







目录
1.处理字段名和属性名不一致的情况
这里注意一下:我们的表用的是下划线,而实体类用的是驼峰命名。

这时候通过mybatis查询,这个时候字段跟属性肯定是对应不上的。
我们之前都写过JDBC工具类,其实就是把查询出来的字段名,通过反射获取对应的属性名,然后来进行赋值。
但是这里属性名和字段名不一样,该怎么赋值?
这时候我们建一个查询环境
public interface EmpMapper {
/**
* 根据id查询员工信息
* @param empId
* @return
*/
Emp getEmpByEmpId(@Param("empId") Integer empId);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.godairo.mybatis.mapper.EmpMapper">
<!--Emp getEmpByEmpId(@Param("empId") Integer empId);-->
<select id="getEmpByEmpId" resultType="Emp">
select * from t_emp where emp_id = #{empId}
</select>
</mapper><?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--
Mybatis核心配置文件中的标签必须按照指定的顺序配置:
properties?,settings?,typeAliases?,typeHandlers?,
objectFactory?,objectWrapperFactory?,reflectorFactory?,
plugins?,environments?,databaseIdProvider?,mappers?)
-->
<properties resource="jdbc.properties"/>
<typeAliases>
<package name="com.godairo.mybatis.pojo"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!--引入mybatis的映射文件-->
<mappers>
<package name="com.godairo.mybatis.mapper"/>
</mappers>
</configuration>此时查询出来的应该是什么样的?
字段名跟属性名一致的话,那它们一定是相对应的,可以查出来,但是员工id,员工姓名,字段名和属性名不一致。
创建测试类
@Test
public void testGetEmpByEmpId(){
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
Emp emp = mapper.getEmpByEmpId(1);
System.out.println(emp);
}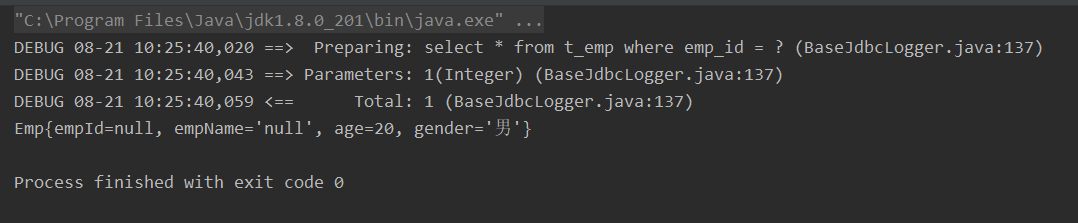 会发现empId和empName都是null,字段名和属性名不一致,没有创建映射关系。
会发现empId和empName都是null,字段名和属性名不一致,没有创建映射关系。
那么我们怎么创建这种映射关系?
方式1:去核心配置文件中,添加一个settings标签
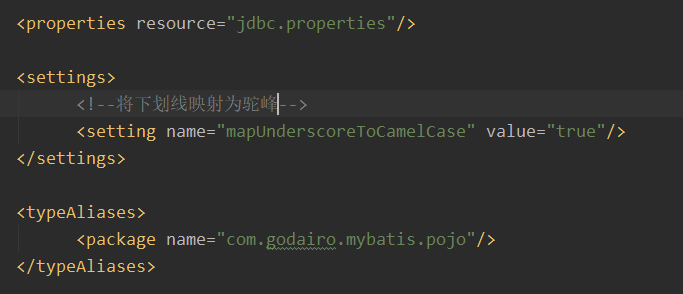
这是将下划线映射为驼峰,我们再来执行普通sql语句

 最后还是可以查询出来的。
最后还是可以查询出来的。
emp_id 映射为 empId
emp_name 映射为 empName
这里不是随便映射的,这是有规则的。
方式2:使用resultMap自定义映射处理
使用resultMap,这个需要我们自己去定义,resultMap里写的是我们配置resultMap的ID。
我们查询出来的字段,跟Emp类不一致,我们当前要解决的是id为getEmpByEmpId里的sql语句查询出来的字段跟Emp实体类中的映射关系。所以resultMap里的type就是Emp,那么需要resultMap处理映射字段跟属性的关系,里面的语句该怎么写?

这里面常用的标签有id,association,collection,result
id:处理主键和属性映射关系
result:处理普通字段和属性的映射关系
association:处理多对一
collection:处理一对多
我们写个id,看看里面都有什么
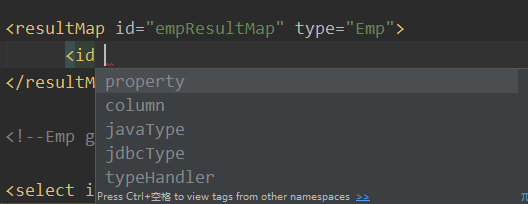
property:属性
colum:字段
javaType:属性的类型
jdbcType:字段类型
此时我们来写个colum:

这个就是把当前的emp_id字段和Emp实体类中的empId来进行映射。
以上是主键和属性的映射关系。
而其他的普通字段则是用result:

这就是一个自定义映射,此时我们来进行查询

<resultMap id="empResultMap" type="Emp">
<id column="emp_id" property="empId"></id>
<result column="emp_name" property="empName"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
</resultMap>
<select id="getEmpByEmpId" resultMap="empResultMap">
select * from t_emp where emp_id=#{empId}
</select>总结:
resultMap 里有两个属性,一个id一个type。
这个id自己根据规范进行命名,到时候需要由自己编写SQL语句的那个select里的resultMap进行使用。这个type是查询的数据要映射的实体类的类型
那么resultMap里面有子标签,这里先分析id标签和result标签
id标签:这是设置主键的映射关系,里面的colum属性是用来设置映射关系中表中的字段名,这里必须是sql查询出的某个字段。
而property属性是设置映射关系中的属性的属性名,这里必须是处理的实体类类型中的属性名
result标签:这是设置普通字段的映射关系,里面的colum属性和property属性和id标签里的colum属性和property属性所填写的内容是一样的性质。
2.多对一映射处理
表和表之间有关系,则它所映射的实体类也会有关系,比如说我们在表里面,可以通过一个字段,来表示当前员工所对应的部门id,那我们在实体类中,也要设置一个属性来表示员工所对应的部门信息。
表对应的是实体类,字段对应的是当前的属性,表里面的一条数据对应实体类对象。
那现在员工跟部门是多对一,也就是说一个员工对应一条部门信息,一个部门信息对应的则是一个部门对象。
那么我们来理一下实体类的关系:
在员工实体类中,员工对部门是多对一的关系。所以说一个员工对应一个部门对象。一个部门有多个员工。那么一个部门里需要一个员工集合。
以后对一,就是对应的一个对象,对多对应的是一个集合
那么员工的实体类则是:
public class Emp {
private Integer empId;
private String empName;
private Integer age;
private String gender;
private Dept dept;
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
public Integer getEmpId() {
return empId;
}
public void setEmpId(Integer empId) {
this.empId = empId;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public Emp(Integer empId, String empName, Integer age, String gender) {
this.empId = empId;
this.empName = empName;
this.age = age;
this.gender = gender;
}
public Emp() {
}
@Override
public String toString() {
return "Emp{" +
"empId=" + empId +
", empName='" + empName + '\'' +
", age=" + age +
", gender='" + gender + '\'' +
", dept=" + dept +
'}';
}
}那我们现在要查询员工信息,还要把员工所对应的部门信息也要查出来,用一个员工的实体类来表示当前员工的信息和员工所对应的部门。
我们现在通过一个SQL既要把员工查出来,还要把部门查出来,那就涉及到了多表连查
<!--Emp getEmpAndDeptByEmpId(@Param("empId") Integer empId);-->
<select id="getEmpAndDeptByEmpId" resultType="Emp">
select
*
from t_emp
left join t_dept
on t_emp.dept_id = t_dept.dept_id
where t_emp.emp_id=#{empId};
</select>现在我们SQL语句写完了,但是对应不上,我们查出来的是dept_id,dept_name,它们两个字段要是想去映射的话,那就是dept_id,dept_name这两个属性。
而我们当前让它映射的直接是Emp类型,此时在Emp实体类中只有Dept类型

2.1 使用association处理多对一的映射关系
association这个属性可以处理一对一,也可以处理多对一,它其实就是处理实体类类型的属性
<resultMap id="empAndDeptResultMap" type="Emp">
<id column="emp_id" property="empId"></id>
<result column="emp_name" property="empName"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
<association property="dept" javaType="Dept">
<id column="dept_id" property="deptId"></id>
<result column="dept_name" property="deptName"></result>
</association>
</resultMap>
<!--Emp getEmpAndDeptByEmpId(@Param("empId") Integer empId);-->
<select id="getEmpAndDeptByEmpId" resultMap="empAndDeptResultMap">
select
*
from t_emp
left join t_dept
on t_emp.dept_id = t_dept.dept_id
where t_emp.emp_id=#{empId};
</select>association:处理多对一的映射关系(处理实体类类型属性)
property:设置需要处理映射关系的属性的属性名
javaType:设置要处理的属性的类型

2.2 使用分布查询处理多对一的映射关系
所谓的分布查询,就是一步一步查,我们要查的是员工信息和员工的部门信息。
那可以把员工先查出来,查出来员工之后,再把员工对应的部门id作为条件,在部门表里来查询,这样就可以查询出来对应的部门
简单的说就是通过多个SQL语句,一步一步的把需要的数据查出来
我们使用分布查询一定要想清楚,当前查询应该分几步,每一步应该是什么?
比如说我们查员工以及员工所对应的部门,那第一步就需要查员工,查员工之后就知道员工所对应的部门id,那再把部门id作为条件,去部门表里查询部门信息,查询出来的结果再赋值给Emp里的Dept对象,就完事儿了
分步查询的第一步:
/**
* 通过分布查询,查询员工以及所对应的部门信息的第一步
* @param empId
* @return
*/
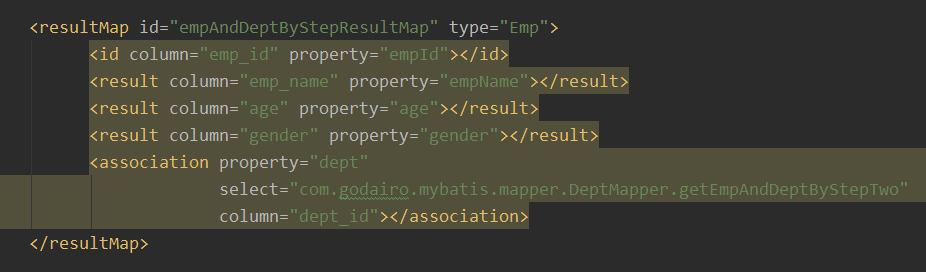
Emp getEmpAndDeptByStepOne(@Param("empId") Integer empId);<resultMap id="empAndDeptByStepResultMap" type="Emp">
<id column="emp_id" property="empId"></id>
<result column="emp_name" property="empName"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
<association property="dept"></association>
</resultMap>
<!--Emp getEmpAndDeptByStepOne(@Param("empId") Integer empId);-->
<select id="getEmpAndDeptByStepOne" resultMap="empAndDeptByStepResultMap">
select * from t_emp where emp_id = #{empId}
</select>这里我们来看association,我们现在需要把dept这个属性给查出来,那么我们怎么查呢?原来是通过两表联查,只要一个SQL查询出来的字段就能跟dept就行对应,也就是跟dept中的属性进行对应。
而现在分步查询,这个dept的属性需要从分步查询的第二步,也就是从另外一个SQL语句来的,所以说这里面需要用到的属性有select,还有一个是column。
现在来进行分布查询员工以及所对应的部门信息的第二步,创建DeptMapper接口和对应的Mapper文件。
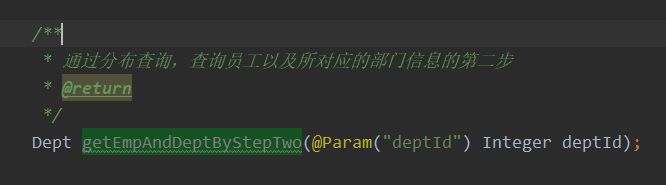
/**
* 通过分布查询,查询员工以及所对应的部门信息的第二步
* @return
*/
Dept getEmpAndDeptByStepTwo(@Param("deptId") Integer deptId);这里deptId传进去的是查出来员工信息所对应的部门id
<!--Dept getEmpAndDeptByStepTwo(@Param("deptId") Integer deptId);-->
<select id="getEmpAndDeptByStepTwo" resultType="Dept">
select * from t_dept where dept_id=#{deptId}
</select>这时候直接用resultType就行了,不用resultMap,我们在核心配置文件已经配置了settings标签,它会自动将下划线映射为驼峰
那么我们现在两个SQL语句写完了,写完了就需要关联起来。
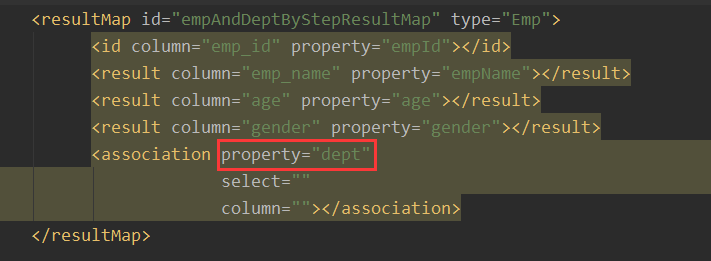
我们当前的dept属性的值需要从DeptMapper接口中的方法查询出来,再给当前的属性赋值,所以我们的select里面需要写的就是分布查询SQL的唯一标识,我们需要定位到id为getEmpAndDeptByStepTwo的SQL,把这个SQL查询出来的结果,赋值给dept属性。
这里的唯一标识就是:namesapce.sql的id,就是唯一标识。也就是说这个唯一标识就是DeptMapper接口的全类名+方法名。

直接对这个方法名Copy Reference就行。 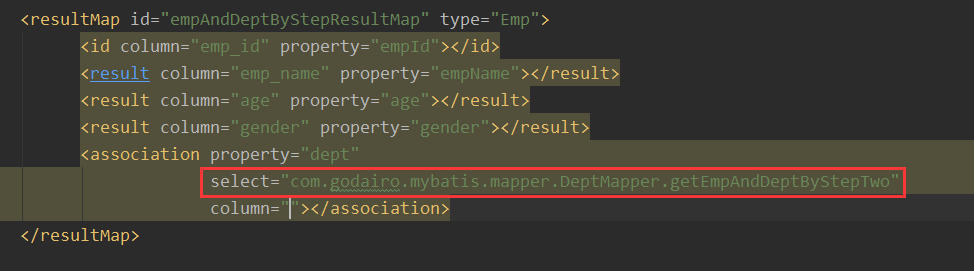
那么这个column又是什么呢?
我们可以看到,执行以下这个SQL的时候,它有条件,这个方法并不是我们自己在调,而是Mybatis在实现这个功能的时候,当我们需要去查询dept属性的时候,它会自动调用getEmpAndDeptByStepTwo这个方法,把这个方法的查询结果赋给dept属性。那这个条件的来向就是:执行完第一个SQL后,由第一个SQL传输到下一个SQL,所以colum写的是条件,来作为下一步SQL的条件的字段
也就是说我们第一个SQL可以查出来员工信息,其中有emp_id,emp_name,age,gender,dept_id;
而我们就是将这个查询出来的dept_id传出给下一个SQL语句查询的条件
接下来进行测试:
@Test
public void testGetEmpAndDeptByStep(){
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
Emp emp = mapper.getEmpAndDeptByStepOne(1);
System.out.println(emp);
}可以看到,执行的SQL语句有两条,先执行查询员工信息,然后根据查询出来的员工所对应的部门id,然后去查询部门信息。

association里的属性名:
property:设置需要处理映射关系的属性的属性名
select:设置分布查询的sql的唯一标识
colum:将查询出的某个字段作为分布查询的sql的条件
2.3 分布查询的优点
那么为什么要用分布查询呢?我用一条语句执行完不行吗?
分布查询是有优势的,优势就是可以实现延迟加载
但是必须在核心配置文件中设置全局配置信息:
lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载
aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载,此时就可以实现按需加载。获取的数据是什么,就只会执行相应的sql。
此时可通过association和collection中的fetchType属性设置当前的分步查询是否使用延迟加载, fetchType="lazy(延迟加载)|eager(立即加载)"
什么是延迟加载?
分布查询是通过两个SQL语句把数据查询出来。
如果这时候我们只需要获取员工信息,暂时不需要获取部门信息。
那么我们使用了分布查询,开启了延迟加载,获取员工信息只执行查询员工的SQL,如果没有执行获取部门信息,就不会去执行获取部门的SQL。这样就能减少内存消耗。
那么接下来在核心配置文件mybatis-config.xml中进行配置:
 那么我们此时去获取员工姓名,因为我们没有获取部门,所以就不会去加载获取部门信息的SQL语句
那么我们此时去获取员工姓名,因为我们没有获取部门,所以就不会去加载获取部门信息的SQL语句

可以看到只执行了一条员工的SQL语句。
此时我们需要了解lazyLoadingEnabled是和aggressiveLazyLoading一起使用的,aggressiveLazyLoading是按需加载,也就是说当我们在核心配置文件中设置了延迟加载之后,这个lazyLoadingEnabled的默认值是false,我们需要手动设置为true,此时aggressiveLazyLoading默认值是false,我们可以写出来看一看:
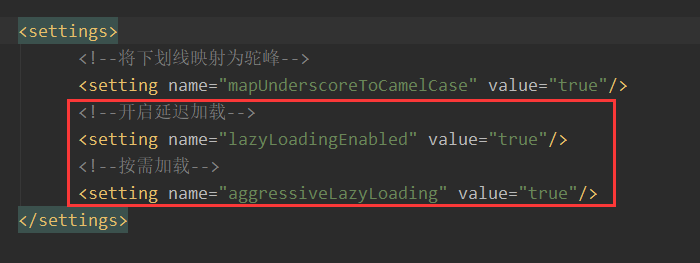
如果我们把按需加载设置为true,那么结果是这样的:

虽然查的只有员工姓名,但是部门的SQL也会执行。
所以我们需要把aggressiveLazyLoading设置为false

那么我们现在设置的这两个配置,是针对全局的,也就是说,不管在哪个Mapper文件中写的,最后执行,都会有这种效果。
由于这个是全局配置,所以是针对所有的分步查询,如果我们要想让某一个分布查询实现完整的加载,我们可以这样做:
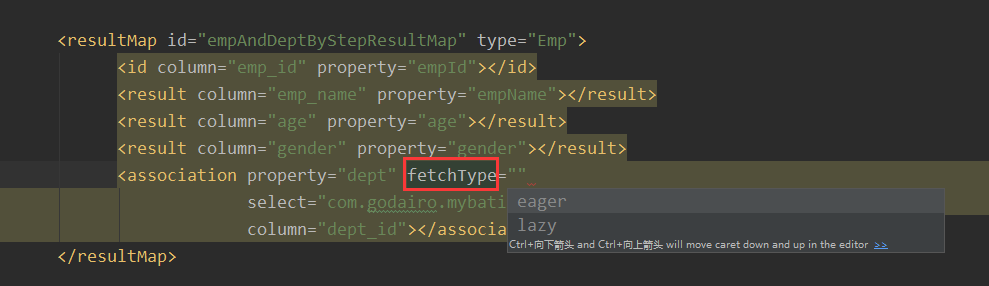
找到association标签,也就是实现分布查询的地方,这里面有个fetchType属性,这是将当前的分布查询设置为立即加载和延迟加载,lazy是延迟加载,eager是立即加载。
我们尝试一下设置为eager
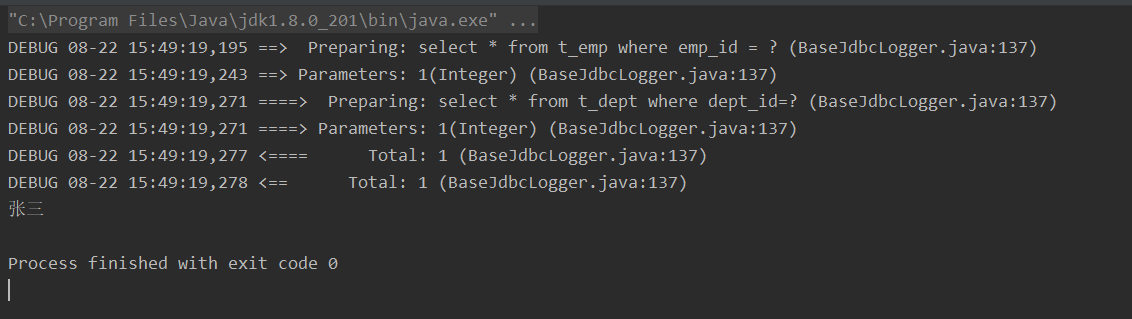
可以看到,将fetchType设置为eager的时候,虽然只查员工名,但是还是执行了部门SQL。
所以这个fetchType就是在我们开启了延迟加载的环境中,然后指定某个分步为延迟加载或立即加载。
3.一对多的映射处理
员工对部门是多对一,那部门对员工就是一对多。一个部门中对应多个员工信息。
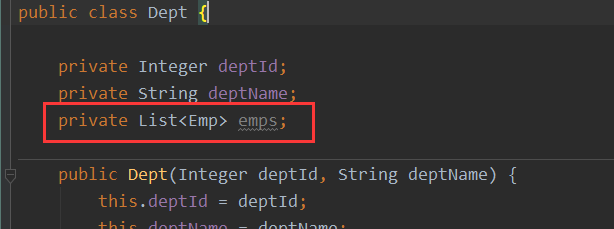
这里可以掌握一个规律:
在表关系映射到实体类中时,对一则是对应对象,对多就是对应集合。
需求:查询部门信息,并且把当前部门的所有员工查询出来。
3.1 通过collection处理一对多
用colleciton就是得用一个SQL,把当前的部门查出来,也要把部门中的员工查出来。我们用SQL查询一下

那么我们需要把部门的这些字段放在部门对应的实体类属性中,而员工字段则是先放在员工对象中,再放到我们所设置的集合属性里。
Dept getDeptAndEmpByDeptId(@Param("deptId") Integer deptId);<resultMap id="deptAndEmpResultMap" type="Dept">
<id column="dept_id" property="deptId"></id>
<result column="dept_name" property="deptName"></result>
<collection property="emps" ofType="Emp">
<id column="emp_id" property="empId"></id>
<result column="emp_name" property="empName"></result>
<result column="age" property="age"></result>
<result column="gender" property="gender"></result>
</collection>
</resultMap>
<!--Dept getDeptAndEmpByDeptId(@Param("deptId") Integer deptId);-->
<select id="getDeptAndEmpByDeptId" resultMap="deptAndEmpResultMap">
select * from t_dept as dept
left join t_emp as emp
on dept.dept_id=emp.dept_id
where dept.dept_id=#{deptId}
</select>collection:处理一对多的映射关系(处理集合类型的属性)
这里要注意:
association用的是javaType设置一个属性的类型
collection用的是ofType设置集合中的类型
然后我们进行测试:
@Test
public void testGetDeptAndEmpByDeptId(){
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
DeptMapper mapper = sqlSession.getMapper(DeptMapper.class);
Dept deptAndEmpByDeptId = mapper.getDeptAndEmpByDeptId(1);
System.out.println(deptAndEmpByDeptId);
}
3.2 通过分布查询处理一对多
现在我们查询的是部门信息,以及部门所对应的员工,用分布查询的话,就是先把部门查出来,然后再去查询部门中的员工信息。
先把部门信息查出来
/**
* 通过分布查询,查询部门以及部门中的员工信息--->第一步
* @param deptId
* @return
*/
Dept getDeptAndEmpByStepOne(@Param("deptId")Integer deptId);<resultMap id="deptAndEmpResultMapByStep" type="Dept">
<id column="dept_id" property="deptId"></id>
<result column="dept_name" property="deptName"></result>
<collection property="emps"
select="com.godairo.mybatis.mapper.EmpMapper.getDeptAndEmpByStepTwo"
column="dept_id"></collection>
</resultMap>
<!--Dept getDeptAndEmpByStepOne(@Param("deptId")Integer deptId);-->
<select id="getDeptAndEmpByStepOne" resultMap="deptAndEmpResultMapByStep">
select * from t_dept where dept_id=#{deptId}
</select>然后将查询出来的字段,将dept_id作为条件传给第二条要执行的SQL语句,也就是去员工那边查询部门为dept_id的员工信息
/**
* 通过分布查询,查询部门以及部门中的员工信息--->第二步
* @param deptId
* @return
*/
List<Emp> getDeptAndEmpByStepTwo(@Param("deptId") Integer deptId);这里要注意,我们通过dept_id查询出来的员工信息还是多个员工,所以要用List
<!--List<Emp> getDeptAndEmpByStepTwo(@Param("deptId") Integer deptId);-->
<select id="getDeptAndEmpByStepTwo" resultType="Emp">
select * from t_emp where dept_id=#{deptId}
</select>最后测试:
@Test
public void testgetDeptAndEmpByStep(){
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
DeptMapper mapper = sqlSession.getMapper(DeptMapper.class);
Dept deptAndEmpByStepOne = mapper.getDeptAndEmpByStepOne(1);
System.out.println(deptAndEmpByStepOne);
}
那么因为我们在核心配置文件中设置了延迟加载,这是针对全局的

所以我们测试一下只获取部门信息,这样就不会去加载员工信息。

同样可以在colletcion中设置立即加载
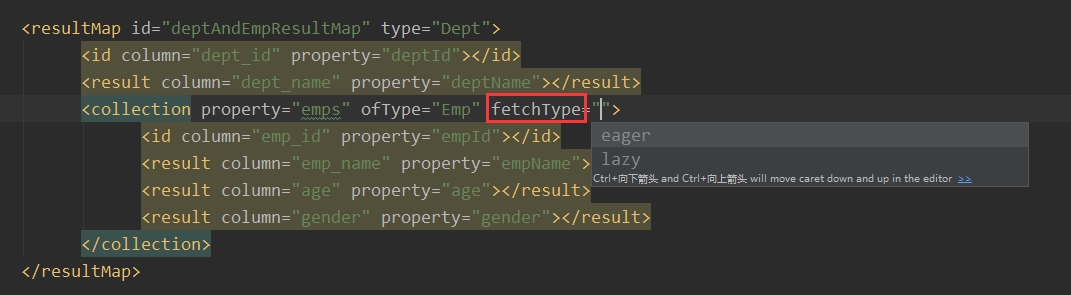 eager是立即加载,lazy是延迟加载。
eager是立即加载,lazy是延迟加载。
















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











