







赫夫曼树以及赫夫曼编码
赫夫曼树的基本介绍:
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree), 还有的书翻译为霍夫曼树。赫夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
如下图中第二个树才是赫夫曼树,因为它的wpl值最小

赫夫曼树的几个重要概念:
1)、路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1
2)、结点的权及带权路径长度:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
3)、树的带权路径长度:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL(weighted path length) ,权值越大的结点离根结点越近的二叉树才是最优二叉树。
4)、WPL最小的就是赫夫曼树
题目描述:
给你一个数列 {13, 7, 8, 3, 29, 6, 1},要求转成一颗赫夫曼树
构成赫夫曼树的步骤:
- 从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个节点可以看成是一颗最简单的二叉树
- 取出根节点权值最小的两颗二叉树
- 组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和

- 再将这颗新的二叉树,以根节点的权值大小 再次排序,不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树
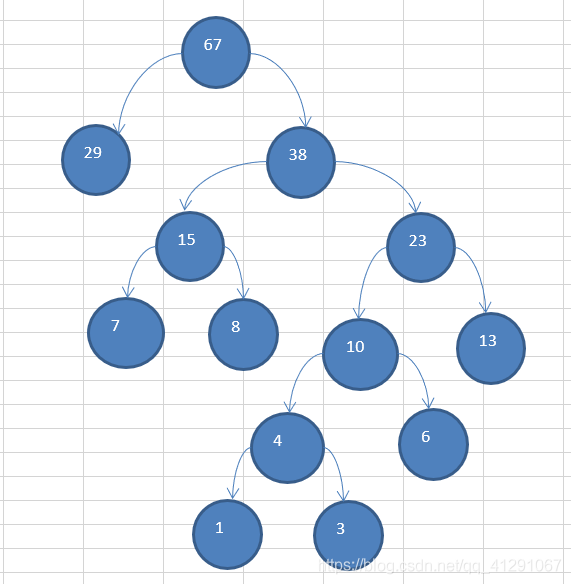
赫夫曼树类:
public class HuffmanTree {
public static int wpl = 0;
public static Node getHuffmanTree(int[] arr) {
List<Node> nodes = nodeWapper(arr);
while (nodes.size() > 1) {
Collections.sort(nodes);
Node leftNode = nodes.get(0);
Node rightNode = nodes.get(1);
Node parentNode = new Node(leftNode.value + rightNode.value);
parentNode.left = leftNode;
parentNode.right = rightNode;
nodes.remove(0);
nodes.remove(0);
nodes.add(parentNode);
}
return nodes.get(0);
}
public static void preOrder(Node node) {
System.out.println(node);
if(node.left != null) preOrder(node.left);
if(node.right != null) preOrder(node.right);
}
private static List<Node> nodeWapper(int[] arr) {
List<Node> nodes = new ArrayList<>();
for (int value : arr) {
nodes.add(new Node(value));
}
return nodes;
}
// 计算WPL
public static int getWPL(Node node) {
getWPL(node,0);
return wpl;
}
private static void getWPL(Node node,int deep) {
if(node.left == null && node.right == null) wpl += node.value * deep;
if(node.left != null) getWPL(node.left,deep + 1);
if(node.right != null) getWPL(node.right,deep + 1);
}
}
赫夫曼编码类:
import java.util.*;
/**
* @program: DataStructures
* @description: 赫夫曼编码
* @author: wxc
* @create: 2020-12-05 21:56
*
**/
// 韩顺平老师代码Bug
// 在赫夫曼压缩那里,有些Bug,
// 第一个是byte[]数组最后一个字节是负数的情况(也就是根据赫夫曼编码得到的二进制字符串能把8整除,且倒数第8位为1),因此不管flag真假第一步就是判断位数并截取
// 第二个问题是byte[]数组最后一个字节会存在丢失0的问题,如果赫夫曼编码得到的二进制字符串不能被8整除,并且最后几位是以0开头的,就会在解码的时候发生错误
// 针对这个,我的做法是在增加一个字节,用来记录二进制字符串最后几位以0开头的个数,比如0010,则最后一个字节值为2,0000则为3。在还原的时候根据最后一个字节的数值进行对应0个数填充即可。
public class HuffmanCode {
// 统计文本中每一个字符出现的次数
public Map<Byte, Integer> map;
// 赫夫曼树节点数组
public List<Node> nodes;
// 赫夫曼编码表
public Map<Byte, String> codeMap;
// 要进行压缩的字节数组(传入的)
public byte[] originalBytes;
// 经过赫夫曼编码的二进制字符串转成的字节数组,也就是压缩后的字节数组
public byte[] zipBytes;
// 赫夫曼树根结点
public Node root;
/*
* @author wxc
* @Description:获得文本中每个字符出现的权值 比如:"a" => 5,"b" => 2
*/
private void countEachChar() {
this.map = new HashMap<>(128);
for (byte b : originalBytes) {
if (!map.containsKey(b)) {
map.put(b, 1);
} else map.put(b, map.get(b) + 1);
}
}
/*
* @author wxc
* @Description: map中的key保存了文本中出现的所有字符,将字符和出现次数包装到nodes数组中
*/
private void nodeWapper() {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2376
2376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









