
'''
# 保存数据
pm25.to_csv("pm25.csv")- 同样先提取出测试数据中的PM2.5的数据
# 先提取出所有的PM2.5相关的数据集
pm25Test = test[test['Observation']=='PM2.5']
# 删除掉多余的属性
pm25Test.drop(['Date','Observation'],1,inplace=True)
print pm25Test .head(3)
'''
0 1 2 3 4 5 6 7 8
9 27 13 24 29 41 30 29 27 28
27 46 47 57 78 84 76 59 61 61
45 10 10 25 34 40 39 36 25 22
'''
print pm25Test.shape
'''
(240, 9)
'''
# 保存数据
pm25Test.to_csv("pm25Test.csv")预测
- 现在我们的训练集大小为3600,前九个是特征,最后一个是类标签;
测试数据集的大小是240,只有九个特征,类标签待预测;
为了更快的得到结果,我是用了weka这个数据挖掘工具,个人认为,学习数据挖掘,不要拘泥于线性代数、微积分以及各种算法编码细节,首先就是用你所掌握得知识来快速解决实际问题。首先这个问题是一个回归问题,那么我首先考虑的是简单线性回归,然后不必从头开始写线性回归算法,而是用现有的工具。如果效果可以,那么可以自己再去编码优化这个线性回归,或者拓展为其它的回归算法,至此,你可以去详细阅读有关回归的各种算法,这个时候,你会更愿意去学习线性代数和微积分等算法细节,因为你的问题急需得到解决,那么你也更有动力;
- 使用weka训练模型:
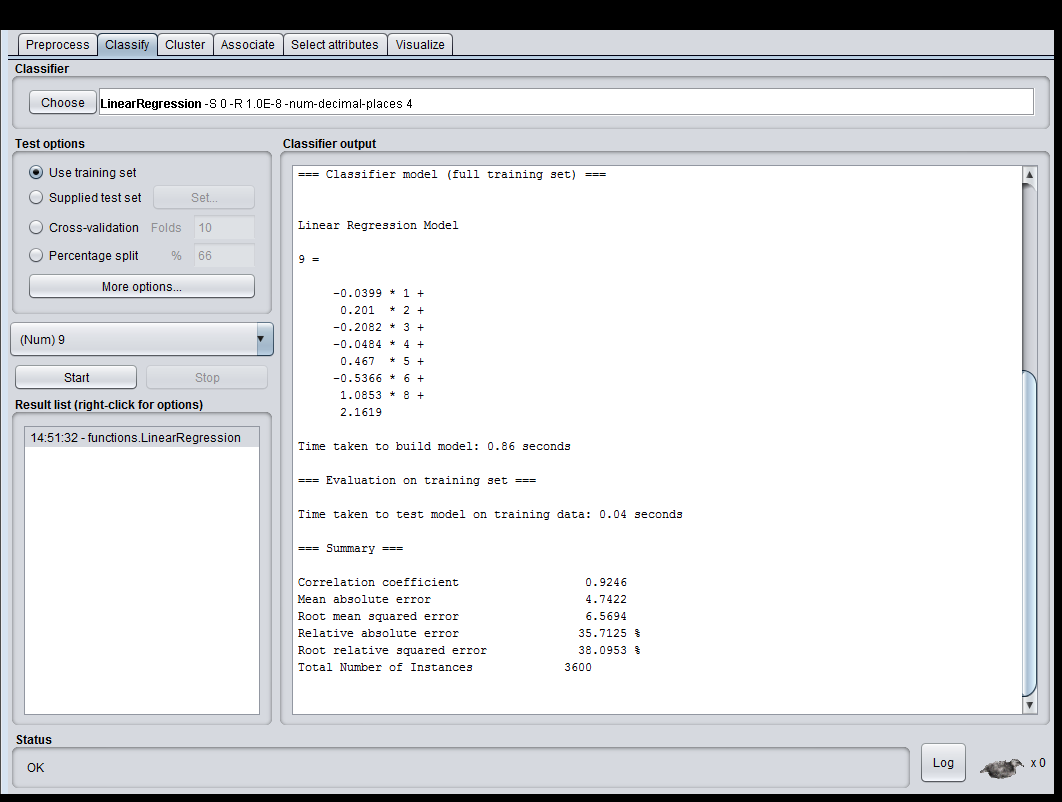
- 使用训练集得到的回归模型如下:
Linear Regression Model
9 =
-0.0399 * 1 +
0.201 * 2 +
-0.2082 * 3 +
-0.0484 * 4 +
0.467 * 5 +
-0.5366 * 6 +
1.0853 * 8 +
2.1619
- 预测
Classify->Supplied test set->pm25Test.csv->Result list->右键刚训练的模型->Re-evaluate model on current test set
需要注意的时,由于我们测试数据是没有类标签这一列的,但是weka中测试数据集的特征数要与训练集相同,那么我们添加一个class列,使其值为0,最后会生成一个预测的class列。
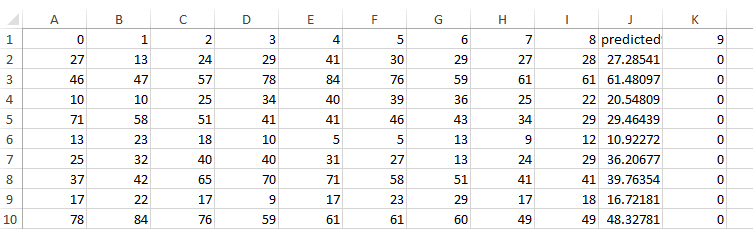
至此,预测的值已经得出,提交到kaggle(总共有240多个排名):
使用sklearn进行预测
Ordinary Least Squares : LinearRegression
- 最后得到的预测精度为5.88309
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit (train_data,train_label)
print reg.coef_
'''
array([[ 0.00729085, -0.04603342, 0.1994169 , -0.20757678, -0.0438468 ,
0.46235542, -0.54329308, 0.01552321, 1.07716736]])
'''
test_data = pd.read_csv("pm25Test.csv").values
pre = reg.predict(test_data)
np.savetxt('pre.csv', pre, delimiter = ',')Ridge Regression : Ridge
- 使用这个得到的结果是5.88309
from sklearn import linear_model
reg = linear_model.Ridge (alpha = .4) # linear_model.Lasso(alpha = 0.1)得到的结果一样
reg.fit (train_data,train_label)
print reg.coef_
'''
[[ 0.00729112 -0.04603173 0.19941234 -0.20757313 -0.04384462 0.46234831
-0.54328797 0.01552537 1.07716375]]
'''
test_data = pd.read_csv("pm25Test.csv").values
pre = reg.predict(test_data)
np.savetxt('pre.csv', pre, delimiter = ',')














 3421
3421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









