







2、脚本解析
在看源码之前,我们一般会看相关脚本了解其初始化信息以及Bootstrap类,Spark也不例外,而Spark中相关的脚本如下:
%SPARK_HOME%/sbin/start-master.sh
%SPARK_HOME%/sbin/start-slaves.sh
%SPARK_HOME%/sbin/start-all.sh
%SPARK_HOME%/bin/spark-submit
启动脚本中对于公共处理部分进行抽取为独立的脚本,如下:
2.1start-daemon.sh
主要完成进程相关基本信息初始化,然后调用bin/spark-class进行守护进程启动,该脚本是创建端点的通用脚本,三端各自脚本都会调用spark-daemon.sh脚本启动各自进程
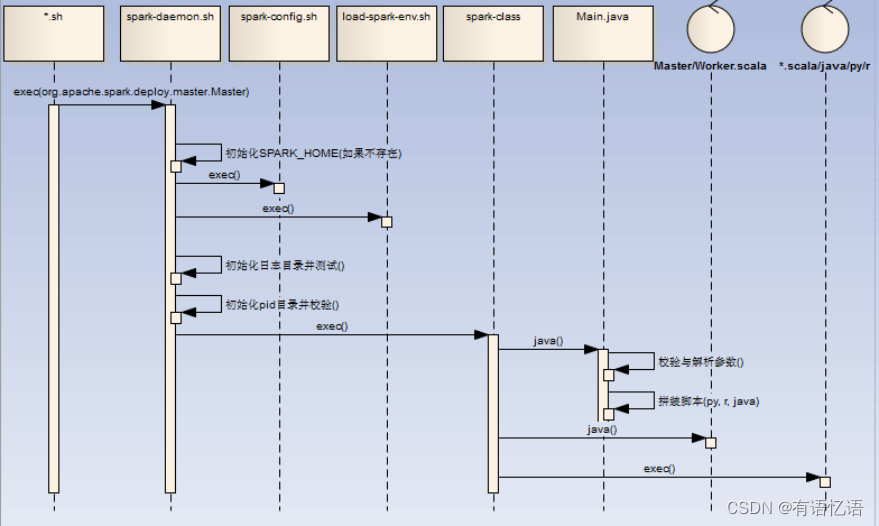
1)初始化 SPRK_HOME,SPARK_CONF_DIR,SPARK_IDENT_STRING,SPARK_LOG_DIR环境变量(如果不存在)
2)初始化日志并测试日志文件夹读写权限,初始化PID目录并校验PID信息
3)调用/bin/spark-class脚本,/bin/spark-class见下
2.2spark-class
Master调用举例:
bin/spark-class --class org.apache.spark.deploy.master.Master --host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT $ORIGINAL_ARGS
1)初始化 RUNNER(java),SPARK_JARS_DIR(%SPARK_HOME%/jars),LAUNCH_CLASSPATH信息
2)调用( “ R U N N E R " − X m x 128 m − c p " RUNNER" -Xmx128m -cp " RUNNER"−Xmx128m−cp"LAUNCH_CLASSPATH” org.apache.spark.launcher.Main “$@”)获取最终执行的shell语句
3)执行最终的shell语句(比如:/opt/jdk1.7.0_79/bin/java -cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/ -Xmx1g -XX:MaxPermSize=256m org.apache.spark.deploy.master.Master --host zqh --port 7077 --webui-port 8080),如果是Client,那么可能为r,或者python脚本
2.3start-master.sh
启动Master的脚本,流程如下:
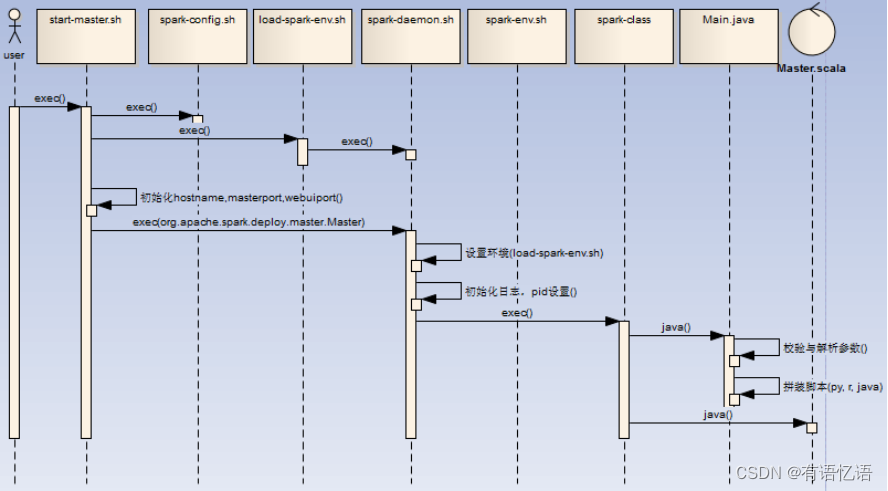
1)用户执行start-master.sh脚本,初始化环境变量SPARK_HOME (如果PATH不存在SPARK_HOME,初始化脚本的上级目录为SPARK_HOME),调用spark-config.sh,调用load-spark-env.sh
2)如果环境变量SPARK_MASTER_HOST, SPARK_MASTER_PORT,SPARK_MASTER_WEBUI_PORT不存在,进行初始化7077,hostname -f,8080
3)调用spark-daemon.sh脚本启动master进程(spark-daemon.sh start org.apache.spark.deploy.master.Master 1 --host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT $ORIGINAL_ARGS)
2.4start-slaves.sh
启动Worker的脚本,流程如下:
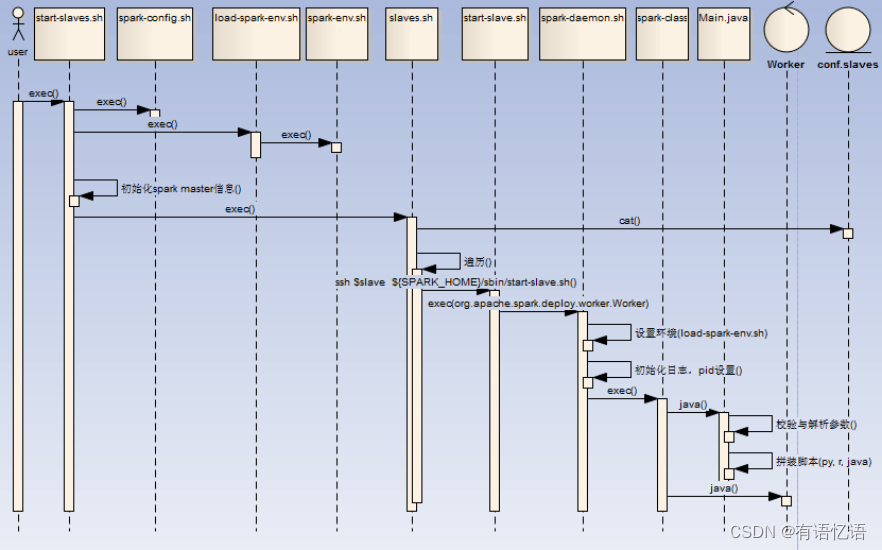
1)用户执行start-slaves.sh脚本,初始化环境变量SPARK_HOME,调用spark-config.sh,调用load-spark-env.sh,初始化Master host/port信息,
2)调用slaves.sh脚本,读取conf/slaves文件并遍历,通过ssh连接到对应slave节点,启动 S P A R K H O M E / s b i n / s t a r t − s l a v e . s h s p a r k : / / {SPARK_HOME}/sbin/start-slave.sh spark:// SPARKHOME/sbin/start−slave.shspark://SPARK_MASTER_HOST:$SPARK_MASTER_PORT
3)start-slave.sh在各个节点中,初始化环境变量SPARK_HOME,调用spark-config.sh,调用load-spark-env.sh,根 S P A R K W O R K E R I N S T A N C E S 计算 W E B U I P O R T 端口( w o r k e r 端口号依次递增)并启动 W o r k e r 进程( SPARK_WORKER_INSTANCES计算WEBUI_PORT端口(worker端口号依次递增 )并启动Worker进程( SPARKWORKERINSTANCES计算WEBUIPORT端口(worker端口号依次递增)并启动Worker进程({SPARK_HOME}/sbin /spark-daemon.sh start org.apache.spark.deploy.worker.Worker W O R K E R N U M − − w e b u i − p o r t " WORKER_NUM --webui-port " WORKERNUM−−webui−port"WEBUI_PORT" $PORT_FLAG $PORT_NUM M A S T E R " MASTER " MASTER"@")
2.5start-all.sh
属于快捷脚本,内部调用start-master.sh与start-slaves.sh脚本,并无额外工作
2.6spark-submit
任务提交的基本脚本,流程如下:
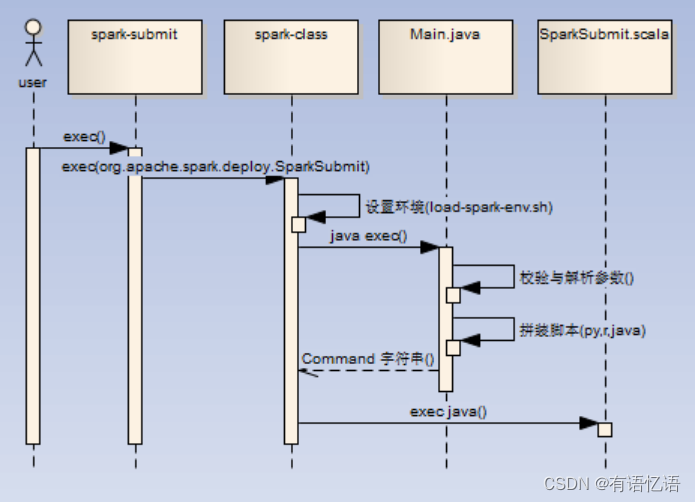
1)直接调用spark-class脚本进行进程创建(./spark-submit --class org.apache.spark.examples.SparkPi --master spark://master01:7077 …/examples/jars/spark-examples_2.11-2.1.0.jar 10)
2)如果是java/scala任务,那么最终调用SparkSubmit.scala进行任务处理(/opt/jdk1.7.0_79/bin/java -cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/ -Xmx1g -XX:MaxPermSize=256m org.apache.spark.deploy.SparkSubmit --master spark://zqh:7077 --class org.apache.spark.examples.SparkPi …/examples/jars/spark-examples_2.11-2.1.0.jar 10)















 1463
1463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











