






# 微调一个掩码(mask)语言模型 (PyTorch) - 适用于 Windows Jupyter Notebook# Install the Transformers, Datasets, and Evaluate libraries to run this notebook.
# 安装运行此 notebook 所需的 Transformers, Datasets, 和 Evaluate 库。# 在 Windows Jupyter Notebook 中,请先在终端(如 Anaconda Prompt, PowerShell 或 CMD)中运行以下命令:
# pip install datasets evaluate transformers[sentencepiece] accelerate torch
# (transformers[sentencepiece] 会安装 transformers 和 sentencepiece)
# (accelerate 用于加速训练)
# (torch 是 PyTorch)
# 或者直接运行:
!pip install datasets evaluate transformers[sentencepiece]
!pip install accelerate# # To run the training on TPU, you will need to uncomment the following line:
# # !pip install cloud-tpu-client==0.10 torch==1.9.0 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.9-cp37-cp37m-linux_x86_64.whl
# !apt install git-lfs# 如果想上传到HuggingFace,你将需要设置 git,在下面的单元格中修改你的邮箱和名称。
# !git config --global user.email "you@example.com"
# !git config --global user.name "Your Name"
# 如果需要更改为在本地设置 Git 用户信息,请在 Git Bash 或其他终端中运行:
# git config --global user.email "you@example.com"
# git config --global user.name "Your Name"from transformers import AutoModelForMaskedLM # 导入 AutoModelForMaskedLM 类,用于加载预训练的掩码语言模型
model_checkpoint = "distilbert-base-uncased" # 指定预训练模型的名称 (DistilBERT 无大小写区分基础版)
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint) # 加载预训练模型distilbert_num_parameters = model.num_parameters() / 1_000_000 # 获取模型参数量并转换为百万 (M) 单位
print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'") # 打印 DistilBERT 的参数量
print(f"'>>> BERT number of parameters: 110M'") # 打印 BERT 的参数量 (作为参考)
text = "This is a great [MASK]." # 定义一个包含掩码标记 [MASK] 的示例文本from transformers import AutoTokenizer # 导入 AutoTokenizer 类,用于加载与模型匹配的 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint) # 加载与模型 "distilbert-base-uncased" 对应的 tokenizerimport torch # 导入 PyTorch 库
inputs = tokenizer(text, return_tensors="pt") # 使用 tokenizer 对文本进行编码,并返回 PyTorch 张量
token_logits = model(**inputs).logits # 将编码后的输入传递给模型,获取 logits (模型对每个词的原始预测分数)
# 找到 [MASK] 标记的位置并提取其 logits
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1] # 找到输入 ID 中 [MASK] 标记的索引
mask_token_logits = token_logits[0, mask_token_index, :] # 提取 [MASK] 标记位置的 logits
# 选择具有最高 logits 的 [MASK] 候选词
top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist() # 获取 logits最高的5个 token 的索引,并转换为列表
for token in top_5_tokens: # 遍历 top 5 tokens
print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'") # 将 [MASK] 替换为预测的词并打印

from datasets import load_dataset # 导入 load_dataset 函数,用于加载数据集
imdb_dataset = load_dataset("imdb") # 加载 IMDB 数据集
print(imdb_dataset) # 打印数据集信息
sample = imdb_dataset["train"].shuffle(seed=42).select(range(3)) # 从训练集中随机抽取3个样本 (设置种子以便复现)
for row in sample: # 遍历抽取的样本
print(f"\n'>>> Review: {row['text']}'") # 打印评论文本
print(f"'>>> Label: {row['label']}'") # 打印评论标签
def tokenize_function(examples): # 定义一个 tokenize 函数
result = tokenizer(examples["text"]) # 对 "text" 字段进行 tokenize
if tokenizer.is_fast: # 检查 tokenizer 是否是快速 tokenizer
result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))] # 如果是快速 tokenizer,则添加 word_ids
return result
# 使用 batched=True 来激活快速多线程处理
tokenized_datasets = imdb_dataset.map(
tokenize_function, batched=True, remove_columns=["text", "label"] # 对整个数据集应用 tokenize_function,并移除原始的 "text" 和 "label" 列
)
print(tokenized_datasets) # 打印处理后的数据集信息
print(tokenizer.model_max_length) # 打印 tokenizer 的模型最大长度
![]()
chunk_size = 128 # 定义块大小 (chunk_size)# 切片操作会为每个特征生成一个列表的列表
tokenized_samples = tokenized_datasets["train"][:3] # 获取训练集中的前3个 tokenized 样本
for idx, sample_input_ids in enumerate(tokenized_samples["input_ids"]): # 遍历样本的 input_ids
print(f"'>>> Review {idx} length: {len(sample_input_ids)}'") # 打印每个评论 tokenize后的长度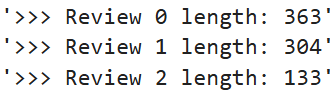
concatenated_examples = { # 将多个样本的 tokenized 特征连接起来
k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
}
total_length = len(concatenated_examples["input_ids"]) # 计算连接后 input_ids 的总长度
print(f"'>>> Concatenated reviews length: {total_length}'") # 打印连接后的总长度![]()
chunks = { # 将连接后的文本按 chunk_size 切分成块
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
for chunk in chunks["input_ids"]: # 遍历切分后 input_ids 的每个块
print(f"'>>> Chunk length: {len(chunk)}'") # 打印每个块的长度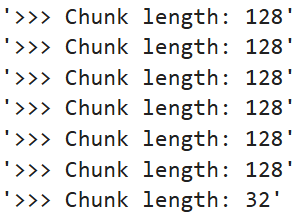
def group_texts(examples): # 定义一个函数用于将文本分组为固定大小的块
# 连接所有文本
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
# 计算连接后文本的长度
total_length = len(concatenated_examples[list(examples.keys())[0]])
# 如果最后一个块小于 chunk_size,则丢弃它
total_length = (total_length // chunk_size) * chunk_size
# 按 chunk_size 切分
result = {
k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
for k, t in concatenated_examples.items()
}
# 创建一个新的 "labels" 列,初始时与 "input_ids"相同 (用于掩码语言模型)
result["labels"] = result["input_ids"].copy()
return resultlm_datasets = tokenized_datasets.map(group_texts, batched=True) # 对 tokenized 数据集应用 group_texts 函数
print(lm_datasets) # 打印处理后的 lm_datasets 信息
print(tokenizer.decode(lm_datasets["train"][1]["input_ids"])) #解码并打印训练集中第二个样本的 input_ids,以查看分块效果
from transformers import DataCollatorForLanguageModeling # 导入用于语言模型的数据整理器
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15) # 初始化数据整理器,设置掩码概率为 15%samples = [lm_datasets["train"][i] for i in range(2)] # 从训练集中取前2个样本
for sample in samples:
_ = sample.pop("word_ids") # 移除 "word_ids" 特征,因为它不被 data_collator 使用 (在这个标准collator中)
for chunk in data_collator(samples)["input_ids"]: # 使用数据整理器处理样本,并打印处理后的 input_ids (被掩码的版本)
print(f"\n'>>> {tokenizer.decode(chunk)}'")
# 此处代码会展示 data_collator 如何随机掩码token
import collections # 导入 collections 模块,用于 defaultdict
import numpy as np # 导入 numpy 库
from transformers import default_data_collator # 导入默认的数据整理器
wwm_probability = 0.2 # 定义全词掩码 (Whole Word Masking) 的概率
def whole_word_masking_data_collator(features): # 定义全词掩码数据整理器函数
for feature in features:
word_ids = feature.pop("word_ids") # 获取并移除 "word_ids"
# 创建词与对应 token 索引之间的映射
mapping = collections.defaultdict(list)
current_word_index = -1
current_word = None
for idx, word_id in enumerate(word_ids):
if word_id is not None:
if word_id != current_word:
current_word = word_id
current_word_index += 1
mapping[current_word_index].append(idx)
# 随机掩码词
mask = np.random.binomial(1, wwm_probability, (len(mapping),)) # 根据 wwm_probability 决定哪些词被掩码
input_ids = feature["input_ids"]
labels = feature["labels"]
new_labels = [-100] * len(labels) # 初始化新的 labels,-100 表示不计算损失
for word_id_idx in np.where(mask)[0]: # 遍历被选为掩码的词的索引
# word_id = word_id_idx.item() # 在numpy 1.20+ item()不需要了,直接用word_id_idx
for idx_in_mapping in mapping[word_id_idx]:
new_labels[idx_in_mapping] = labels[idx_in_mapping] # 将被掩码的 token 的原始 ID 放入 new_labels
input_ids[idx_in_mapping] = tokenizer.mask_token_id # 将 input_ids 中对应的 token 替换为 [MASK] token ID
feature["labels"] = new_labels
return default_data_collator(features) # 使用默认的数据整理器处理其余的特征 (如填充)samples_wwm = [lm_datasets["train"][i] for i in range(2)] # 重新从训练集中取前2个样本 (确保包含 "word_ids")
batch = whole_word_masking_data_collator(samples_wwm) # 使用全词掩码数据整理器处理样本
for chunk in batch["input_ids"]: # 打印处理后的 input_ids (应用了全词掩码)
print(f"\n'>>> {tokenizer.decode(chunk)}'")
# 此处代码会展示 whole_word_masking_data_collator 如何进行掩码
train_size = 10_000 # 定义训练集大小
test_size = int(0.1 * train_size) # 定义测试集大小 (训练集的 10%)
downsampled_dataset = lm_datasets["train"].train_test_split( # 从 lm_datasets["train"] 中划分出新的训练集和测试集
train_size=train_size, test_size=test_size, seed=42 # 设置大小和随机种子
)
print(downsampled_dataset) # 打印降采样后的数据集信息
# from huggingface_hub import notebook_login # 再次导入 (如果之前未运行或内核已重启)
# notebook_login() # 如果需要推送到 Hub,确保已登录#在终端输入: pip install "accelerate>=0.26.0"
from transformers import TrainingArguments # 导入 TrainingArguments 类,用于配置训练参数
batch_size = 64 # 定义批处理大小
# 每个 epoch 显示一次训练损失
logging_steps = len(downsampled_dataset["train"]) // batch_size # 计算每个 epoch 的步数,用于日志记录
model_name = model_checkpoint.split("/")[-1] # 从 model_checkpoint 中提取模型名称
training_args = TrainingArguments(
output_dir=f"{model_name}-finetuned-imdb", # 指定模型输出和保存的目录
overwrite_output_dir=True, # 如果输出目录已存在,则覆盖它
eval_strategy="epoch", # 每个 epoch 结束后进行评估
learning_rate=2e-5, # 设置学习率
weight_decay=0.01, # 设置权重衰减
per_device_train_batch_size=batch_size, # 设置每个设备的训练批处理大小
per_device_eval_batch_size=batch_size, # 设置每个设备的评估批处理大小
push_to_hub=False, # 修改为 False,默认不在本地运行中自动推送。如果需要推送,请设为 True 并确保已登录。
fp16=torch.cuda.is_available(), # 如果CUDA可用,则使用fp16混合精度训练 (Windows上可能需要额外配置)
logging_steps=logging_steps, # 设置日志记录步数
)from transformers import Trainer # 导入 Trainer 类,用于简化训练过程
trainer = Trainer(
model=model, # 指定要训练的模型
args=training_args, # 指定训练参数
train_dataset=downsampled_dataset["train"], # 指定训练数据集
eval_dataset=downsampled_dataset["test"], # 指定评估数据集
data_collator=data_collator, # 指定数据整理器 (这里使用标准的,非全词掩码)
tokenizer=tokenizer, # 指定 tokenizer (用于保存)
)
import math # 导入 math 库
eval_results = trainer.evaluate() # 在训练前评估模型
print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}") # 计算并打印困惑度 (Perplexity)![]()
trainer.train() # 开始训练模型
# 这会花费较长时间
eval_results_after_train = trainer.evaluate() # 训练后再次评估模型
print(f">>> Perplexity: {math.exp(eval_results_after_train['eval_loss']):.2f}") # 计算并打印训练后的困惑度
# trainer.push_to_hub() # 将训练好的模型和 tokenizer 推送到 Hugging Face Hub
# 注释掉,如果 training_args 中的 push_to_hub=True,则会自动在训练结束时调用。# 下面是使用 Accelerate 进行自定义训练循环的部分
def insert_random_mask(batch): # 定义一个函数,用于对批次数据随机插入掩码
features = [dict(zip(batch, t)) for t in zip(*batch.values())] # 将批次数据转换为特征列表
masked_inputs = data_collator(features) # 使用数据整理器进行掩码 (这里的 data_collator 是前面定义的标准掩码 collator)
# Create a new "masked_" column for each column in the dataset
# 为数据集中的每一列创建一个新的 "masked_" 列
return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()} # 返回掩码后的输入,键名添加 "masked_" 前缀# 准备评估数据集,应用掩码
downsampled_dataset_no_word_ids = downsampled_dataset.remove_columns(["word_ids"]) # 移除 "word_ids" 列,因为它不用于 insert_random_mask
eval_dataset_accelerate = downsampled_dataset_no_word_ids["test"].map(
insert_random_mask,
batched=True,
remove_columns=downsampled_dataset_no_word_ids["test"].column_names, # 移除原始列
)
eval_dataset_accelerate = eval_dataset_accelerate.rename_columns( # 重命名列以匹配模型输入
{
"masked_input_ids": "input_ids",
"masked_attention_mask": "attention_mask",
"masked_labels": "labels",
}
)
# 通常评估时不需要像训练那样对标签进行特殊处理(除非是生成任务)。
# 对于掩码语言模型,评估时的损失是基于模型对掩码位置的预测。
# 此处的 insert_random_mask 主要是为了得到一个带掩码的 input_ids 和对应的 labels。from torch.utils.data import DataLoader # 导入 DataLoader
# from transformers import default_data_collator # 之前已导入
# batch_size 已在前面定义 (e.g., 64)
train_dataloader = DataLoader(
downsampled_dataset["train"],
shuffle=True, #打乱训练数据
batch_size=batch_size,
collate_fn=data_collator, # 使用标准掩码的 data_collator
)
eval_dataloader = DataLoader(
# eval_dataset_accelerate, # 使用上面处理过的评估数据集
downsampled_dataset["test"].remove_columns(["word_ids"]), # 直接使用测试集,data_collator会处理掩码
batch_size=batch_size,
collate_fn=data_collator # 评估时也用同样的 data_collator 来创建掩码和标签
)
# 以下代码块将重新设置模型并开始 Accelerate 训练流程。from torch.optim import AdamW # 导入 AdamW 优化器
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint) # 重新加载模型,以确保从干净状态开始 Accelerate 训练
optimizer = AdamW(model.parameters(), lr=5e-5) # 初始化优化器
# 可以注释掉,因为模型和优化器将在 Accelerate prepare 步骤中处理。Trainer已经训练过一个model实例了。
# 如果想从头开始用Accelerate训练,需要重新加载模型。from accelerate import Accelerator # 导入 Accelerator
# 决定 mixed_precision 的设置
mixed_precision_setting = None
if torch.cuda.is_available():
mixed_precision_setting = 'fp16' # 如果 CUDA 可用,则使用 'fp16'
accelerator = Accelerator(mixed_precision=mixed_precision_setting)
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare( # 使用 accelerator 准备模型、优化器和数据加载器
model, optimizer, train_dataloader, eval_dataloader
)
# 注释掉这部分,因为Trainer已经完成了训练。
# 以下是一个完整的 Accelerate 训练循环示例,它通常会替换 Trainer 的使用。
# 为了避免与之前的Trainer状态混淆,这里假设我们从头开始一个新的训练过程。
# 重新设置以进行 Accelerate 演示 (如果独立运行此部分)
model_accel = AutoModelForMaskedLM.from_pretrained(model_checkpoint) # 新的模型实例
optimizer_accel = AdamW(model_accel.parameters(), lr=5e-5)
# 确保 downsampled_dataset 存在并且包含 word_ids (如果使用 WWM collator)
# 如果使用标准的 data_collator,word_ids 可以被移除
train_dataset_accel = downsampled_dataset["train"]
eval_dataset_accel = downsampled_dataset["test"]
# 如果使用全词掩码,确保 collator 是 whole_word_masking_data_collator
# data_collator_accel = whole_word_masking_data_collator
# 否则使用标准的
data_collator_accel = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
train_dataloader_accel = DataLoader(
train_dataset_accel.remove_columns(["word_ids"]) if data_collator_accel == data_collator else train_dataset_accel, # WWM collator 需要 word_ids
shuffle=True,
batch_size=batch_size, # batch_size 已定义
collate_fn=data_collator_accel,
)
eval_dataloader_accel = DataLoader(
eval_dataset_accel.remove_columns(["word_ids"]) if data_collator_accel == data_collator else eval_dataset_accel,
batch_size=batch_size,
collate_fn=data_collator_accel, # 评估时也应用同样的掩码策略
)
# accelerator = Accelerator(fp16=torch.cuda.is_available())
model_accel, optimizer_accel, train_dataloader_accel, eval_dataloader_accel = accelerator.prepare(
model_accel, optimizer_accel, train_dataloader_accel, eval_dataloader_accel
)from transformers import get_scheduler # 导入学习率调度器
num_train_epochs = 3 # 定义训练的 epoch 数量
num_update_steps_per_epoch = len(train_dataloader_accel) # 计算每个 epoch 的更新步数
num_training_steps = num_train_epochs * num_update_steps_per_epoch # 计算总的训练步数
lr_scheduler = get_scheduler( # 创建学习率调度器
"linear", # 使用线性调度器
optimizer=optimizer_accel, # 指定优化器
num_warmup_steps=0, # 设置预热步数
num_training_steps=num_training_steps, # 设置总训练步数
)# from huggingface_hub import get_full_repo_name # 导入函数以获取完整的仓库名称
# model_name_accel = "distilbert-base-uncased-finetuned-imdb-accelerate" # 定义 Accelerate 训练后的模型名称
# repo_name = get_full_repo_name(model_name_accel, token=HUGGING_FACE_HUB_TOKEN) # 获取完整仓库名,可能需要token
# print(repo_name)
# 预期输出:
# 'your-username/distilbert-base-uncased-finetuned-imdb-accelerate'
# 可以注释掉,因为需要 Hugging Face 用户名,并且通常在实际推送时才需要。# from huggingface_hub import Repository # 导入 Repository 类
# output_dir_accel = model_name_accel # 定义输出目录
# repo = Repository(output_dir_accel, clone_from=repo_name) # 初始化仓库对象
# 可以注释掉,这部分用于将模型推送到Hugging Face Hub。from tqdm.auto import tqdm # 导入 tqdm 用于显示进度条
# import torch # 已导入
# import math # 已导入
progress_bar = tqdm(range(num_training_steps)) # 初始化进度条
for epoch in range(num_train_epochs):
# Training
# 训练阶段
model_accel.train() # 将模型设置为训练模式
for batch in train_dataloader_accel:
outputs = model_accel(**batch) # 前向传播
loss = outputs.loss # 获取损失
accelerator.backward(loss) # 反向传播
optimizer_accel.step() # 更新参数
lr_scheduler.step() # 更新学习率
optimizer_accel.zero_grad() # 清空梯度
progress_bar.update(1) # 更新进度条
# Evaluation
# 评估阶段
model_accel.eval() # 将模型设置为评估模式
losses = []
for step, batch in enumerate(eval_dataloader_accel):
with torch.no_grad(): # 关闭梯度计算
outputs = model_accel(**batch)
loss = outputs.loss
losses.append(accelerator.gather(loss.repeat(batch_size))) # 收集所有设备上的损失
losses_cat = torch.cat(losses) # 这里应该是 losses_cat 不是 losses
losses_cat = losses_cat[: len(eval_dataset_accel)] # 确保长度正确
try:
perplexity = math.exp(torch.mean(losses_cat))
except OverflowError:
perplexity = float("inf")
print(f">>> Epoch {epoch}: Perplexity: {perplexity}") # 打印当前 epoch 的困惑度
# # 保存并上传 (如果配置了)
# accelerator.wait_for_everyone() # 等待所有进程完成
# unwrapped_model = accelerator.unwrap_model(model_accel) # 获取原始模型
# # unwrapped_model.save_pretrained(output_dir_accel, save_function=accelerator.save) # 保存模型
# # if accelerator.is_main_process:
# # tokenizer.save_pretrained(output_dir_accel) # 保存 tokenizer
# # repo.push_to_hub( # 推送到 Hub
# # commit_message=f"Training in progress epoch {epoch}", blocking=False
# # )
# 整个 Accelerate 训练循环被注释掉,因为它是一个独立的训练过程,与之前的 Trainer 训练是二选一的。
# 如果要运行此循环,请确保所有相关变量 (model_accel, optimizer_accel, dataloaders, output_dir_accel, repo 等) 已正确初始化。
from transformers import pipeline # 导入 pipeline 函数
# 使用 Trainer 训练并推送到 Hub 的模型 (假设已完成)
# 如果模型是公开的,可以直接加载,否则需要替换为自己的模型路径或名称
mask_filler = pipeline(
"fill-mask", model="distilbert-base-uncased" # 使用原始的 distilbert 或替换为微调后的模型,例如: f"{model_name}-finetuned-imdb"
# 如果使用了 Trainer 并推送到 Hub,可以使用 "your-username/distilbert-base-uncased-finetuned-imdb"
# 如果在本地用 Trainer 训练了,模型在 f"{model_name}-finetuned-imdb" 目录下
)
# 示例:加载本地训练的模型 (如果Trainer已运行)
# finetuned_model_path = f"{model_name}-finetuned-imdb"
# try:
# mask_filler_finetuned = pipeline("fill-mask", model=finetuned_model_path, tokenizer=tokenizer)
# except OSError: # 如果模型未训练或路径不正确
# print(f"Fine-tuned model not found at {finetuned_model_path}. Using base model.")
# mask_filler_finetuned = pipeline("fill-mask", model="distilbert-base-uncased")# text 来自之前的单元格: "This is a great [MASK]."
preds = mask_filler(text) # 使用 pipeline 进行掩码填充
for pred in preds: # 遍历预测结果
print(f">>> {pred['sequence']}") # 打印填充后的序列
# 如果使用了在IMDB上微调过的模型,结果可能更偏向电影评论的语境。
好耶,完结!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









