







-
首先需要训练,训练会自动生成:latest.pth 权重文件
-
根据权重文件生成“.pkl”文件;
下面以faster_rcnn为例,–out是只生成的权重文件地址,result是生成的pkl文件名;
python ./tools/test.py ./configs/faster_rcnn_r50_fpn_1x.py ./work_dirs/faster_rcnn_r50_fpn_1x/latest.pth --out=result.pkl
- 绘制混淆矩阵
以faster_rcnn算法为例
# !python tools/analysis_tools/confusion_matrix.py -h
!python tools/analysis_tools/confusion_matrix.py \
configs/faster_rcnn/faster-rcnn_r50_fpn_2x_voc_cc.py \
work_dirs/faster-rcnn_r50_fpn_2x_voc/result_epoch_24.pkl \
work_dirs/faster-rcnn_r50_fpn_2x_voc \
--show
参考网站:https://zhuanlan.zhihu.com/p/607576946
- 计算FLOPs和Params
python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
其中,“CONFIG_FILE”代表当前使用的算法,“INPUT_SHAPE”代表输入图像的尺寸,我每次输入都报错,很难受。
案例:
python tools/get_flops.py tools/analysis_tools/get_flops.py configs/faster_cnn/faster_cnn_r50_fpn_1x.coco.py
由于每次输入:[–shape ${INPUT_SHAPE}],都报错,所以我没有输入,在py文件里面改默认值作为输入。
后面我找到方法了,如下:
python tools/get_flops.py tools/analysis_tools/get_flops.py configs/faster_cnn/faster_cnn_r50_fpn_1x.coco.py --shape 1000 608
其中,“–shape 1000 608”代表输入图片的大小,“3,1000,608”代表3通道
参考文献:https://zhuanlan.zhihu.com/p/607576946
- 输出FPS,我用的官方提供的代码,但是总是有问题,可能因为我的数据集是VOC格式的,因此,我在网上重新找一个一个代码,代替官方的 “benchmark.py” 代码,内容如下:
import argparse
import time
import torch
from mmcv import Config, DictAction
from mmcv.cnn import fuse_conv_bn
from mmcv.parallel import MMDataParallel
from mmcv.runner import load_checkpoint, wrap_fp16_model
from mmdet.datasets import (build_dataloader, build_dataset,
replace_ImageToTensor)
from mmdet.models import build_detector
def parse_args():
parser = argparse.ArgumentParser(description='MMDet benchmark a model')
parser.add_argument('config', help='test config file path')
parser.add_argument('checkpoint', help='checkpoint file')
parser.add_argument(
'--log-interval', default=1, help='interval of logging')
parser.add_argument(
'--fuse-conv-bn',
action='store_true',
help='Whether to fuse conv and bn, this will slightly increase'
'the inference speed')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
args = parser.parse_args()
return args
def main():
args = parse_args()
cfg = Config.fromfile(args.config)
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
# import modules from string list.
if cfg.get('custom_imports', None):
from mmcv.utils import import_modules_from_strings
import_modules_from_strings(**cfg['custom_imports'])
# set cudnn_benchmark
if cfg.get('cudnn_benchmark', False):
torch.backends.cudnn.benchmark = True
cfg.model.pretrained = None
cfg.data.test.test_mode = True
# build the dataloader
samples_per_gpu = cfg.data.test.pop('samples_per_gpu', 1)
if samples_per_gpu > 1:
# Replace 'ImageToTensor' to 'DefaultFormatBundle'
cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)
dataset = build_dataset(cfg.data.test)
data_loader = build_dataloader(
dataset,
samples_per_gpu=1,
workers_per_gpu=cfg.data.workers_per_gpu,
dist=False,
shuffle=False)
# build the model and load checkpoint
cfg.model.train_cfg = None
model = build_detector(cfg.model, test_cfg=cfg.get('test_cfg'))
fp16_cfg = cfg.get('fp16', None)
if fp16_cfg is not None:
wrap_fp16_model(model)
load_checkpoint(model, args.checkpoint, map_location='cpu')
if args.fuse_conv_bn:
model = fuse_conv_bn(model)
model = MMDataParallel(model, device_ids=[0])
model.eval()
# the first several iterations may be very slow so skip them
num_warmup = 5
pure_inf_time = 0
# benchmark with 2000 image and take the average
for i, data in enumerate(data_loader):
torch.cuda.synchronize()
start_time = time.perf_counter()
with torch.no_grad():
model(return_loss=False, rescale=True, **data)
torch.cuda.synchronize()
elapsed = time.perf_counter() - start_time
if i >= num_warmup:
pure_inf_time += elapsed
if (i + 1) % args.log_interval == 0:
fps = (i + 1 - num_warmup) / pure_inf_time
print(f'Done image [{i + 1:<3}/ 2000], fps: {fps:.1f} img / s')
if (i + 1) == 2000:
pure_inf_time += elapsed
fps = (i + 1 - num_warmup) / pure_inf_time
print(f'Overall fps: {fps:.1f} img / s')
break
if __name__ == '__main__':
main()
记得直接复制粘贴即可。
如下图所示,记得把“config”和"checkpoint"这两个文件配置好即可。
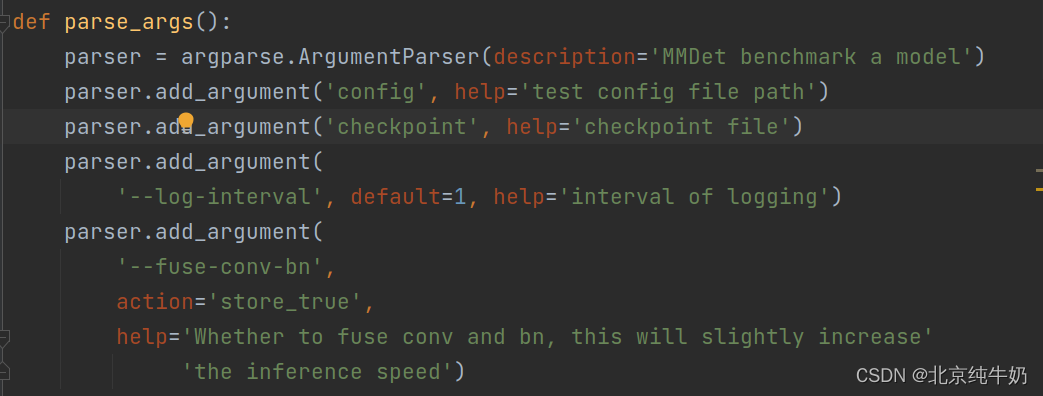
运行代码如下:
python tools/analysis_tools/benchmark_new.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py configs/faster_rcnn_log_faster_rcnn_r50_fpn_1x_coco/latest.pth --fuse-conv-bn
运行结果如下所示:
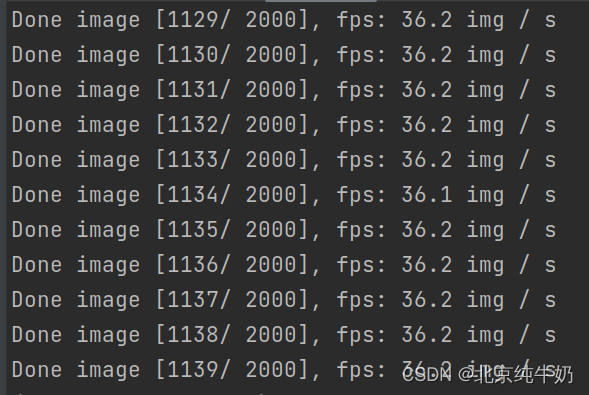
上面的问题是输出了每个图片的,如果需要平均值,请用下面的代码:
import argparse
import time
import torch
from mmcv import Config, DictAction
from mmcv.cnn import fuse_conv_bn
from mmcv.parallel import MMDataParallel
from mmcv.runner import load_checkpoint, wrap_fp16_model
from mmdet.datasets import (build_dataloader, build_dataset,
replace_ImageToTensor)
from mmdet.models import build_detector
def parse_args():
parser = argparse.ArgumentParser(description='MMDet benchmark a model')
parser.add_argument('config', help='test config file path')
parser.add_argument('checkpoint', help='checkpoint file')
parser.add_argument(
'--log-interval', default=1, help='interval of logging')
parser.add_argument(
'--fuse-conv-bn',
action='store_true',
help='Whether to fuse conv and bn, this will slightly increase'
'the inference speed')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
args = parser.parse_args()
return args
def main():
args = parse_args()
cfg = Config.fromfile(args.config)
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
# import modules from string list.
if cfg.get('custom_imports', None):
from mmcv.utils import import_modules_from_strings
import_modules_from_strings(**cfg['custom_imports'])
# set cudnn_benchmark
if cfg.get('cudnn_benchmark', False):
torch.backends.cudnn.benchmark = True
cfg.model.pretrained = None
cfg.data.test.test_mode = True
# build the dataloader
samples_per_gpu = cfg.data.test.pop('samples_per_gpu', 1)
if samples_per_gpu > 1:
# Replace 'ImageToTensor' to 'DefaultFormatBundle'
cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)
dataset = build_dataset(cfg.data.test)
data_loader = build_dataloader(
dataset,
samples_per_gpu=1,
workers_per_gpu=cfg.data.workers_per_gpu,
dist=False,
shuffle=False)
# build the model and load checkpoint
cfg.model.train_cfg = None
model = build_detector(cfg.model, test_cfg=cfg.get('test_cfg'))
fp16_cfg = cfg.get('fp16', None)
if fp16_cfg is not None:
wrap_fp16_model(model)
load_checkpoint(model, args.checkpoint, map_location='cpu')
if args.fuse_conv_bn:
model = fuse_conv_bn(model)
model = MMDataParallel(model, device_ids=[0])
model.eval()
# the first several iterations may be very slow so skip them
num_warmup = 5
pure_inf_time = 0
ii = 0
sum = 0
sum1 = 0
# benchmark with 2000 image and take the average
count = 0
sum = 0
for i, data in enumerate(data_loader):
# print(i)
# print(data)
# print(0000)
torch.cuda.synchronize()
start_time = time.perf_counter()
with torch.no_grad():
model(return_loss=False, rescale=True, **data)
torch.cuda.synchronize()
elapsed = time.perf_counter() - start_time
#if i >= num_warmup:
pure_inf_time += elapsed
#if (i + 1) % args.log_interval == 0:
count += 1
print('count:',count)
fps = (i + 1 - num_warmup) / pure_inf_time
print('fps:', fps)
sum += fps
print('sum:', sum)
# print(fps)
print(sum/count)
#print(f'Done image [{i + 1:<3}/ 2000], fps: {fps:.1f} img / s')
sys.stdout = Logger(sys.stdout) # record log
# sys.stderr = Logger(sys.stderr) # record error
#print('fps: ', sum/count, 'img/s')
if (i + 1) == 2000:
pure_inf_time += elapsed
fps = (i + 1 - num_warmup) / pure_inf_time
# print(fps+'00000000')
print(f'Overall fps: {fps:.1f} img / s')
# print(".1f")
break
import sys, os, time
sys.setrecursionlimit(3000)
class Logger(object):
def __init__(self, stream=sys.stdout):
output_dir = "./config/" # folder
if not os.path.exists(output_dir):
os.makedirs(output_dir)
#log_name = '{}.txt'.format(time.strftime('%Y-%m-%d-%H-%M',time.localtime(time.time())))
log_name_time = time.strftime('%Y-%m-%d-%H-%M-%S',time.localtime(time.time()))
log_name = log_name_time + ".txt"
filename = os.path.join(output_dir, log_name)
self.terminal = stream
self.log = open(filename, 'a+')
def write(self, message):
self.terminal.write(message)
self.log.write(message)
def flush(self):
pass
if __name__ == '__main__':
main()
5.输出 json result file
This command will output “results.bbox.json” file.
python tools/test.py [configs_file] [pth] --eval-options "jsonfile_prefix=results_name" --eval bbox
由于我的我数据集本身就算VOC的格式,但是我想生成APs,APm,APl这个三个评价指标。记住,这三个评价指标是coco数据集格式才有的,所有折腾了很久,想要生成这些指标用这个mmdetectio生,必须先把数据集的格式转换成coco的格式,否则会一直报错。
我们转换的时候使用的是mmdetection自带的py文件,代码如下:
python tools/dataset_converters/pascal_voc.py ../../../data/devkit ../../../data/coco
主要是通过使用voc的xml文件生成coco的json标签文件。然后,把图片复制到coco的数据集下面。
如下图所示,一个是voc格式的,一个是coco格式的,转换之后如下图所示。
python tools/dataset_converters/pascal_voc.py data/VOCdevkit -o data/coco --out-format coco
转换之后我们使用的是tools/test.py或者直接使用mmdet/datasets/coco.py
提醒一下,tools/test.py是一边测试一边转换,mmdet/datasets/coco.py是直接测试,因此需要先生成“.pkl”文件,所以会快很多。 “pkl”生成方式需要用“pth”文件生成,可以参考第一个问题。
如果你的方法还是voc格式的,需要把方法设置成coco格式的,否则不对应,因此你调用tools/test.py或者mmdet/datasets/coco.py`的时候会调用这个coco数据集,就是之前说的那种格式,记得理论上只需要更改“test”集就行,其他的可以不用动。因此,你调用的时候测试集去测试你需要的APs.APm,APl这三个评价指标。
mmdet/datasets/coco.py这个文件记得把“CLASSES”改一下,上面好像说错了,运行的不是mmdet/datasets/coco.py文件。但是,这个地方最好还是改改。方法里面好像需要调用
CLASSES = ('fire', 'yanwu',)
我们以faster_r_cnn为例,修改之后的coco方法如下,记得我们只修改了测试集,因为我们之是测试,不会进行验证。
model = dict(
type='FasterRCNN',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=2,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)))
dataset_type = 'VOCDataset'
data_root = '/home/yuan3080/桌面/detection_paper_6/mmdetection-master1/mmdetection-master_yanhuo/data/VOCdevkit/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1000, 600), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1000, 600),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type='VOCDataset',
ann_file=[
'/home/yuan3080/桌面/detection_paper_6/mmdetection-master1/mmdetection-master_yanhuo/data/VOCdevkit/VOC2007/ImageSets/Main/trainval.txt',
'/home/yuan3080/桌面/detection_paper_6/mmdetection-master1/mmdetection-master_yanhuo/data/VOCdevkit/VOC2007/ImageSets/Main/trainval.txt'
],
img_prefix=[
'/home/yuan3080/桌面/detection_paper_6/mmdetection-master1/mmdetection-master_yanhuo/data/VOCdevkit/VOC2007/',
'/home/yuan3080/桌面/detection_paper_6/mmdetection-master1/mmdetection-master_yanhuo/data/VOCdevkit/VOC2007/'
],
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1000, 600), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
])),
val=dict(
type='VOCDataset',
ann_file=
'/home/yuan3080/桌面/detection_paper_6/mmdetection-master1/mmdetection-master_yanhuo/data/VOCdevkit/VOC2007/ImageSets/Main/test.txt',
img_prefix=
'/home/yuan3080/桌面/detection_paper_6/mmdetection-master1/mmdetection-master_yanhuo/data/VOCdevkit/VOC2007/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1000, 600),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
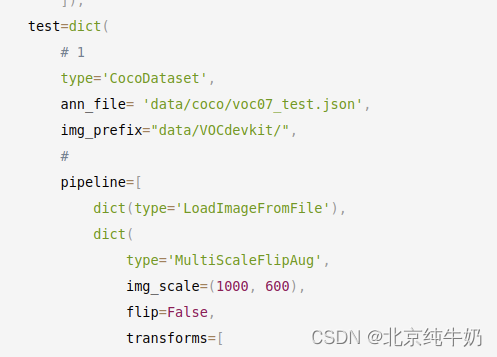
test=dict(
# 1
type='CocoDataset',
ann_file= 'data/coco/voc07_test.json',
img_prefix="data/VOCdevkit/",
#
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1000, 600),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
evaluation = dict(interval=1, metric='bbox') #
optimizer = dict(type='SGD', lr=0.001, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=100)
checkpoint_config = dict(interval=20)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
auto_scale_lr = dict(enable=False, base_batch_size=32)
work_dir = 'configs/faster_rcnn_log_faster_rcnn_r50_fpn_1x_coco/'
auto_resume = False
gpu_ids = [0]
记得观察下面的路径和type,其他的貌似没有需要改的了,如果有需要改得可以多尝试。
在“eval_metric.py“文件下运行的代码如下:
python tools/analysis_tools/eval_metric.py configs/faster_rcnn_log_faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco1.py result.pkl --eval bbox
生成的效果如下所示。
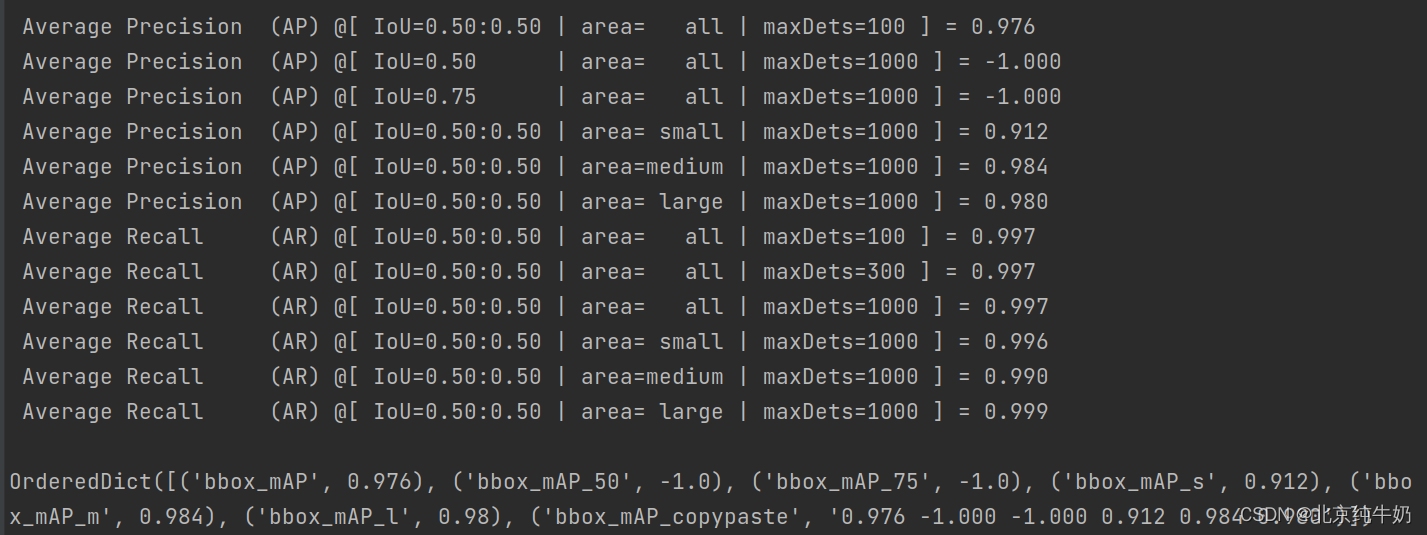
在“test.py“文件下运行的代码如下:
python tools/test.py configs/faster_rcnn_log_faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco1.py configs/faster_rcnn_log_faster_rcnn_r50_fpn_1x_coco/latest.pth --eval bbox
效果如下所示。
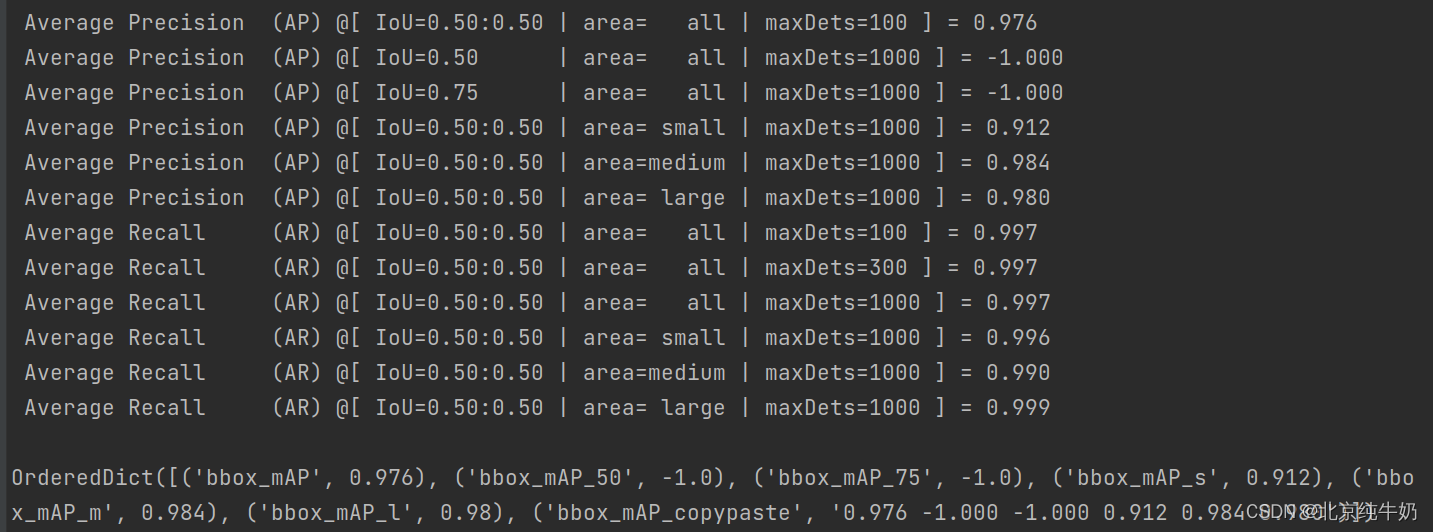
















 2549
2549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









