







字符编码概念
很久以前,计算机制造商有自己的表示字符的方式。他们并不需要担心如何和其它计算机交流,并提出了各自的方式来将字形渲染到屏幕上。随着计算机越来越流行,厂商之间的竞争更加激烈,在不同的计算机体系间转换数据变得十分蛋疼,人们厌烦了这种自定义造成的混乱。
最终,计算机制造商一起制定了一个标准的方法来描述字符。他们定义使用一个字节的低7位来表示字符,并且制作了如上图所示的对照表来映射七个比特的值到一个字符上。例如,字母A是65,c是99,~是126等等, ASCII码就这样诞生了。原始的ASCII标准定义了从0到127 的字符,这样正好能用七个比特表示。
为什么选择了7个比特而不是8个来表示一个字符呢?考虑到计算机一般把字节(Byte)作为基本单元,为了操作方便,我们不妨用一个字节(也就是 8 个比特位)来存储 ASCII。这样虽然浪费了一个比特位,但是读写效率提高了。但是一个字节是8个比特,这意味着1个比特并没有被使用,也就是从128到255的编码并没有被制定ASCII标准的人所规定,这些美国人对世界的其它地方一无所知甚至完全不关心。
其它国家的人趁这个机会开始使用128到255范围内的编码来表达自己语言中的字符。例如,144在阿拉伯人的ASCII码中是گ,而在俄罗斯的ASCII码中是ђ。即使在美国,对于未使用区域也有各种各样的利用。IBM PC就出现了“OEM 字体”或”扩展ASCII码”,为用户提供漂亮的图形文字来绘制文本框并支持一些欧洲字符,例如英镑(£)符号。
ASCII码的问题在于尽管所有人都在0-127号字符的使用上达成了一致,但对于128-255号字符却有很多很多不同的解释。你必须告诉计算机使用哪种风格的ASCII码才能正确显示128-255号的字符。
这对于北美人和不列颠群岛的人来说不算什么问题,因为无论使用哪种风格的ASCII码,拉丁字母的显示都是一样的。英国人还需要面对的问题是原始的ASCII码中不包含英镑符号,但是这个已经无关紧要了。
与此同时,在亚洲有更让人头疼的问题。亚洲语言有更多的字符和字形需要被存储,一个字节已经不够用了。所以他们开始使用两个字节来存储字符,这被称作DBCS(双字节编码方案)。在DBCS中,字符串操作变得很蛋疼,你应该怎么做str++或str–?
这些问题成为了系统开发者的噩梦。例如,MS DOS必须支持所有风格的ASCII码,因为他们想把软件卖到其他国家去。他们提出了「内码表」这一概念。例如,你需要告诉DOS(通过使用”chcp”命令)你想使用保加利亚语的内码表,它才能显示保加利亚字母。内码表的更换会应用到整个系统。这对使用多种语言工作的人来说是一个问题,因为他们必须频繁的在几个内码表之间来回切换。
尽管内码表是一个好主意,但是它不是一个简洁的解决方案,它只是一个hack技术或者说是简单的修正来让编码系统可以工作。
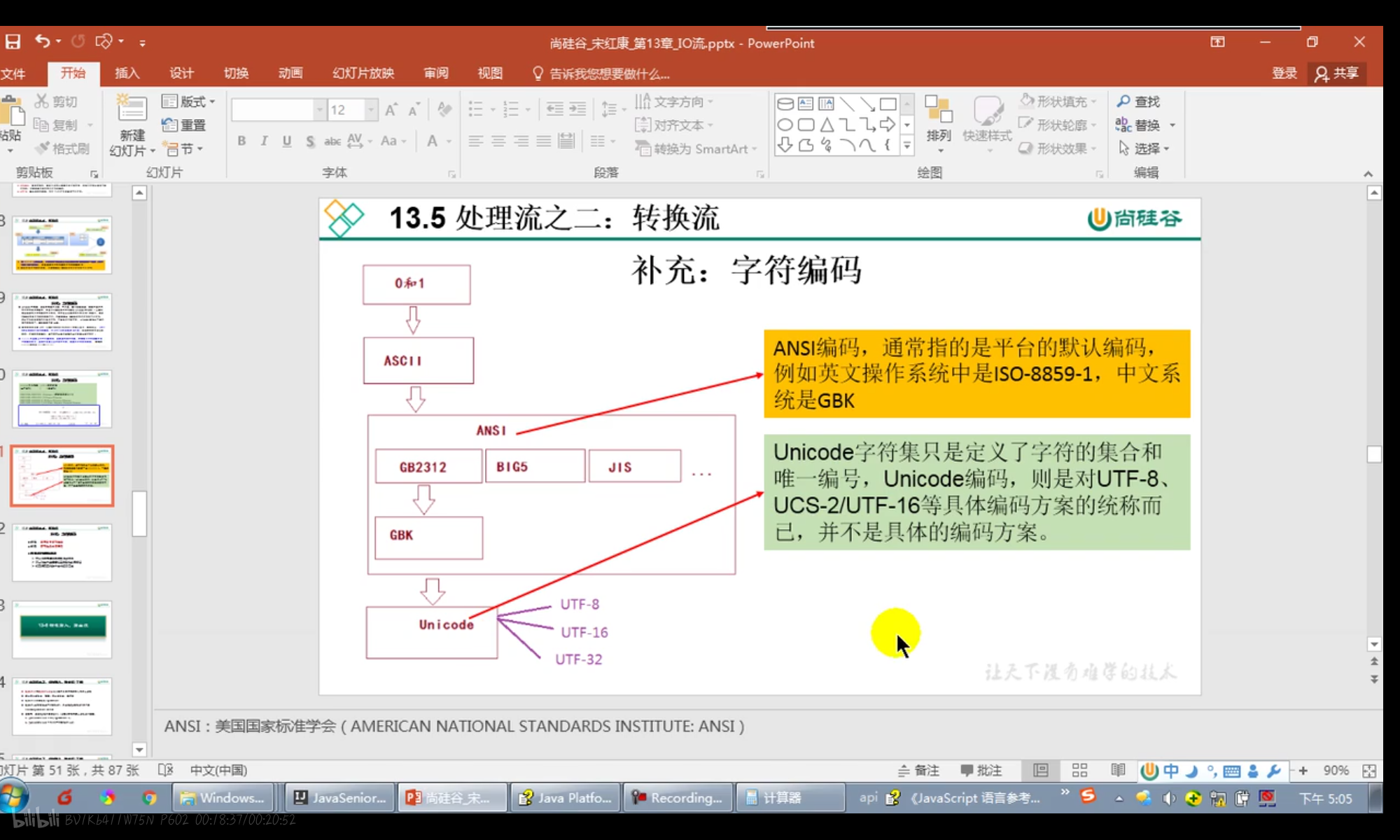
字符集为每个字符分配了一个唯一的编号,通过这个编号就能找到对应的字符。在编程过程中我们经常会使用字符,而使用字符的前提就是把字符放入内存中,毫无疑问,放入内存中的仅仅是字符的编号,而不是真正的字符实体。
进入Unicode的世界
最终,美国人意识到他们应该提出一种标准方案来展示世界上所有语言中的所有字符,以便缓解程序员的痛苦和避免字符编码引发的第三次世界大战。出于这个目的,Unicode诞生了。
Unicode背后的想法非常简单,然而却被普遍的误解了。Unicode就像一个电话本,标记着字符和数字之间的映射关系。Joel称之为「神奇数字」,因为它们可能是随机指定的,而且不会给出任何解释。官方术语是码位(Code Point),总是用U+开头。理论上每种语言中的每种字符都被Unicode协会指定了一个神奇数字。例如希伯来文中的第一个字母א,是U+2135,字母A是U+0061。
Unicode并不涉及字符是怎么在字节中表示的,它仅仅指定了字符对应的数字,仅此而已。
关于Unicode的其它误解包括:Unicode支持的字符上限是65536个,Unicode字符必须占两个字节。告诉你这些的人应该去换换脑子了。
记住,Unicode只是一个用来映射字符和数字的标准。它对支持字符的数量没有限制,也不要求字符必须占两个、三个或者其它任意数量的字节。
Unicode字符是怎样被编码成内存中的字节这是另外的话题,它是被UTF(Unicode Transformation Formats)定义的。但是对于 Unicode,问题就没有这么简单了。Unicode 目前已经包含了上百万的字符,位置靠前的字符用一个字节就能存储,位置靠后的字符用两个字节才能存储。我们可以为所有字符都分配两个字节的内存,也可以为编号小的字符分配一个字节的内存,而为编号大的字符分配两个字节的内存。
字符集和字符编码不是一个概念,字符集定义了文字和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将文字的编号存储到内存中。有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的;有的字符集只管制定字符的编号,至于怎么编码,是其他人的事情。
编码定义了两件事:
1,字节是怎么分组的,如8 bits或16 bits一组,这也被称作编码单元。
2,编码单元和字符之间的映射关系。例如,在ASCII码中,十进制65映射到字母A上
方案1:为每个字符分配固定长度的内存
一种方案是为每个字符分配固定长度的内存,并且这块内存要足够大,可以容纳下所有的字符编号。这种方案最简单,直接将字符编号放入内存中即可,不需要任何转换,并且以后在字符串中定位字符、修改字符都非常容易。
方案2:为每个字符分配尽量少的内存
把空闲的内存压缩掉,为每个字符分配尽量少的字节,例如,A和3分配一个字节足以,中分配两个字节
对于第一种方案,每个字符占用的字节数是固定的,很容易区分各个字符;而这种方案,不同的字符占用的字节数不同,字符之间也没有特殊的标记,计算机是无法定位字符的。
这种方案还需要改进,必须让不同的字符编码有不同的特征,并且字符处理程序也需要调整,要根据这些特征去识别不同的字符。
要想让不同的字符编码有不同的特征,可以从两个方面下手:
- 一是从字符集本身下手,在设计字符集时,刻意让不同的字符编号有不同的特征。
例如,对于编号较小的、用一个字节足以容纳的字符,我们就可以规定这个字符编号的最高位(Bit)必须是 0;对于编号较大的、要用两个字节存储的字符,我们就可以规定这个字符编号的高字节的最高位必须是 1,低字节的最高位必须是 0;对于编号更大的、需要三个字节存储的字符,我们就可以规定这个字符编号的所有字节的最高位都必须是 1。
程序在定位字符时,从前往后依次扫描,如果发现当前字节的最高位是 0,那么就把这一个字节作为一个字符编号。如果发现当前字节的最高位是 1,那么就继续往后扫描,如果后续字节的最高位是 0,那么就把这两个字节作为一个字符编号;如果后续字节的最高位是 1,那么就把挨着的三个字节作为一个字符编号。
这种方案的缺点很明显,它会导致字符集不连续,中间留出大量空白区域,这些空白区域不能定义任何字符。
- 二是从字符编号下手,可以设计一种转换方案,字符编号在存储之前先转换为有特征的、容易定位的编号,读取时再按照相反的过程转换成字符本来的编号。
那么,转换后的编号要具备什么样的特征呢?其实也可以像上面一样,根据字节的最高位是 0 还是 1 来判断字符到底占用了几个字节。
相比第一种方案,这种方案有缺点也有优点:
- 缺点就是多了转换过程,字符在存储和读取时要经过转换,效率低;
- 优点就是在制定字符集时不用考虑存储的问题,可以任意排布字符。
Unicode 是一个独立的字符集,它并不是和编码绑定的,你可以采用第一种方案,为每个字符分配固定长度的内存,也可以采用第二种方案,为每个字符分配尽量少的内存。
需要注意的是,Unicode 只是一个字符集,在制定的时候并没有考虑编码的问题,所以采用第二种方案时,就不能从字符集本身下手了,只能从字符编号下手,这样在存储和读取时都要进行适当的转换。
Unicode 可以使用的编码有三种,分别是:
- UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
1) UTF-8
UTF-8 的编码规则很简单:如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
- 0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
- 110xxxxx 10xxxxxx:双字节编码形式;
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式;
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式。
xxx 就用来存储 Unicode 中的字符编号。
下面是一些字符的编码实例(绿色部分表示本来的 Unicode 编号):
| 字符 | N | æ | ⻬ |
|---|---|---|---|
| Unicode 编号(二进制) | 01001110 | 11100110 | 00101110 11101100 |
| Unicode 编号(十六进制) | 4E | E6 | 2E EC |
| UTF-8 编码(二进制) | 01001110 | 11000011 10100110 | 11100010 10111011 10101100 |
| UTF-8 编码(十六进制) | 4E | C3 A6 | E2 BB AC |
对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6个字节存储。
2) UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
3) UTF-16
UFT-16 比较奇葩,它使用 2 个或者 4 个字节来存储。
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
如果你不理解什么意思,请看下面的表格:
| Unicode 编号范围 (十六进制) | 具体的 Unicode 编号 (二进制) | UTF-16 编码 | 编码后的 字节数 |
|---|---|---|---|
| 0000 0000 ~ 0000 FFFF | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx | 2 |
| 0001 0000—0010 FFFF | yyyy yyyy yyxx xxxx xxxx | 110110yy yyyyyyyy 110111xx xxxxxxxx | 4 |
位于 D800~0xDFFF 之间的 Unicode 编码是特别为四字节的 UTF-16 编码预留的,所以不应该在这个范围内指定任何字符。如果你真的去查看 Unicode 字符集,会发现这个区间内确实没有收录任何字符。
UTF-16 要求在制定 Unicode 字符集时必须考虑到编码问题,所以真正的 Unicode 字符集也不是随意编排字符的。
总结
只有 UTF-8 兼容 ASCII,UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码。
GB2312、Shift-JIS 等国家(地区)字符集怎么编码
GB2312、GBK、Shift-JIS 等特定国家的字符集都是在 ASCII 的基础上发展起来的,它们都兼容 ASCII,所以只能采用变长的编码方案:用一个字节存储 ASCII 字符,用多个字节存储本国字符。
以 GB2312 为例,该字符集收录的字符较少,所以使用 1~2 个字节编码。
- 对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0;
- 对于中国的字符,使用两个字节存储,并且规定每个字节的最高位都是 1。
由于单字节和双字节的最高位不一样,所以很容易区分一个字符到底用了几个字节。
最后附上二进制转ACSII的代码
/*
二进制转ASCII码
*/
@Test
public void toAscii() throws IOException {
File file = new File("test.txt");
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String s = bufferedReader.readLine();
while(s != null) {
if(isZeroOrOne(s)) {
for (int i = 0; i <= s.length() - 8; i+= 8) {
String substring = s.substring(i,i + 8);
int numasc = Integer.parseInt(substring, 2);
System.out.print((char)numasc);//强制转换成char类型,并输出
}
}
s = bufferedReader.readLine();
}
}
public static boolean isZeroOrOne(String str) {
Pattern pattern = Pattern.compile("^[0,1]*$");
return pattern.matcher(str).matches();
}















 4191
4191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









