







RWKV-CLIP: A Robust Vision-Language Representation Learner
公和众:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
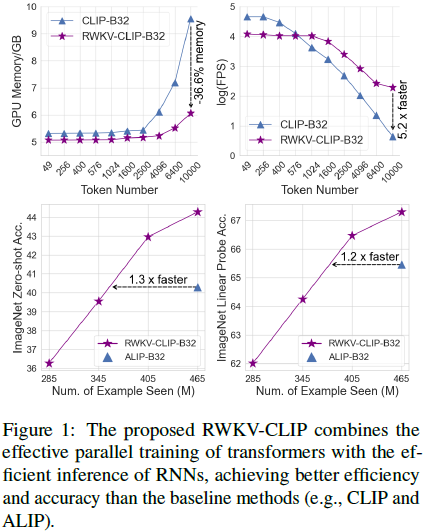
对比语言-图像预训练(CLIP)通过从网站获取图像-文本对,显著提高了各种视觉语言任务的表现。本文从数据和模型架构的角度进一步探索 CLIP。为了解决有噪数据的普遍存在并提高从互联网上抓取的大规模图像-文本数据的质量,我们引入了一个多样化的描述生成框架,可以利用大型语言模型(LLM)来合成和精炼来自网络文本、合成标题和检测标签的内容。此外,我们提出了 RWKV-CLIP,这是第一个结合了 transformer 的有效并行训练和 RNN 的高效推理的 RWKV 驱动的视觉语言表示学习模型。各个模型规模和预训练数据集的全面实验表明,RWKV-CLIP 是一个健壮且高效的视觉语言表示学习器,在几个下游任务中达到了最新的性能,包括线性探测、零样本分类和零样本图像-文本检索。
项目页面:https://github.com/deepglint/RWKV-CLIP
2. RWKV
(2023|EMNLP,RWKV,Transformer,RNN,AFT,时间依赖 Softmax,线性复杂度)
(2024,Vision-RWKV,线性复杂度双向注意力,四向标记移位)通过类似 RWKV 的架构实现高效且可扩展的视觉感知
RWKV(Peng等人,2023年)最初是在自然语言处理(NLP)中提出的,它通过高效的线性扩展解决了 Transformer 中的内存瓶颈和二次扩展问题,同时保留了并行训练和强大扩展性的表现特性。
Vision-RWKV(Duan等人,2024年)成功地将 RWKV 从 NLP 转移到视觉任务,在图像分类中表现优于 ViT,并在处理速度更快且内存消耗较少的情况下处理高分辨率输入。
PointRWKV(He等人,2024年)在各种下游任务中表现出色,超越了基于 Transformer 和 Mamba 的对应模型在效率和计算复杂性方面的表现。
Diffusion-RWKV(Fei等人,2024年)将 RWKV 适用于图像生成任务中的扩散模型,与现有的基于 CNN 或 Transformer 的扩散模型相比,取得了竞争或更优的性能。
然而,这些方法仅在特定下游任务中验证了 RWKV,而 RWKV 在视觉语言表示学习中替代 ViT 的潜力仍未得到验证。
3. 方法
3.1 多样化描述生成
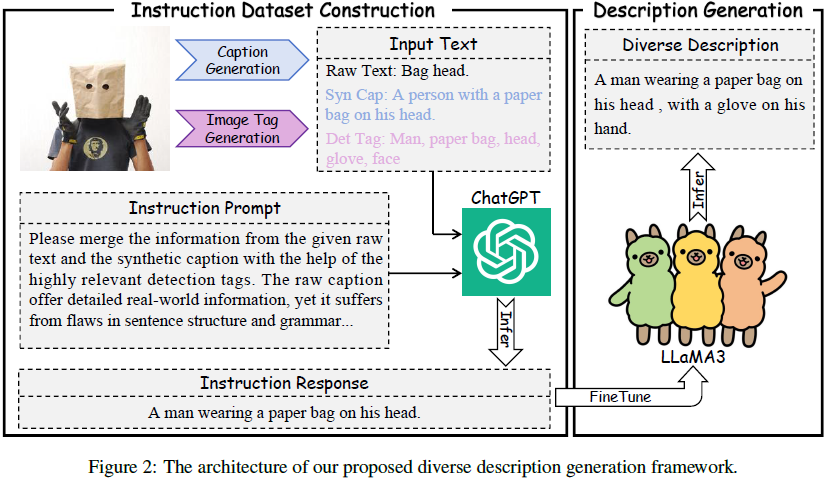
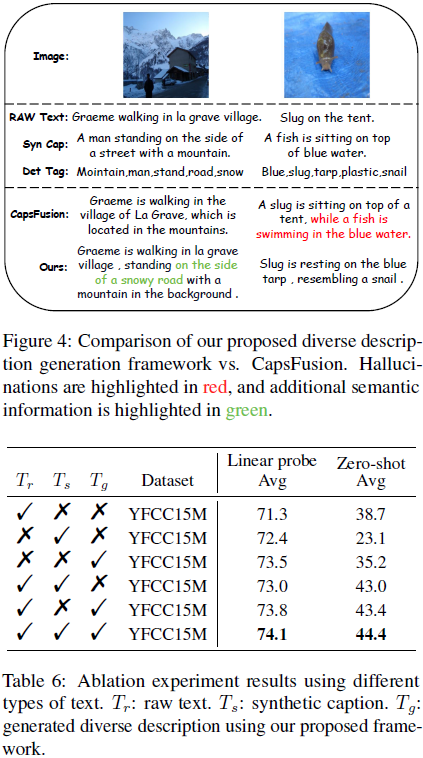
我们提出的多样化描述生成(diverse description generation)框架的架构如图 2 所示。为了减轻图像-文本对不匹配的影响,我们首先采用了 OFA_base 模型为每个图像生成合成标题(参考ALIP,Yang等人,2023年)。这些合成标题(caption)与图像具有高度的语义对齐性,有助于跨不同模态特征空间的对齐。然而,由于训练数据的限制,OFA_base 只能识别有限数量的物体类别,并且倾向于生成句子结构简单的标题。为了捕捉图像内更细粒度的语义信息,我们引入了开放集图像标签(tagging)模型 RAM++(Huang等人,2023年),为每个图像提取物体检测标签。
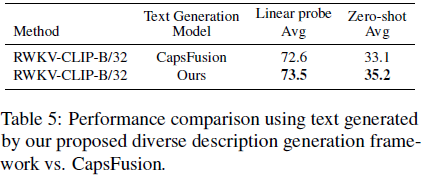
为了评估我们方法的可行性,参考 CapsFusion(Yu等人,2024年),我们最初利用 ChatGPT 结合原始文本、合成标题和检测标签的信息。然而,这涉及的时间和计算成本是相当高的。因此,我们基于 ChatGPT 的交互构建了一个指令数据集,并使用该数据集微调了开源的 LLaMA3 模型。之后,我们利用微调后的 LLaMA3 模型进行大规模推理。具体来说,我们从 YFCC15M 中选择了具有超过 10 个检测标签的 70K 图像-文本对。然后,我们将这些数据的原始文本、合成标题和检测标签输入 ChatGPT 以获取指令响应。指令提示(instruction prompt)的详细信息在补充材料中提供。
在获得指令数据集后,我们利用 LLaMA Factory(Zheng等人,2024年)微调 LLaMA3-8B,并利用vLLM(Kwon等人,2023年)加速大规模推理。
3.2 RWKV-CLIP
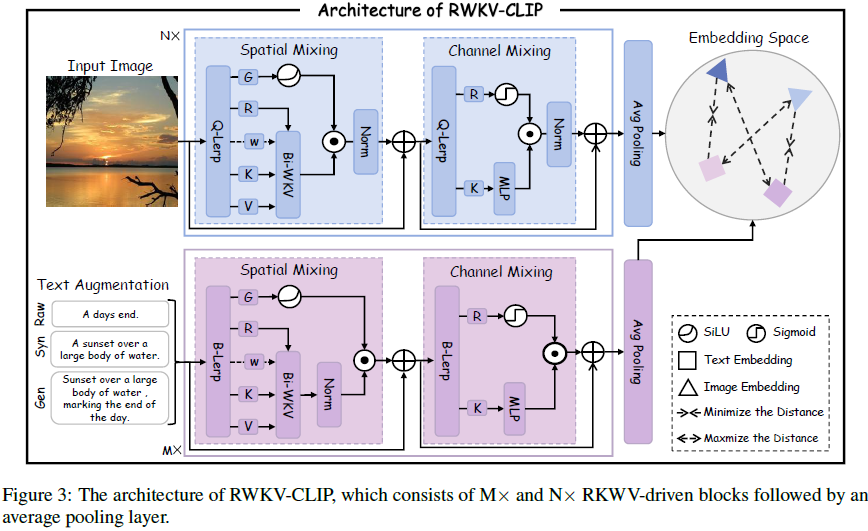
在本节中,我们提出了 RWKV-CLIP,这是一种稳健且高效的 RWKV 驱动的视觉语言表示学习模型。受 CLIP(Radford等人,2021年)和 Vision-RWKV(Duan等人,2024年)的启发,RWKV-CLIP 采用了双塔(dual-tower)架构,具有类似于 Transformer(Vaswani等人,2017年)的块堆叠编码器设计,每个块由一个空间混合模块和一个通道混合模块组成。我们提出的 RWKV-CLIP 的总体架构如图 3 所示。
输入增强。基于我们提出的多样化描述生成框架,我们可以获得三种类型的文本:原始文本 Tr、合成标题 Ts 和生成描述 Tg。为了提高模型的鲁棒性,我们随机从 [Tr, Ts, Tg] 中选择一个文本作为文本输入的增强:
![]()
与此同时,输入图像 I ∈ R^(H×W×3) 被转换为 HW / p^2 个补丁(patch),其中 p 是补丁大小。
空间混合。输入文本 aug(T) 和图像 I 被传递到空间混合模块,该模块作为一种注意机制,执行线性复杂度的全局注意力计算。具体来说,输入数据被移位并进入四个并行的线性层,以获得多头向量
![]()
![]()
其中,Lerp 是线性插值(Peng等人,2024年)。本文中,我们分别采用 Q-Lerp 和 B-Lerp 用于图像和文本编码器。Q-Lerp 可以表示为:
![]()
B-Lerp 可以表示为:
![]()
其中,Ψ ∈ {G,R,K,V,w},η_Ψ 表示可学习向量,I* 是图像中的四向移位向量(quad-directional shift vector),即 I1 = x[h−1, w, 0:C/4], I2 = x[h+1, w, C/4:C/2], I3 = x[h, w−1, C/2:3C/4], I4 = x[h, w+1, 3C/4:C],T* 是文本中的双向移位,即 T1 = [w−1, 0:C/2], T2 = [w+1, C/2:C],其中 h, w, C 分别表示高度、宽度和通道数。这些移位函数增强了特征在通道层级的交互,使得能够关注到相邻的标记(tokens)。具体来说,双向移位确保了文本标记的前向和后向交互,而不会增加额外的FLOPs。为了避免固定的学习向量,新的时变衰减 w_x 计算如下:
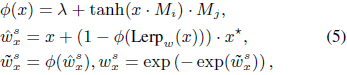
其中 x ∈ {I,T},λ 是一个可学习的向量,Mi 和 Mj 是可学习的权重矩阵。函数 ϕ 通过给输入添加额外偏移来低成本地获取学习向量。^w^s_x 和 ~w^s_x 是计算过程中的中间值。这个过程允许 wx 的每个通道根据当前和先前标记的混合值 x* 发生变化。
随后,
![]()
被用于通过线性复杂度的双向注意力机制计算全局注意力结果 wkv_t。这个结果然后乘以 σ(G^s_x),作为门机制来控制输出 O^s_x:
![]()
其中 σ(⋅) 表示 SiLU 函数(Elfwing 等人,2018年),⊙ 表示逐元素乘法,LN 是层归一化,Bi-WKV(Duan 等人,2024年;Peng 等人,2024年)可以表示为:
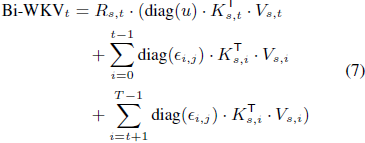
其中 u 是每个通道的学习增强,ϵ_(i,j) = ⊙^(i−1)_(j=1) wj 是一个动态衰减。
通道混合。空间混合模块后是通道混合模块。同样,R^c_x, K^c_x 是通过线性插值(Lerp)获得的:
![]()
之后,分别执行线性投影和门机制,最终输出 O^c_x 表示为:
![]()
其中 ρ 是平方 ReLU(Agarap, 2018)。通过堆栈 RWKV 的图像和文本编码器 EI 和 ET 后,我们可以得到图像嵌入 ^I=EI(I) 和文本嵌入 ^T=ET(aug(T)),损失函数 LLL 定义为:
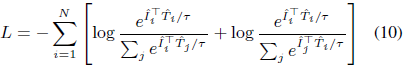
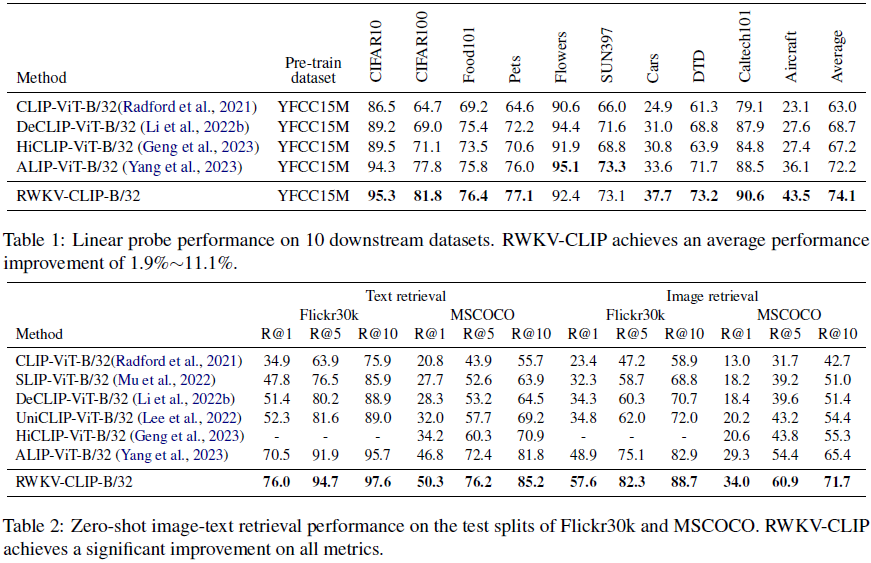
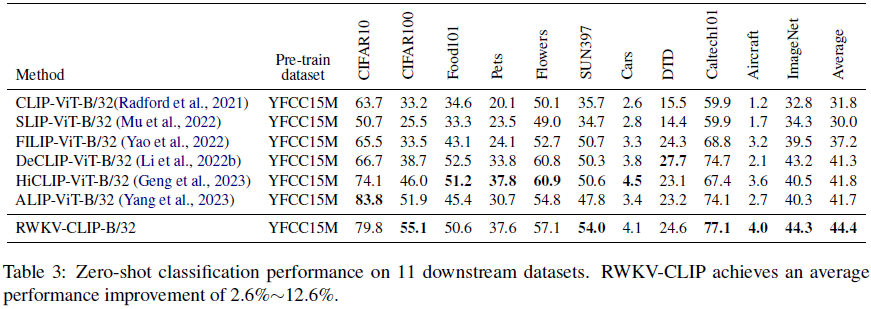
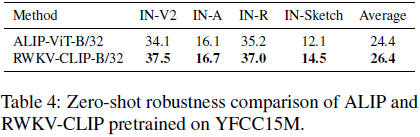
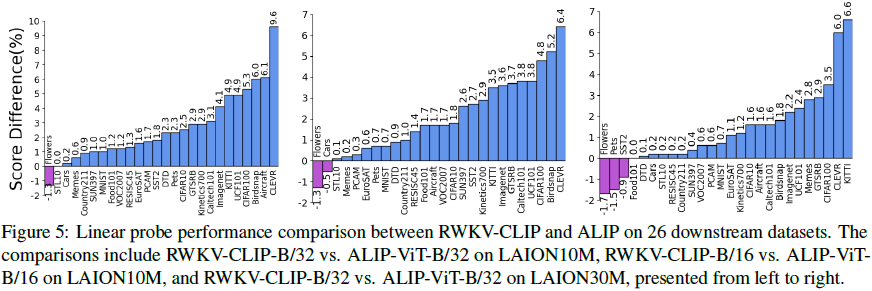
4. 实验

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









