






1、Batch Normalization
我们在图像预处理过程中通常会对图像进行标准化处理,这样能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律)。而我们Batch Normalization的目的就是使我们的feature map满足均值为0,方差为1的分布规律。
关于具体计算请看链接
2、网络结构
下图是ResNet34的网络结构

ResNet提出residual结构(残差结构),并搭建超深的网络结构(突破1000层),并且使用Batch Normalization加速训练(丢弃dropout)。
下图左侧是网络结构为18、34层时的残差结构,右侧时50、101层的残差结构,残差结构能够减少网络参数与运算量。

对于左侧的残差结构(ResNet18/34)如下图所示,该残差结构的主分支是由两层3x3的卷积层组成,而残差结构右侧的连接线是shortcut分支也称捷径分支(注意为了让主分支上的输出矩阵能够与我们捷径分支上的输出矩阵进行相加,必须保证这两个输出特征矩阵有相同的shape)。在原论文中作者只是简单说了这些虚线残差结构有降维的作用,并在捷径分支上通过1x1的卷积核进行降维处理。在每层中的第一层卷积操作都会使用虚线结构的上采样,上采样之后和两次卷积之后的特征图相加在进行relu激活。

下图是50层以上的结构,具体操作是类似的。

下面这幅图是论文给出的不同深度的ResNet网络结构配置,表中的残差结构给出了主分支上卷积核的大小与卷积核个数,表中的xN表示将该残差结构重复N次。值得注意的是,conv2_x中,28/34层结构的第一层没有虚线下采样,因为净多3×3的max pooling得到的输入就是64channel,而经过两次卷积得到的也是64channel,相加不需要在改变channel数,50层以上在conv2_x所对应的一系列残差结构的第一层也是虚线残差结构,因为输入时64channel,但是经过卷积可以看出第三层是256channel,所以需要提升维度,但是不需要调整长宽的大小。而conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层虚线残差结构不仅要调整channel为4倍,还要将高和宽缩减为原来的一半。

3、代码学习
这里主要介绍model.py的内容,下面代码中有部分实现ResNext网络的操作,关于group的关键词可以忽略。
这里的BasicBlock主要实现ResNet18/34 进行conv2、3、4、5时的残差结构,进行卷积,bn、relu操作。expansion=1,表示每个残差结构中,经过卷积得到的channel数不变,直接乘以1,downsample为none表示不需要进行下采样,downsample不为none的时候,就需要返回该_make_layer函数中进行采样的sequential语句,进行升维以及改变长宽的操作。 至于输入输出channel,步距等都是设置好的。
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
expansion=4表示在残差结构中,每一层的几次卷积之后,最后的channel数都会变成初始输入的4倍,BasicBlock模块包含2个卷积层(3x3,3x3),而BottleNeck模块包含3个卷积层(1x1, 3x3, 1x1)
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
接着定义ResNet,这里的layer1,layer2,layer3 ,layer4 对应表格中的conv2_x,conv3_x,conv4_x,conv5_x,make_layer函数在下一部分代码介绍。
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
这个函数主要实现对残差结构的定义,参数block表示两种类型:BasicBlock、Bottleneck,block_num表示在该残差结构中有几层网络,stride默认为1,首先在if判断语句中判断是否是50层以上的网络,因为该类网络第一层网络中就需要升维,但是不需要改变长宽,主要看输入的channel和输出的channel是否是4倍的关系。如果是的话,就需要进行一个虚线结构的升维,;如果不需要进行长宽不变的升维操作,就会跳过if操作,接着进入append函数,表示进行每个conv中第一个残差结构的操作,这里根据输入类型调用BasicBlock或者Bottleneck网络;downsample用于进行下采样的操作。这样每个conv中的第一个残差结构就结束了,还要继续添加剩余的残差结构,这里的channel需要根据expansion的不同进行调整;接着从1-block_num进行循环添加,因为剩余的结构不需要虚线操作(不需要调整输入特矩阵的长宽为原来的一半,也不需要将channel调整为下一层需要的2倍)所以可以循环直接添加。
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
定义了ResNet网络正向传播过程,经过残差结构后,进行average pooling,然后进行展平,进行全连接操作,得到所分类别数量个输出,在进行softmax操作。
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
训练和测试的内容修改变化不大,图片以及代码来源于该视频
3、IBN-Net
论文探索了IN和BN的优劣,据此提出的IBN-Net在语义分割的域适应任务上取得了十分显著的性能提升。
BN提高特征对图像内容的敏感度,降低对风格类变化的鲁棒性
IN(Instance Normalization)提高对风格类变化的鲁棒性
底层层特征和风格类相关,高层和高层次特征相关(人脸,姿态等内容类特征)
IBN-Net出发点是:提升模型对图像外观变化的适应性。在训练数据和测试数据有较大的外观差异的时候,模型的性能会显著下降,这就是不同域之间的gap。比如训练数据中的目标光线强烈,测试数据中的目标光线昏暗,这样一般效果都不是很好。主要为了提高泛化能力。
IN用于处理底层视觉任务,比如图像风格化,而BN用于处理高层视觉任务,比如目标检测,图像识别等。IBN-Net首次将BN和IN集成起来,同时提高了模型的学习能力和泛化能力。:在网络的浅层同时使用IN和BN,在网络的深层仅仅使用BN

由上图可以看出,随着网络深度的增加,不同数据集图片的特征差异越来越小,而不同类别的图片的特征差异越来越大,这一差异表明低层的特征表示更多反映的是外观信息,而高层的特征表示更多反映的是语义信息。
作者提出了IBN-Net的两条基本构建原则:1、为了防止网络在高层的语义判别性被破坏,IN只加在网络低层中;2、为了保留低层中的语义信息,网络低层中也保留BN。根据这两条原则,作者提出了如下两个IBN block:
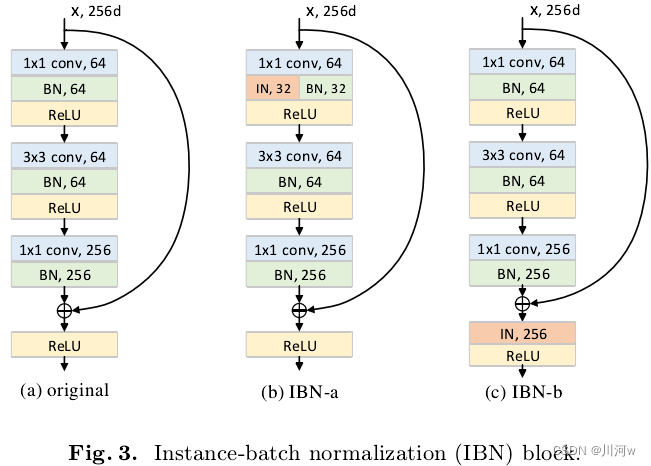
IBN-a适用于当前域和目标域一致的问题,比如说提升ResNet50的分类能力,可以用IBN-a,并且IBN-a微调以后结果是比原模型结果更好的。
IBN-b适合使用在当前域和目标域不一致的问题,比如说在行人重识别中,训练数据是在白天收集的,但是想在黄昏的时候使用的时候。这也是为何IBN-Net在行人重识别领域用的非常多的原因。
IBN-Net应用于ResNet等模型提高了泛化能力,在语义分割问题上对模型带来的提升效果更大。















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









