







文章目录
排序
若相同关键字元素间的位置关系,排序前与排序后保持一致,称此排序方法是稳定的,不能保持一致的排序方法则称为不稳定的。内排序:待排序列完全存放在内存中。外排序:排序过程中还需访问外存,待排序列不能完全放入内存。本文只介绍内排序。
一、插入排序
将待排序的数据按其关键字大小依次插入到前面已排序的数据序列的适当位置上。
1. 直接插入排序
方法:用顺序查找的方法找出待插入元素应该插入的位置。对于有n个数据元素的待排序序列,直接插入排序要进行n-1趟,待排序序列用数组和链表存放均可。
#include <iostream>
#include <vector>
using namespace std;
void InsertSort(vector<int>& arr)
{
int n = arr.size();
for (int i = 1; i < n; i++)
{
int temp = arr[i];
int j;
for (j = i; j > 0 && arr[j - 1] > temp; j--)
{
arr[j] = arr[j - 1];
}
arr[j] = temp;
}
}
int main()
{
vector<int> num = { 53,27,36,15,69,42 };
InsertSort(num);
for (auto v : num)
{
cout << v << " ";
} // 15 27 36 42 53 69
cout << endl;
system("pause");
return 0;
}


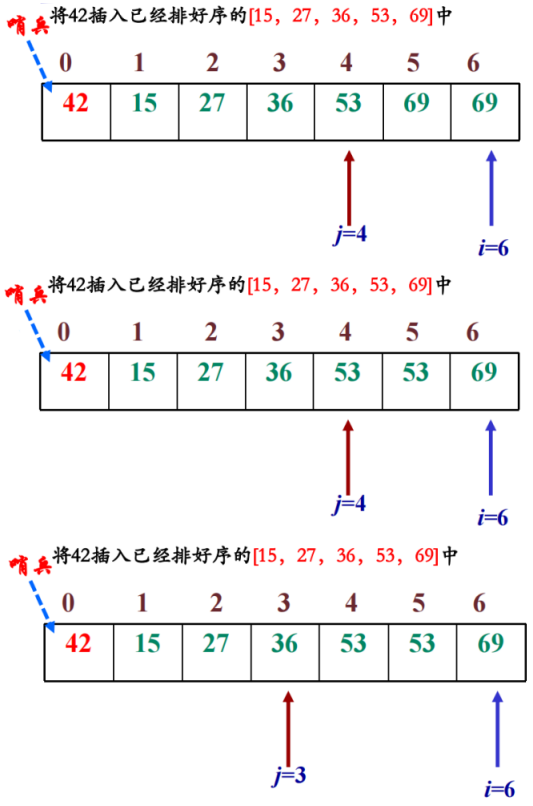
2. 二分查找排序
方法:用二分查找方法找出找出待插入元素应该插入的位置。对于有n个数据元素的待排序序列,二分插入排序要进行n-1趟,是一种稳定的排序算法,待排序序列必须存放于数组。
#include <iostream>
#include <vector>
using namespace std;
void BinsertSort(vector<int>& arr)
{
int i, j, temp;
int low, high, mid;
int n = arr.size();
// 从第二个元素开始
for (i = 1; i < n; i++)
{
// 第 i 个元素比前面已经有序的 i-1 个元素中最大的数要小
if (arr[i - 1] > arr[i])
{
temp = arr[i];
low = 0;
high = i - 1;
// 二分查找
while (low <= high)
{
mid = (low + high) / 2;
if (temp < arr[mid])
{
high = mid - 1;
}
else
{
low = mid + 1;
}
}
for (j = i - 1; j >= high + 1; j--)
{
arr[j + 1] = arr[j];
}
// 最后插入的位置是 low 或 high + 1
arr[high + 1] = temp;
}
}
}
int main()
{
vector<int> num = { 53,27,36,15,69,42 };
BinsertSort(num);
for (auto v : num)
{
cout << v << " ";
} // 15 27 36 42 53 69
cout << endl;
system("pause");
return 0;
}
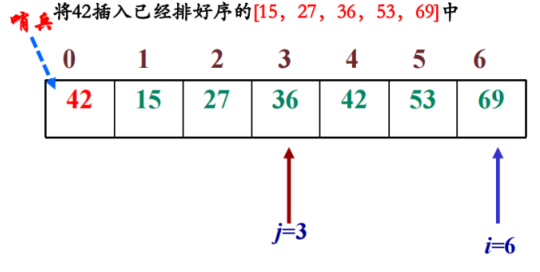
二分插入排序第五趟:

3. 希尔排序
方法:希尔排序将大问题分割为小问题 , 每一小问题采用直接插入排序,所有小问题的完成使得整个待排序的数据基本有序时,再一起进行插入排序。首先设定正整数增量d1(d1< n),将待排序的数据分成d1组,各组内进行直接插入排序。然后取增量 d2 < d1,重复上述分组和排序工作,直至取 di = 1,即所有数据元素放在一个组内进行排序。
#include <iostream>
#include <vector>
using namespace std;
// 增量为d的一趟希尔排序
void ShellSort(vector<int>& arr, int d)
{
int n = arr.size();
int i, j, temp;
// 从第 d+1 个元素开始
for (i = d; i < n; i++)
{
// 第 i 个元素比前面已经有序的元素中最大的数要小
if (arr[i - d] > arr[i])
{
temp = arr[i];
for (j = i - d; j >= 0 && (arr[j] > temp); j = j - d)
{
arr[j + d] = arr[j];
}
arr[j + d] = temp;
}
}
}
int main()
{
vector<int> num = { 39,80,76,41,13,29,50,78,30,11,100,7 };
// 增量d = 4
ShellSort(num, 4);
for (auto v : num)
{
cout << v << " ";
} // 13 11 50 7 30 29 76 41 39 80 100 78
cout << endl;
// 增量d = 2
ShellSort(num, 2);
for (auto v : num)
{
cout << v << " ";
} // 13 7 30 11 39 29 50 41 76 78 100 80
cout << endl;
// 增量d = 1
ShellSort(num, 1);
for (auto v : num)
{
cout << v << " ";
} // 7 11 13 29 30 39 41 50 76 78 80 100
cout << endl;
system("pause");
return 0;
}



希尔排序是不稳定的排序算法:
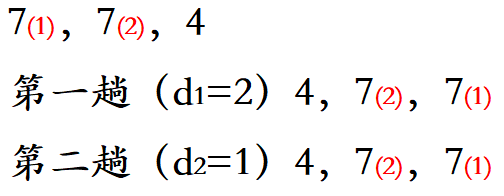
二、交换排序
两两比较待排序数据的关键字的值,并交换那些不满足顺序要求的一对,直到全部满足顺序要求为止。
1. 冒泡排序
方法:将待排序的数据元素的关键字顺次两两比较,若为逆序则将两个数据元素交换。将序列照此方法从头到尾处理一遍称作一趟冒泡排序,它将关键字值最大的数据元素交换到排序的最终位置,若某一趟冒泡排序没发生任何数据元素的交换或做完 n-1 趟,则排序过程结束。
#include <iostream>
#include <vector>
using namespace std;
void BubbleSort(vector<int>& arr)
{
int temp;
bool flag = true;
int n = arr.size();
for (int i = 0; (i < n - 1) && flag; i++)
{
flag = false;
for (int j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
flag = true;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main()
{
vector<int> num = { 25,49,56,11,65,41,36,78 };
BubbleSort(num);
for (auto v : num)
{
cout << v << " ";
} // 11 25 36 41 49 56 65 78
cout << endl;
system("pause");
return 0;
}
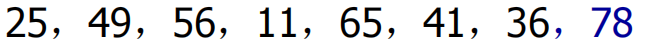

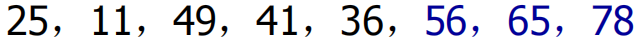
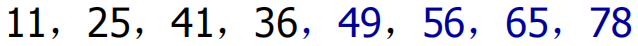

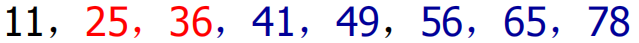
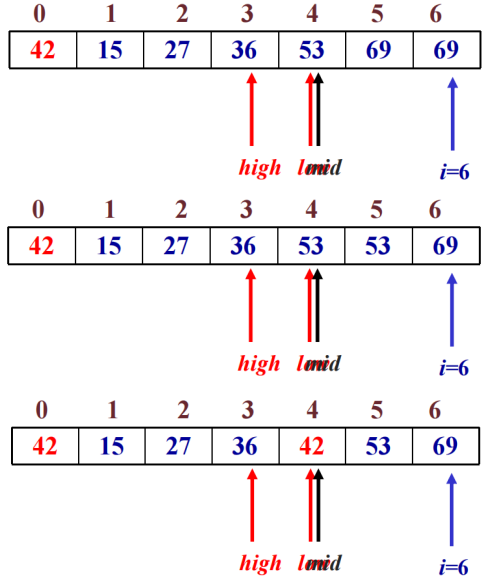
2. 快速排序
方法:在待排序的n个数据元素中任取一个数据元素(通常取第一个)为基准,用交换的方法将所有数据元素分成三部分,所有键值比它小的安置在一部分,所有键值比它大的安置在另一部分,并把该数据元素放在这两部分的中间,这也是该数据元素排序后最终位置,这个过程称为一趟快速排序。一趟快速排序,将待排序序列划分为两个子序列。然后分别对所划分的两个子序列重复上述过程,一直重复到每部分只有一个数据元素为止。
#include <iostream>
#include <vector>
using namespace std;
int partition(vector<int>& arr, int low, int high)
{
// 基准
int temp = arr[low];
while (low < high)
{
// 从 high 所指的位置向左搜索
// 与基准相等的元素放在基准的右侧
while (low < high && arr[high] >= temp)
{
high--;
}
if (low < high)
{
arr[low] = arr[high];
low++;
}
// 从 low 所指的位置向右搜索
while (low < high && arr[low] < temp)
{
low++;
}
if (low < high)
{
arr[high] = arr[low];
high--;
}
}
// 基准的最终位置
arr[low] = temp;
return low;
}
void QuickSort(vector<int>& arr, int low, int high)
{
int temp;
if (low < high)
{
temp = partition(arr, low, high);
QuickSort(arr, low, temp - 1);
QuickSort(arr, temp + 1, high);
}
}
int main()
{
vector<int> num = { 49 ,13, 38, 65, 67, 76 ,13, 50 };
QuickSort(num, 0, num.size() - 1);
for (auto v : num)
{
cout << v << " ";
} // 13 13 38 49 50 65 67 76
cout << endl;
system("pause");
return 0;
}
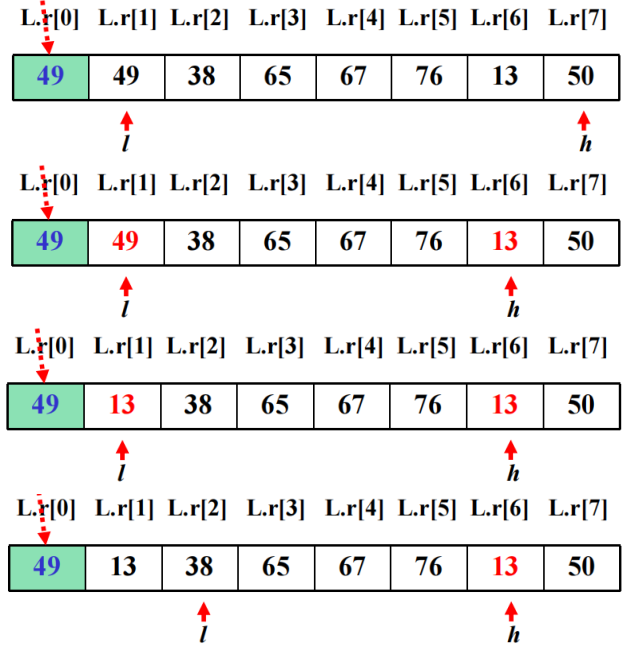
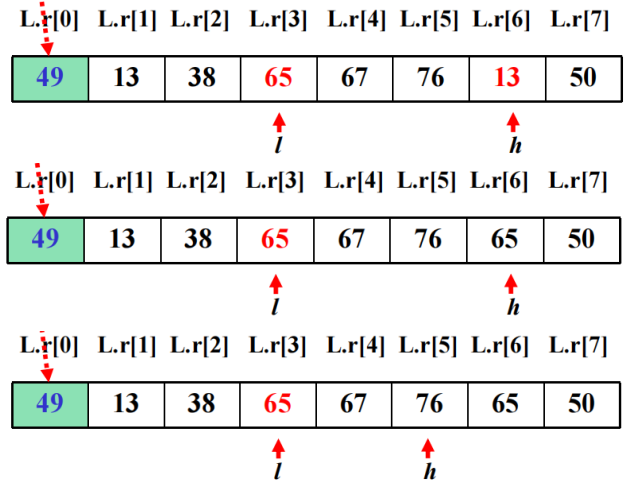
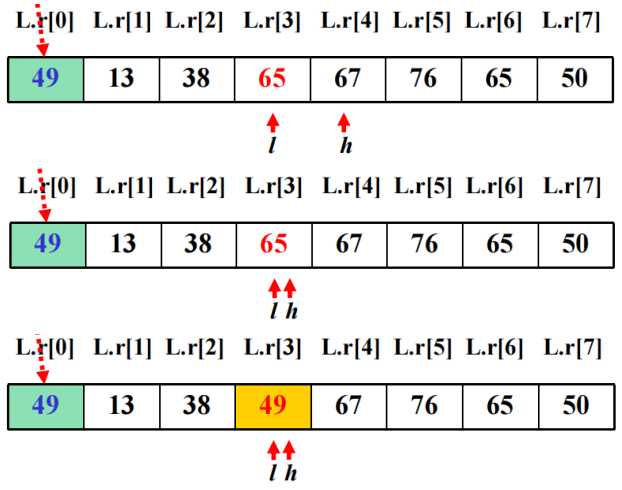
快速排序是不稳定的排序算法:

三、选择排序
每次从待排序的数据元素中选取关键字值最小的数据元素,顺序放在已排序的数据元素的最前面,直到全部排完。
1. 简单选择排序
每次从待排序的数据元素中选取关键字值最小的数据元素,顺序放在已排序的数据元素的最前面,直到全部排完。对于有n个数据元素的待排序序列,直接插入排序要进行n-1趟,适用于待排序元素较少的情况。
#include <iostream>
#include <vector>
using namespace std;
void SelectSort(vector<int>& arr)
{
int i, j, k, temp;
int n = arr.size();
// 进行 n-1 趟简单选择排序
for (i = 0; i < n - 1; i++)
{
k = i;
// 找出最小的元素
for (j = i + 1; j < n; j++)
{
if (arr[j] < arr[k])
{
k = j;
}
}
if (k != i)
{
// 交换
temp = arr[i];
arr[i] = arr[k];
arr[k] = temp;
}
}
}
int main()
{
vector<int> num = { 8,3,9,6,1 };
SelectSort(num);
for (auto v : num)
{
cout << v << " ";
} // 1 3 6 8 9
cout << endl;
system("pause");
return 0;
}

简单选择排序是不稳定的排序算法:

2. 堆排序
堆用一个一维数组存放,按完全二叉树的层次编号顺序存放。小(大)顶堆解释为:完全二叉树中任一非叶结点的值均不大(小)于它左、右孩子结点的值。根结点是堆中的最小(大)值,适用于待排序元素较多的情况。

筛选法建堆
n个数据建大顶堆,从第n/2个数据开始进行调整(从下到上、从右至左找到第一个非叶结点开始进行调整),保证以该结点为根的子树为大顶堆。一个结点调整结束后,按照从下到上、从右至左的顺序找到下一个结点继续调整,直至根结点。
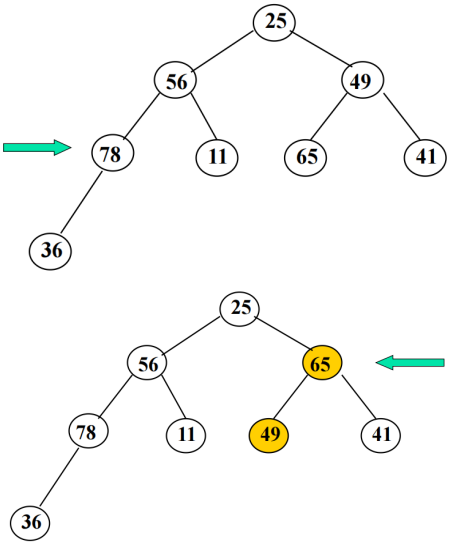
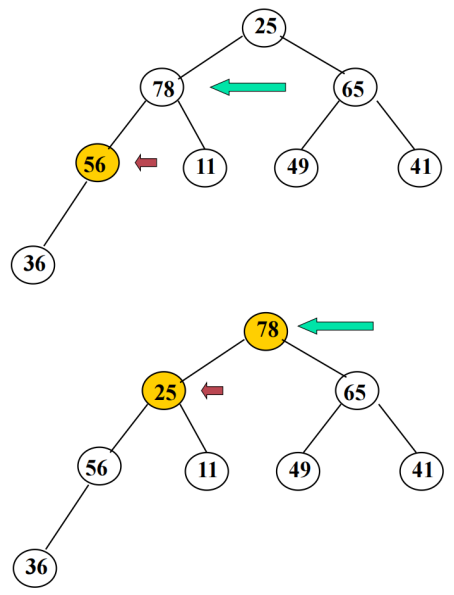
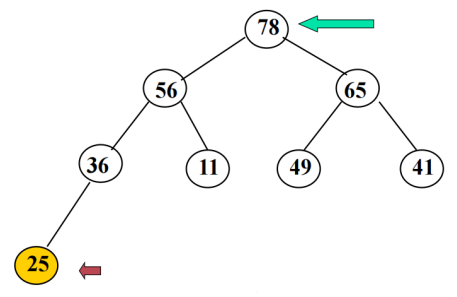
堆排序过程
将关键字值最大的数据与尚未排序的最后一个数据交换存储位置,用剩下的数据元素重建堆(称为一次调整),便得到关键字值次大的数据元素。如此反复,直到全部数据排好序。
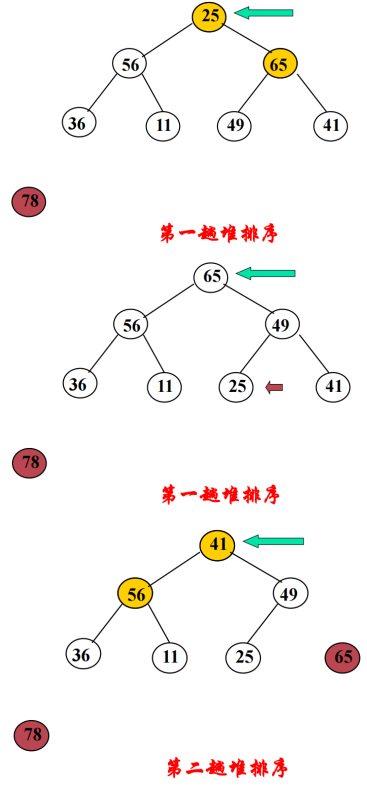

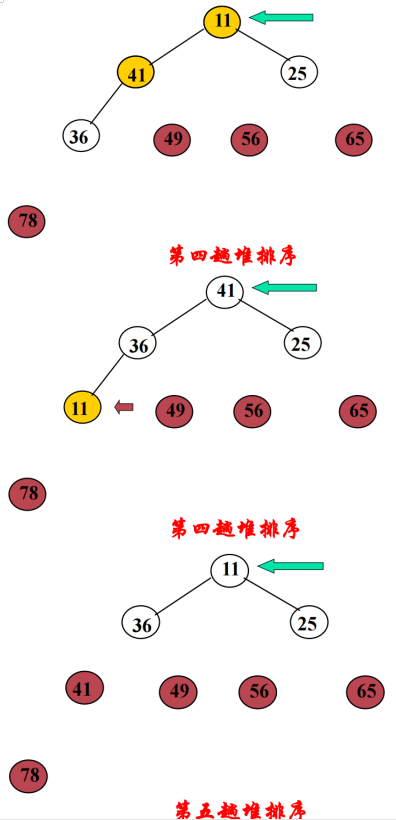


#include <iostream>
#include <vector>
using namespace std;
// i:调整的索引
// n:数组长度
void adjust(vector<int>& arr, int i, int n)
{
int temp = arr[i];
// 保证有左孩子
for (int k = 2 * i + 1; k < n; k = 2 * i + 1)
{
// 有右孩子,选择左右孩子更大的
if (k + 1 < n && arr[k] < arr[k + 1])
{
k += 1;
}
// 与该结点比较
if (temp >= arr[k])
{
break;
}
// “交换”
arr[i] = arr[k];
i = k;
}
arr[i] = temp;
}
void HeapSort(vector<int>& arr)
{
int n = arr.size();
// 初建大顶堆
for (int i = n / 2 - 1; i >= 0; i--)
{
adjust(arr, i, n);
}
// n-1趟排序
for (int k = n - 1; k > 0; k--)
{
int temp = arr[0];
arr[0] = arr[k];
arr[k] = temp;
// 重新调整
adjust(arr, 0, k);
}
}
int main()
{
vector<int> num = { 25,56,49,78,11,65,41,36 };
HeapSort(num);
for (auto v : num)
{
cout << v << " ";
} // 11 25 36 41 49 56 65 78
cout << endl;
system("pause");
return 0;
}
四、归并排序
将待排序序列划分成若干有序子序列,将两个或两个以上的有序子序列 “合并” 为一个有序序列。自顶向下划分子序列:若待排序的序列包含多于一个数据元素,则将其一分为二划分为两个子序列。总共需进行log2n(向上取整)趟,一趟归并的时间复杂度为O(n)。


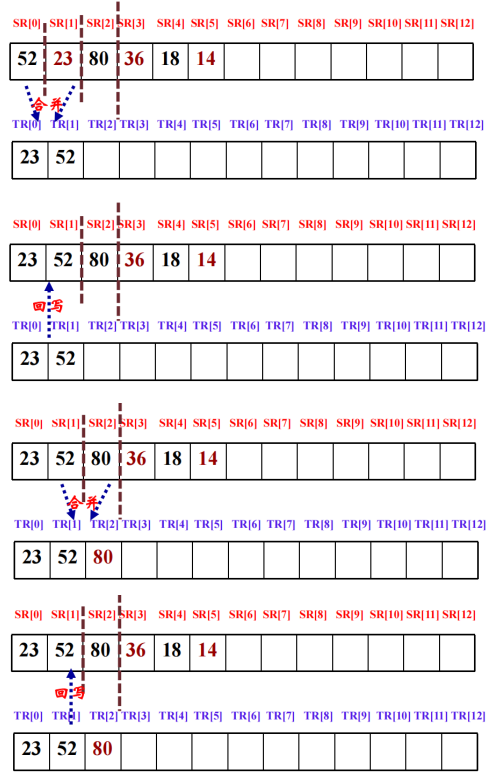
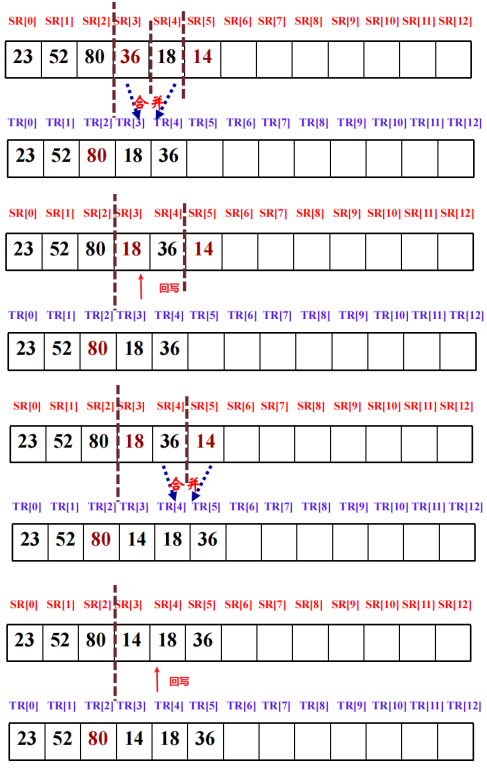
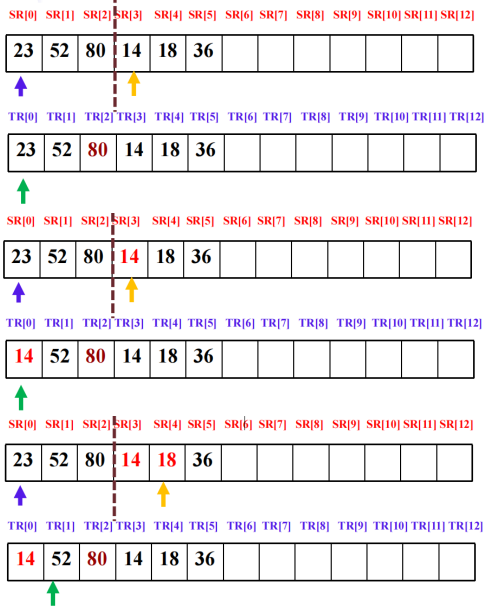
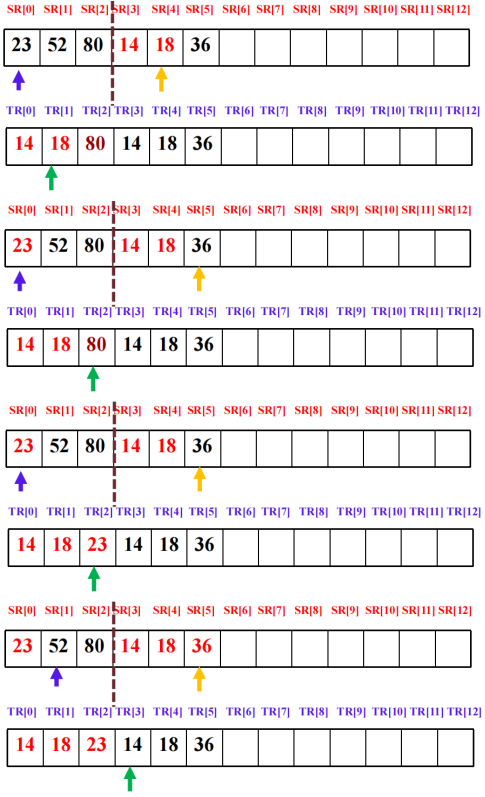

#include <iostream>
#include <vector>
using namespace std;
void merge(vector<int>& arr, vector<int>& aux, int left, int right, int mid)
{
// 复制
for (int i = left; i <= right; i++)
{
aux[i] = arr[i];
}
int i = left;
int j = mid + 1;
for (int k = left; k <= right; k++)
{
// [left, mid] 排完
if (i > mid)
{
arr[k] = aux[j];
j++;
}
// [mid+1, right] 排完
else if (j > right)
{
arr[k] = aux[i];
i++;
}
else if (aux[i] < aux[j])
{
arr[k] = aux[i];
i++;
}
else
{
arr[k] = aux[j];
j++;
}
}
}
// [left, right]
void mergeSort(vector<int>& arr, vector<int>& aux, int left, int right)
{
if (left >= right)
{
return;
}
int mid = left + (right - left) / 2;
mergeSort(arr, aux, left, mid); // [left, mid]
mergeSort(arr, aux, mid + 1, right); // [mid+1, right]
merge(arr, aux, left, right, mid);
}
void MergeSort(vector<int>& arr)
{
// 辅助数组
vector<int> aux = arr;
int n = arr.size();
mergeSort(arr, aux, 0, n - 1);
}
int main()
{
vector<int> num = { 52,23,80,36,68,14 };
MergeSort(num);
for (auto v : num)
{
cout << v << " ";
} // 14 23 36 52 68 80
cout << endl;
system("pause");
return 0;
}
五、基数排序
根据待排序数据元素关键字本身的性质进行排序,适合元素关键字值集合并不大的情况。
1. 桶排序

(1)首先按照面值对所有牌进行排序,然后按照花色再次对所有牌进行排序
第一次分配:依次查看52张牌,根据其面值将其放入对应的桶中。
第一次收集:从“2”号开始,将每个桶中的牌顺次倒出,52张牌现在的顺序是4张2,4张3,4张4,…,4张K,4张A。

第二次分配:依次查看第一次收集得到52张牌,根据花色将其放入对应的桶中。
第二次收集:从黑桃桶开始依次收集,将每个桶桶口封死,桶底打开,顺次倒出每一个桶中的牌,52张牌就排好序了:13张黑桃从2到A,13张红桃从2到A,13张梅花从2到A,13张方块从2到A。

(2)首先按照花色将所有牌分成四组。然后同花色再按照面值进行排序
第一次分配:依次查看52张牌,根据花色将其放入对应的桶中。
能否和前面的方法一样将所有桶依次收集在一起?
① 一起收集:从黑桃桶开始,将每个桶中的牌顺次倒出,52张牌现在的顺序是13张黑桃,13张红桃,13 张梅花,13张红桃。得不到正确的排序结果!

② 不一起收集。先收集黑桃桶,对收集的结果按照面值进行桶排序,再收集红桃桶,对收集的结果按照面值进行桶排序…
2. 基数排序
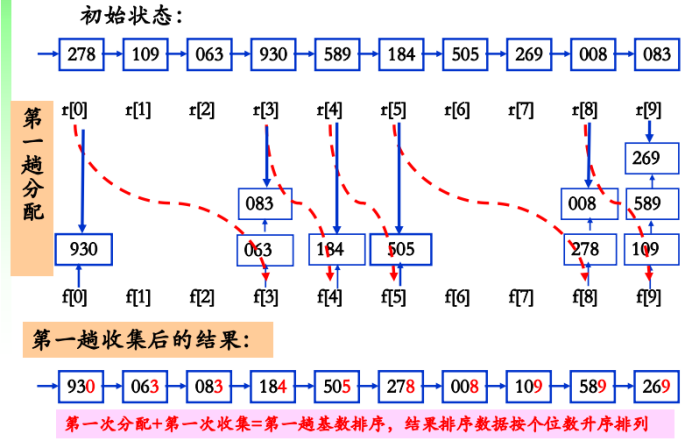
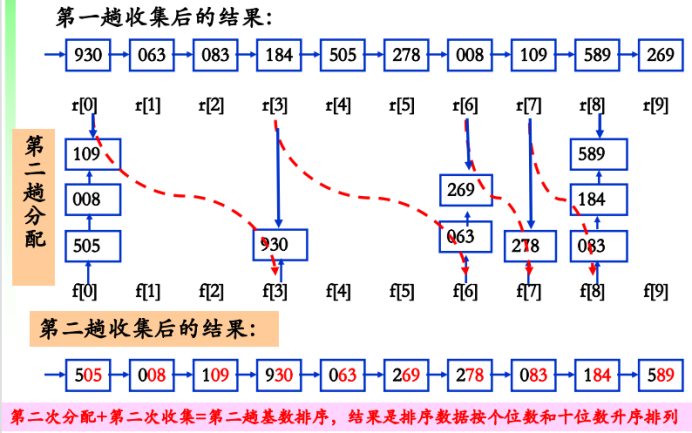
{278,109,063,930,589,184,505,269,008,083},采用低位优先基数排序。首先拆成3个关键字:个位、十位、百位,然后从个位开始进行以下三趟基数排序:首先按其“个位数”取值分配到“0, 1, …, 9”10个桶,之后按从0至9的顺序将它们“收集”在一起;然后按其“十位数”取值分配到“0, 1, …, 9”10个桶,之后按从0至9的顺序将它们 “收集”在一起;最后按其“百位数”重复一遍上述操作。
待排序记录以指针相连,构成一个链表;“分配”时,按当前“关键字位”的值,将记录分配到不同的“链队列”(桶)中,每个队列(桶)中记录的“关键字位”相同;“收集”时,按当前关键字位取值从小到大将各队列(桶)首尾相链成一个链表;对每个关键字位均重复2和3两步。
- 时间复杂度为O(d*(n+rd))。其中分配为O(n),收集为O(rd)(rd为“基”),d为“分配-收集”的趟数
- 空间复杂度为O(rd)

总结


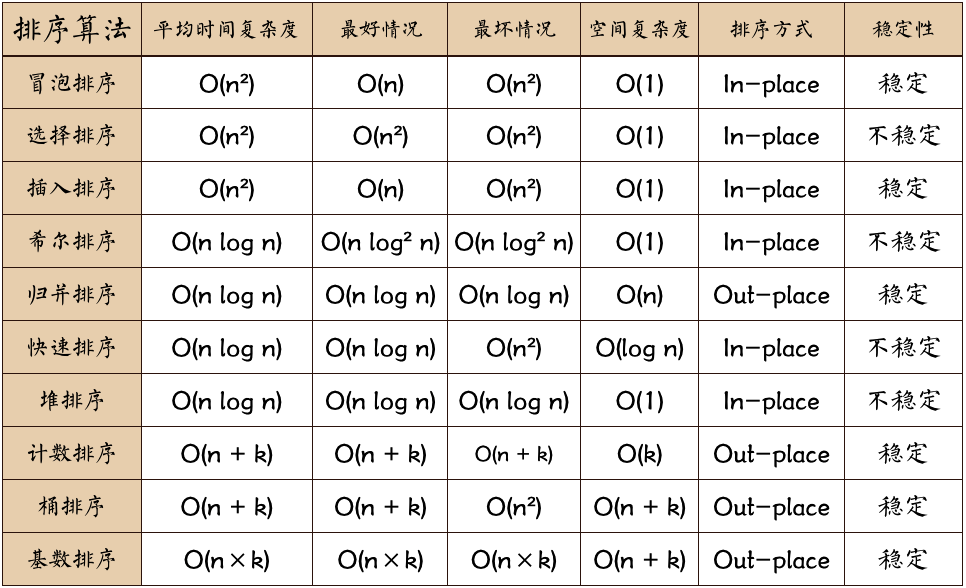
注:k为“桶”的个数。排序方式字段中,In-place代表占用常数内存,不占用额外内存。Out-place代表占用额外内存。















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









