






【前端】数据结构
1. 什么是数据结构?
数据结构是在计算机中组织和存储数据的一种特殊方式,使得数据可以高效地被访问和修改。更确切地说,数据结构是数据值的集合,表示数据之间的关系,也包括了作用在数据上的函数或操作。
1.1 八大常见的数据结构
- 数组:Array
- 堆栈:Stack
- 队列:Queue
- 链表:Linked Lists
- 树:Trees
- 图:Graphs
- 字典树:Trie
- 散列表(哈希表):Hash Tables
在复杂性方面:
- 堆栈和队列是最简单的,并且可以从中构建链表。
- 树和图 是最复杂的,因为它们扩展了链表的概念。
- 散列表和字典树需要利用这些数据结构来可靠地执行。
就效率而言:
- 链表是记录和存储数据的最佳选择
- 而哈希表和字典树在搜索和检索数据方面效果最佳。
2.数组
通常指将按序排列的同类数据元素的集合称为数组。一个数组可以分解为多个数组元素,这些数组元素可以是基本数据类型或是构造类型。
下面是前端常用的遍历数组的方法:
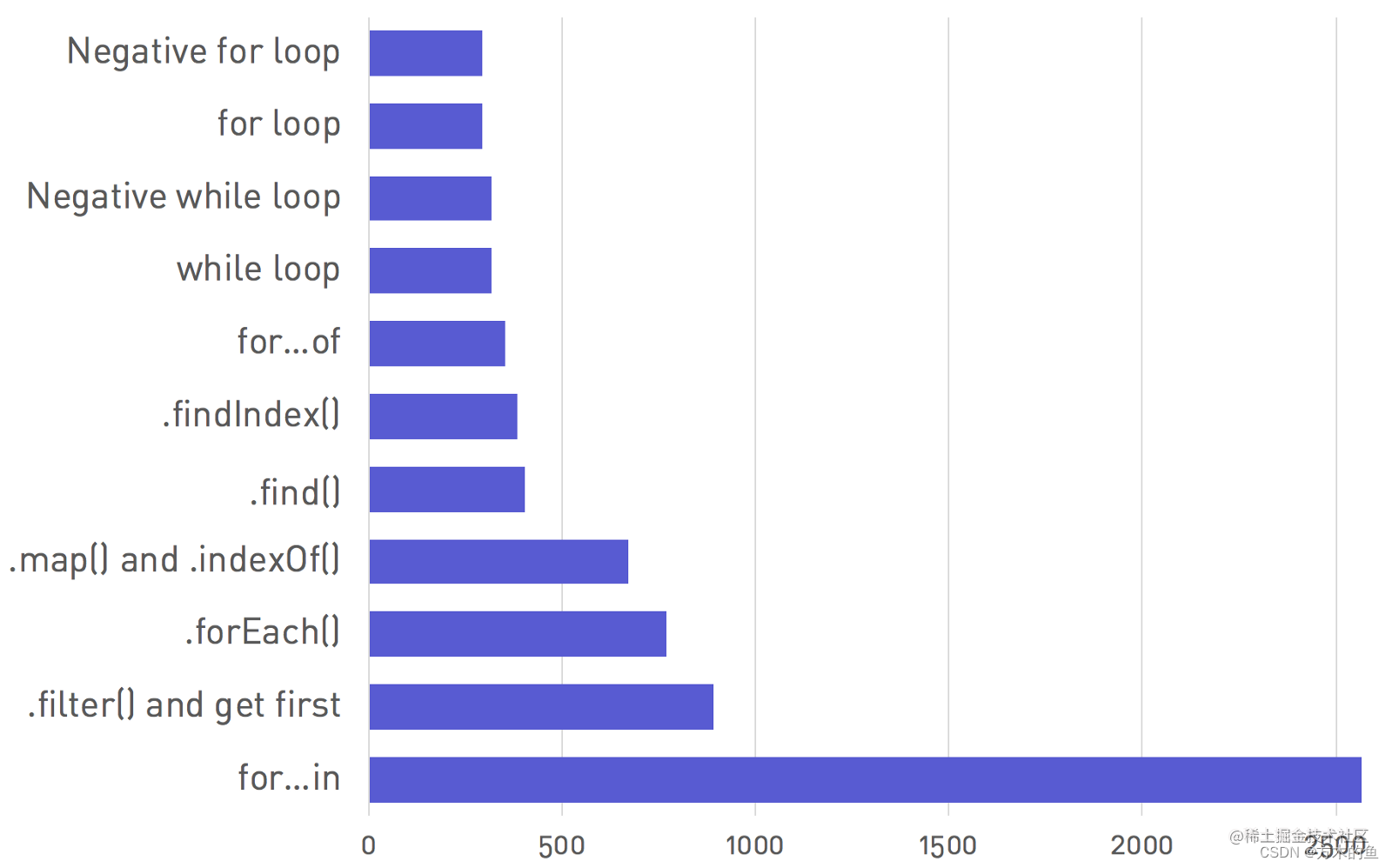
从图中我们可以看到for… in的运行效率最低。这是因为for … in语法是第一个能够迭代对象键的JavaScript语句。
3.栈(LIFO)
是指能在某一端插入和删除的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)

下面我们看一下代码是如何实现的:
function Stack() {
//用数组来存储元素
this.arr = [];
this.push = function (value) {
this.arr.push(value);
};
this.pop = function () {
return this.arr.pop();
};
}
var stack = new Stack();
stack.push(1);
stack.push(2);
stack.push(3);
console.log(stack.arr); // [ 1, 2, 3 ]
console.log(stack.pop()); // 3
console.log(stack.pop()); // 2
console.log(stack.pop()); // 1
4.队列(Queue)
一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列是按照**“先进先出”或“后进后出”**的原则组织数据的。队列中没有元素时,称为空队列。
在实现时,我们可以颠倒堆队列的顺序。于是分别使用数组unshift和shift方法代替push和pop。
shift() 函数是从数组中删除第一项,并返回该删除项。
unshift()函数是向数组的开头添加一个或更多元素,并返回新的长度。
下面我们看一下代码是如何实现的:
function Queue() {
this.arr = [];
this.push = function (value) {
this.arr.push(value);
};
this.pop = function () {
return this.arr.shift();
};
}
var queue = new Queue();
queue.push(1);
queue.push(2);
queue.push(3);
console.log(queue.arr); // [ 1, 2, 3 ]
console.log(queue.pop()); // 1
console.log(queue.pop()); // 2
console.log(queue.pop()); // 3
5.链表
是一种物理存储单元上非连续、非顺序的存储结构。主要是分为单链表和双链表。
5.1单链表
单链表的的节点只有两个域,一个是信息域,一个是指针域。信息域会保存当前节点的数据信息,而指针域保存着指向下个节点的地址,最末尾的节点的指针域指向null。

链表相对于数组的优点在于:
- 内存空间不是必须连续的,可以充分利用计算机的内存,实现灵活的内存动态管理。
- 链表不需要再创建的时候就确定大小,并且它的大小可以无限的延伸下去。
- 链表在插入和删除数据时,时间复杂度可以达到O(1),相对数组效率高许多。
链表相对于数组的缺点在于:
- 链表访问任何一个位置的元素时,都需要从头开始访问。
链表的常见操作:
- append(element):向列表尾部添加一个新的元素。
- insert(position, element):向列表的某个位置插入一个新的元素。
- get(position):获取对应位置的元素。
- indexOf(element):返回元素在列表中的索引。如果没有该元素则返回-1。
- update(position, data):修改某个位置的元素的data值。
- removeAt(position):从列表的某个位置移除一个元素 remove(data):从列表中移除一个元素。
- isEmpty():如果链表中没有元素,返回true。否则返回false。
- size():返回链表中包含的元素个数,和数组的length属性类似。
- toString():链表中元素是Node类,需要重写toString方法,方便输出打印元素的值。
下面我们来看一下单链表实现的增删改查操作的代码实现:
//初始化节点
class Node {
constructor(element) {
this.element = element
this.next = null
}
}
class linkedList {
constructor() {
this.size = 0
this.head = null
}
//添加节点
append(element) {
//创建节点
let node = new Node(element)
//添加第一个节点
if (this.head === null) {
this.head = node
} else {
//添加第n个节点
//获取链表的最后一个节点,使其next指向要添加的节点
let current = this.getNode(this.size - 1)
current.next = node
}
this.size++
}
//插入节点
appendAt(position, element) {
if (position < 0 || position > this.size) {
throw new Error('error')
}
//创建节点
let node = new Node(element)
//在第0个位置插入
if (position === 0) {
node.next = this.head
this.head = node
} else {//在第n个位置插入
let pre = this.getNode(position - 1)
node.next = pre.next
pre.next = node
}
this.size++
}
//删除节点
removeAt(position) {
if (position < 0 || position >= this.size) {
throw new Error('error')
}
let current = this.head
//删除第一个节点
if (position === 0) {
this.head=current.next
} else {//删除第n个节点
let pre = this.getNode(position - 1)
current=pre.next
pre.next=current.next
}
this.size--
}
//获取节点
getNode(index) {
if (index < 0 || index >= this.size) {
throw new Error('error');
}
let current = this.head
for (let i = 0; i < index; i++) {
//next到index所在元素
current = current.next
}
return current
}
//查找指定元素的索引
indexOf(element) {
let current=this.head
for (let i = 0; i < this.size; i++){
if (current.element === element) {
return i
}
current=current.next
}
}
// 打印链表全部元素
print() {
const list = []
let current = this.head
while(current){
list.push(current.element)
current = current.next
}
return list.join(' => ')
}
}
let linked = new linkedList()
linked.append(1)
linked.append(2)
linked.appendAt(0, 0)
console.log(linked.print()) // "0 => 1 => 2"
linked.appendAt(2, 3)
console.log(linked.indexOf(2)) // 3
console.log(linked.print()) // "0 => 1 => 3 => 2"
linked.removeAt(2)
console.log(linked.indexOf(2)) // 1
console.log(linked.print()) // "0 => 1 => 2"
5.2双链表
类似于单链表,双向链表由一系列节点组成。每个节点包含一些数据以及指向列表中下一个节点的指针和指向前一个节点的指针。

双链表的操作与单链表相似,但是由于多了一个指向上一个节点的指针,所以可以进行反向遍历、下面我们实现了一个反向的操作:
// 初始化节点
class Node {
constructor(element) {
this.element = element
this.prev = null
this.next = null
}
}
class linkedList {
constructor() {
this.head = null;
this.tail = null;
}
append( element) {
let node = new Node( element);
if(!this.head) {
this.head = node;
this.tail = node;
} else {
node.prev = this.tail;
this.tail.next = node;
this.tail = node
}
}
reverse(){
let current = this.head;
let prev = null;
while( current ){
let next = current.next
current.next = prev
current.prev = next
prev = current
current = next
}
this.tail = this.head
this.head = prev
}
print() {
const list = []
let current = this.head
while(current){
list.push(current.element)
current = current.next
}
return list.join(' => ')
}
}
let linked = new linkedList()
linked.append(0)
linked.append(1)
linked.append(2)
console.log(linked.print()) // "0 => 1 => 2"
linked.reverse()
console.log(linked.print()) // "2 => 1 => 0"
6.树
树是一种非线性的数据结构,并且是一种一对多的数据结构,其存储的所有元素之间具有明显的层次特性。
树的结构特点:
- 在树结构中,每一个结点只有一个父结点,若一个结点无父节点,则称为树的根结点,简称树的根(root)。
- 每一个结点可以有多个子结点。
- 没有子结点的结点称为叶子结点。
- 一个结点所拥有的子结点的个数称为该结点的度。 所有结点中最大的度称为树的度。树的最大层次称为树的深度。
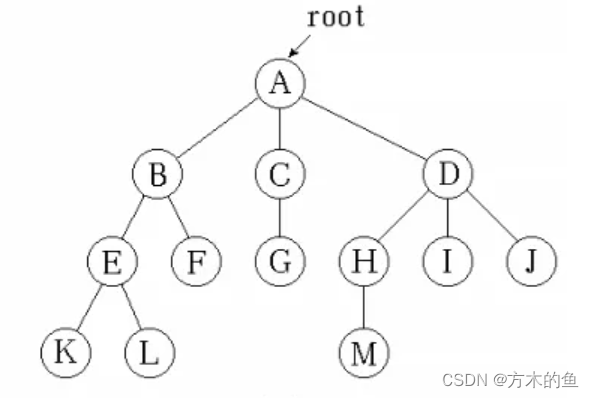
6.1DOM树
在前端的页面中,每个网页都有一个树数据结构(DOM树),如图:

从图中我们可以看到dom树有一个根节点标签,下面还生长着许多其他标签和文本内容。
DOM是 Document Object Model(文档对象模型)的缩写。当你的服务器把html网页发送给用户时,用户的浏览器会解析你的html代码,生成dom树。其作用就是为了让JavaScript可以对文档中的标签、属性、内容等进行增、删、改等操作。
举个例子:
常用的getElementById(),返回带有指定 ID 的元素。主要是可以更好的定位,正是有了dom对象,我们可以利用dom对象的方法,对dom树的内容进行修改
<!DOCTYPE html>
<html>
<head>
<script>
function myFunction() { document.getElementById("p1").innerHTML = "我喜欢吃";
}
</script>
</head>
<body>
<p id="p1">我喜欢吃鱼</p>
<button type="button" onclick="myFunction()">试一试</button>
</body>
</html>
同时树的种类有很多,比如二叉树、平衡二叉树(AVL)、哈夫曼树、红黑树。下面主要来讲一下二叉树。
6.2二叉树
顾名思义,二叉树是每个节点最多有两个子树的树结构(也就是度最多为2),子树称作“左子树”和“右子树”。
在进行二叉树的遍历时,有三种遍历方式,前序遍历、中序遍历和后序遍历。
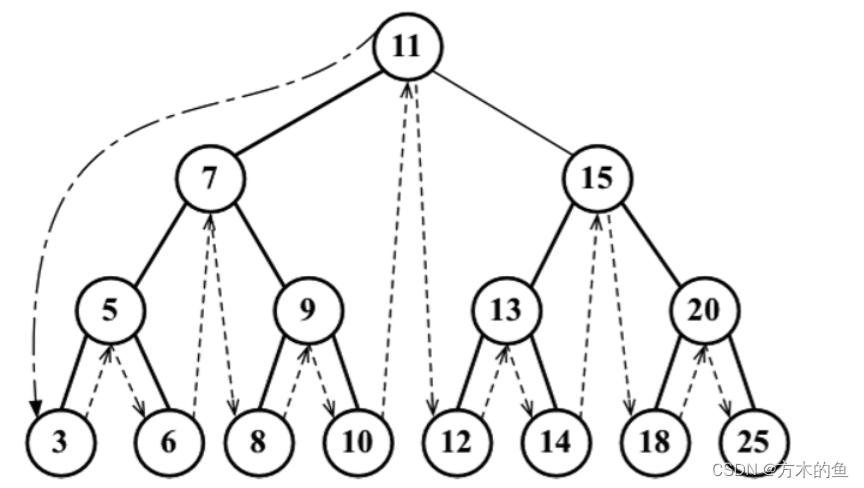
前序遍历:根节点->左子树->右子树
下图中遍历的结果应该是:11 7 5 3 6 9 8 10 15 13 12 14 20 18 25

中序遍历:左子树->根节点->右子树
下图中遍历的结果应该是:3 5 6 7 8 9 10 11 12 13 14 15 18 20 25
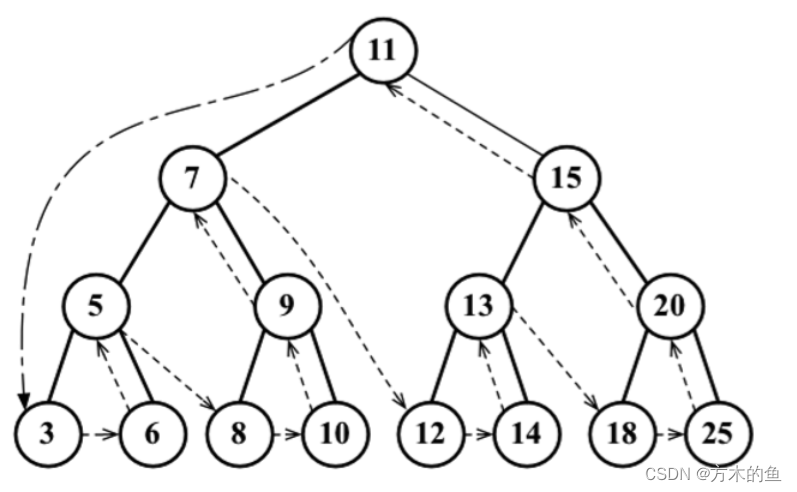
后序遍历:左子树->右子树->根节点
下图中遍历的结果应该是:3 6 5 8 10 9 7 12 14 13 18 25 20 15 11
7.图
6.图:是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
8.堆
7.堆:在计算机科学中,堆是一种特殊的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
9.哈希表
8.哈希表:若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个思想建立的表为散列表。















 14
14











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









