







对线面试官数据结构之HashMap
又到了熟悉的毕业季,室友在宿舍里准备进行线上面试,我躺在床上刷视频。
虽然刷视频很爽,但是以后面试要是被问到类似的问题要是全不会,那不是很尴尬?
先从他的面试里积累点经验,万一以后用得到。有道是: 思则有备,有备无患。

面试开始,面试官先问了一些基础的Java语法,然后就是数据结构的折磨。

面试官:数据结构熟悉吗?你一般都用哪些数据结构?
室友:还可以吧,我们有专门的课程。以前做的项目有用过ArrayList、LinkedList、ArrayDeque还有HashMap、HashTable、HashSet什么的。
我内心:

我只用过ArrayList,赶紧听一下,以后面试估计也用得着。
HashMap底层基本结构
面试官:嗯。看来你对数据结构挺熟悉的。对HashMap的底层熟吗?
室友: 还可以吧,平时会看一下用到的知识的源码。
我内心:当初我问你在电脑前干嘛,你可不是这么说的。

面试官:平时还看源码?不错。能说说HashMap大致的组成吗?
室友:组成的话,大概是一个数组+链表。
面试官(眉头一挑):就这样?还有吗?
我:错了,错了!他错了!

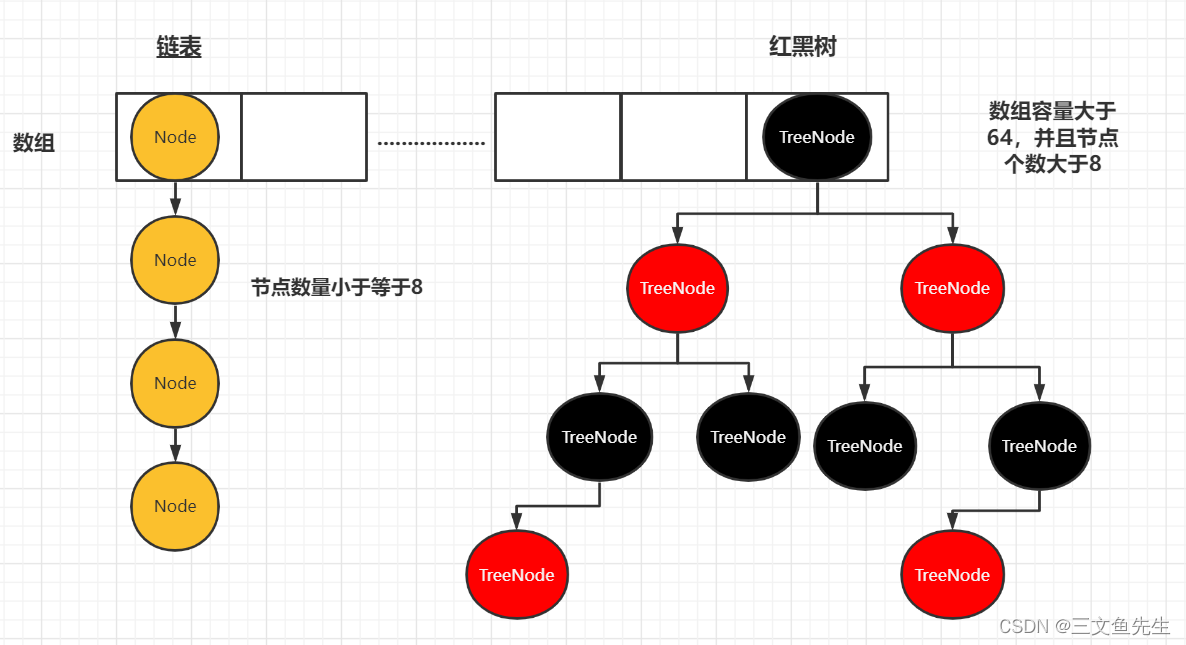
室友(摸下巴):还有?。。。嗷,记起来了。还有可能是数组+红黑树。HashMap里面有树化的操作,当链表存储的节点数量小于等于8时,是以链表形式存储,存储数据后的节点数大于8时,链表就树化为红黑树。
比较有意思的是TreeNode所继承的LinkedHashMap.Entry,其实是HashMap.Node的子类,也就是说TreeNode是Node的孙子。
所以Node数组也可以代表TreeNode。
//数组
transient Node<K,V>[] table;
//节点--链表
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//........
}
//节点--红黑树
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
//........
}
红黑树转为链表
面试官:你刚刚说了链表转为红黑树,那什么时候红黑树转为链表呢?
室友:好像是移除节点后的数量为6个的时候,就会退化成链表了。
面试官: 嗯,不错。但树化那一块说的有一点不对,就是当你链表的节点数大于8,但是你的数组容量小于64的时候,也不会树化,而是扩容。
室友:嗯嗯。
我: 可恶,被他装到了。先掏出小本本记下来,晚上偷偷看。卷死其他室友。
懒扩容及初始化容量
面试官:那我们继续,HashMap的懒扩容知道吗?
我:懒扩容?睡懒觉我倒是知道,扩容弹夹我也知道,懒扩容是睡懒觉的扩容弹夹?

室友:懒扩容就是每次扩容的时候,新的容量大小是原来的两倍。比如,默认的初始容量是16,到了要扩容的时候,我新的容量大小就是32了,而不是17或者18什么的。扩容在源码里面是通过移位实现的。
源码里的注释还提到,HashMap的容量大小必须是2的整数次幂,例如你定义的容量为6,那么在HashMap内部其实会给你变成8。
容量扩容主要代码
newCap = oldCap << 1; // 左移一位 变成两倍
取大于等于输入容量,最小的二次幂的整数
/**
* 给目标容量返回一个2的整数次幂
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
扩容时机
面试官: 嗯,那你知道什么时候扩容吗?
室友:扩容的话,在HashMap里面有一个属性叫loadFactor,有人数叫负载因子,也有人叫负载系数。其实都是同一个意思,默认大小是0.75。比如当前数组容量大小为100,那么存储到76个元素(大于100*0.75)的时候触发扩容条件。
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
我:。。。没听懂,先记着晚点再看。

扩容的大致步骤
面试官:能简单讲讲扩容的步骤吗?
室友:在1.7中,先是创建一个原容量两倍的数组,然后再重新计算节点在新的数组中的位置。因为在HashMap中是这么计算节点的下标的:index = HashCode(Key) & (Length - 1)。当容量length改变,那么index也会随之变化,以此来使得整体的节点均匀分布。
相对于后一步,在1.8里面就更加简单了,index = hash & oldCap。
//计算下标
static int indexFor(int h, int length) {
// h 为key 的 hash值;length 是数组长度
return h & (length-1);
}
面试官:你说用与(&)运算计算下标,那为什么不用取余呢?
室友:因为&运算是二进制运算,效率比取余更高。感觉这也是将容量设计为2的整数次幂的一个好处吧。,通过&运算就可以得到下标,而不需要使用取余。
我:计组乱入。。。当初考试的时候,还是老师让我过的。。。

HashMap1.7于1.8的区别
面试官:你刚刚说到了1.7和1.8里面HashMap的不同,能简单讲讲大概的不同点吗?
我内心:。。。1.8比1.7高了一个版本。。。

室友:大概是以下几点:
1、插入方式不同。1.7使用头插法,1.8换成了尾插法来防止扩容时造成死循环。
2、插入时的操作顺序不同。1.7先判断是否扩容,再插入元素,1.8先进行插入元素,插入后再判断是否需要扩容。
3、结构不同。1.7的结构只是数组+链表,而1.8的结构是数组+链表或者红黑树,降低了链表过长时,查找的时间复杂度。
4、扩容后计算下标不同。1.7是通过再hash,再计算进而得到下标,而1.8是直接用原hash&旧容量得到下标。
线程安全及与HashTable、HashSet的区别
面试官:嗯,不错。那HashMap是线程安全的吗?
室友:线程不安全,因为其中的方法都没有加synchronized修饰。
面试官:前面你提到了HashTable、HashSet,可以说说HashTable、HashSet和HashMap的大致区别吗?
室友:HashTable所有的方法都用synchronized修饰,所以是线程安全的,而HashMap没有用该关键字修饰,所以是线程不安全的,但也正因为如此才导致HashTable效率不高。
HashSet的话,它是基于HashMap实现的,但区别在于HashSet中只能存储唯一的值。比如,你存储一个Object对象,在ArrayList中可以用add方法,添加两个,读取的时候也能读取到两个,但在HashSet中,你add两次,但只能读取到一个。这是因为HashSet中add的对象对应的是HashMap中的键,所以是唯一的。
我:。。。可以问点我会的吗。。。

面试官:说的挺清楚的,你刚刚说HashMap不是线程安全的,那有没有线程安全,效率又比较高的?
室友:有的,比如ConcurrentHashMap,其实现原理是降低了锁的的粒度。
我:。。。没听说过。。。

算了 我不装了 我摊牌了

面试官:不错,今天的面试就到这里,等人事部的人通知吧。
室友:好的,拜拜。
我:好的,再见!

参考资料
10分钟拿下 HashMap
面试阿里,HashMap 这一篇就够了
阿里面试官没想到一个HashMap,我能跟他扯半小时
一个HashMap跟面试官扯了半个小时
















 2277
2277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









