










前言
一个基础的数据分析项目,数据集非常简单,虽然有很多处理方法都用不上就可以做到一个比较好的效果(当然也可以进行一下骚操作,可以,但没必要),但是对于入门来说是非常适合的。
训练集及测试集数据获取链接:
链接:https://pan.baidu.com/s/1692cGZ7igopC3-Dka9_sMA
提取码:DJNB
数据字段说明
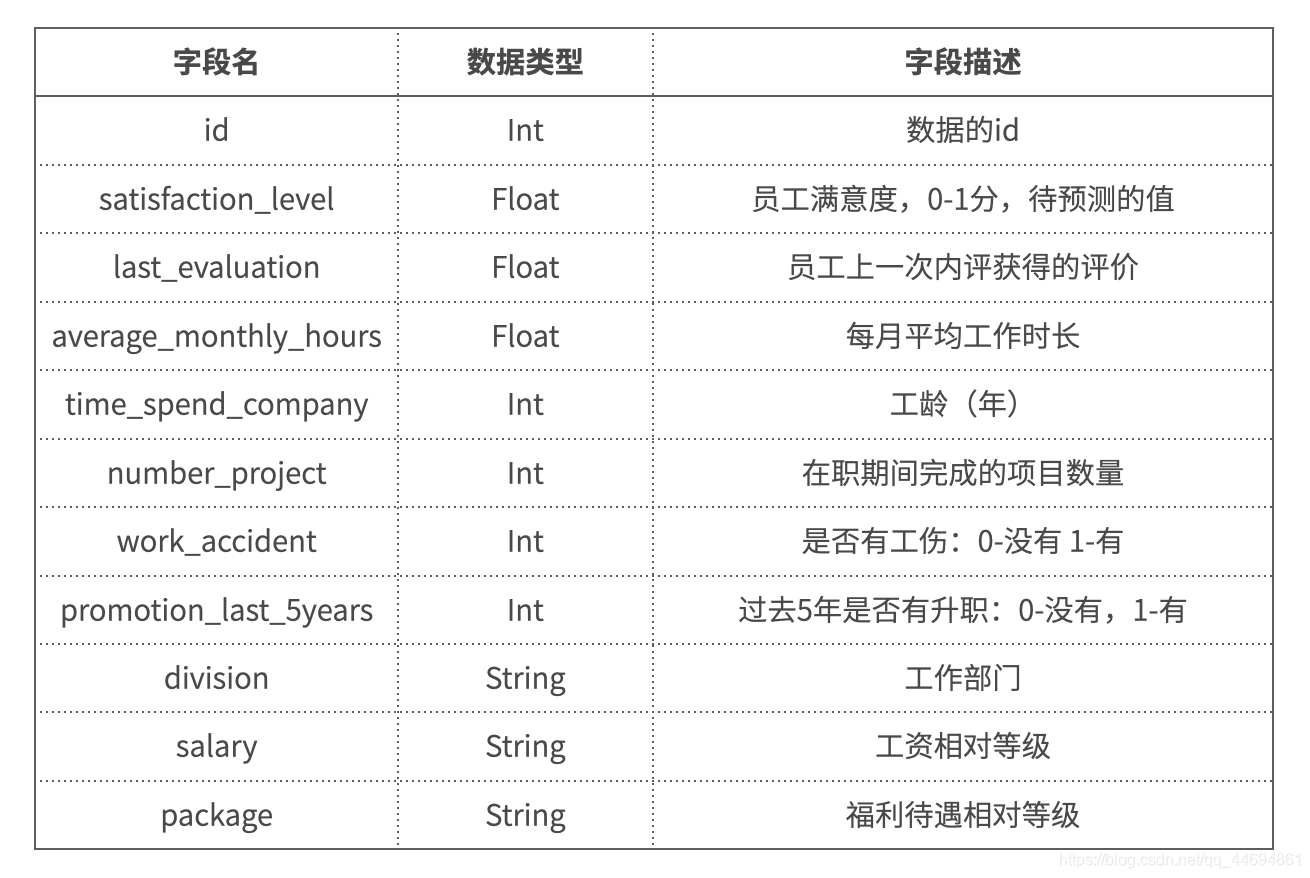
可以看到数据非常简单,并不复杂,并且数据类型也是标注清楚,对于类别变量和数值变量容易分辨,而表中satisfaction_level就是我们要预测的标签变量。
数据分布可视化
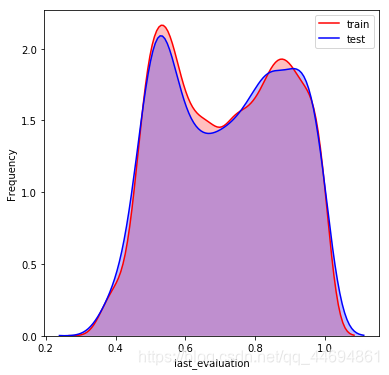
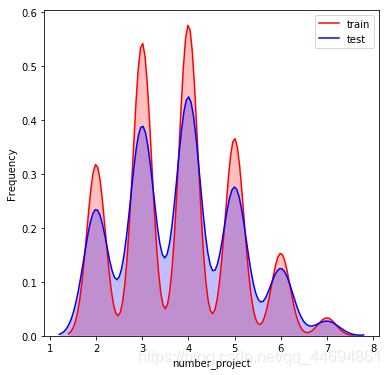
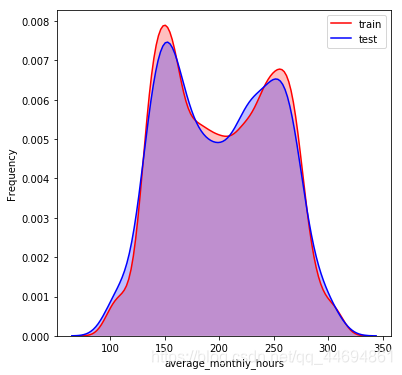
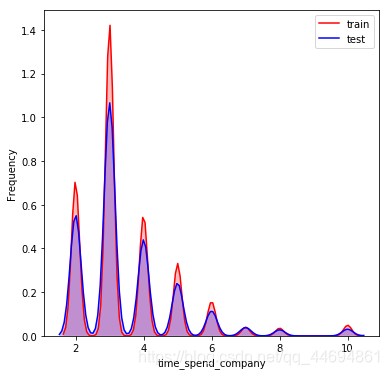
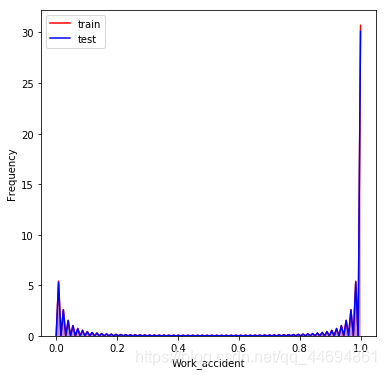
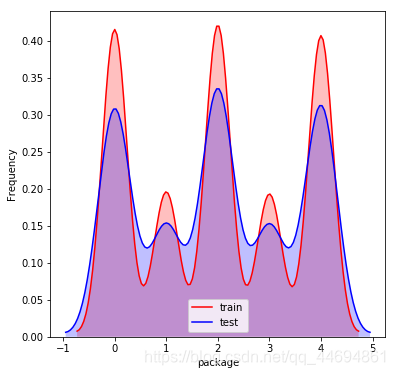
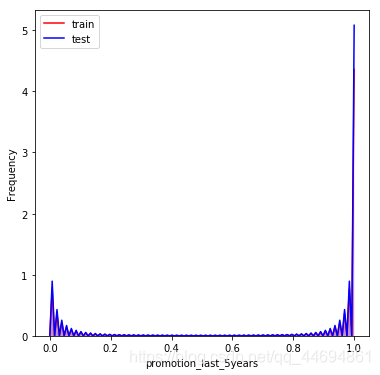
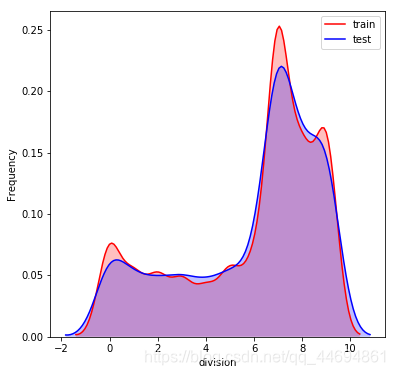
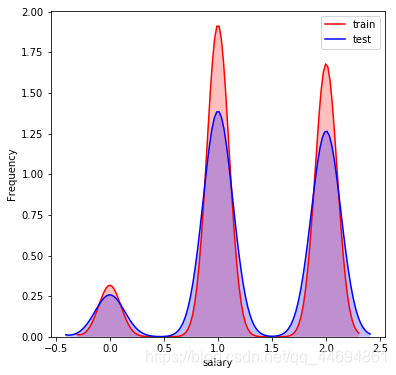
可以看到数据分布比较一致!
话不多说
baseline代码如下:
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import KFold
import numpy as np
import pandas as pd
#数据读入
train = pd.read_csv('训练集.csv')
test = pd.read_csv('测试集.csv')
#数据合并,便于操作
data=pd.concat([train,test])
#简单label编码
division = LabelEncoder()
package = LabelEncoder()
salary = LabelEncoder()
division.fit(data['division'].values)
data['division'] = division.transform(data['division'].values)
package.fit(data['package'].values)
data['package'] = package.transform(data['package'].values)
salary.fit(data['salary'].values)
data['salary'] = salary.transform(data['salary'].values)
#由于最开始选用xgboost(baseline是用的随机森林),所以先构建了简单的数值特征
cat_cols = ['division','salary','package','number_project']
for col in cat_cols:
t = data.groupby(col,as_index=False)['satisfaction_level'].agg(
{col+'_count':'count',col+'_sa_max':'max',col+'_sa_median':'median',
col+'_sa_min':'min',col+'_sa_sum':'sum',col+'_sa_std':'std',col+'_sa_mean':'mean'})
data = pd.merge(data,t,on=col,how='left')
#分离训练集和测试集数据
train=data[data['satisfaction_level'].notnull()]
test=data[data['satisfaction_level'].isnull()]
train=train.reset_index(drop=True)
test=test.reset_index(drop=True)
train_x = train.drop(['id','satisfaction_level'],axis=1)
target = train['satisfaction_level']
test_x = test.drop(['id','satisfaction_level'],axis=1)
#随机森林模型构建
rf = RandomForestRegressor(oob_score=True, random_state=0,
criterion='mse',
n_estimators= 300,max_depth=17)
answers = []
score = 0
n_fold = 20 #采用20折交叉验证
folds = KFold(n_splits=n_fold, shuffle=True,random_state=1314)
for fold_n, (train_index, valid_index) in enumerate(folds.split(train_x)):
X_train, X_valid = train_x.iloc[train_index], train_x.iloc[valid_index]
y_train, y_valid = target[train_index], target[valid_index]
rf.fit(X_train,y_train)
y_pre=rf.predict(X_valid)
score = score + mean_squared_error(y_valid,y_pre)
y_pred_valid = rf.predict(test_x)
answers.append(y_pred_valid)
rf_pre=sum(answers)/n_fold
print('rf验证分数'+str(score/n_fold))
#保存输出结果
result=pd.DataFrame()
result['id']=test['id']
result['satisfaction_level']=rf_pre
result.to_csv('result.csv',index=False)
上面的baseline是初步最简单的模型构建,线上测试MSE可以达到0.02942,没有进行任何数据变换的骚操作,也没有运用一些数学处理方法,只是简单构建基础特征,后续提高准确率的方法有很多,比如对数字特征进行数学变换,对类别数据进行尝试不同编码方式,或者尝试数据交叉构建新特征,还可以尝试不同模型融合,有奇效!
写在最后
本人才疏学浅,如果有错误或者理解不到位的地方请指正,同时有不懂的问题也可以提出!

















 3546
3546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









