







前面已经了解过,爬虫具有两大难点:一是数据的获取,二是采集的速度,因为会有很多的反爬(js)措施,导致爬虫并没有想象中那么容易。在python中,我们使用requests库作为核心,谷歌浏览器的检查工具作为辅助,学习如何编写爬虫。既然我们爬取的对象是网页,那自然少不了对网页的解析这一个关键阶段。所以我们接下来将学习解析网页的python库。
BeautifulSoup
BeautifulSoup是一个可以从HTML或XML文件中提取数据的python库,它的使用方式相对于正则来说更加的简单方便,常常能够节省我们大量的时间。注意:BeautifulSoup类对html文档获取元素的方式能够让我们联想到JS,所以在这里我建议对BeautifulSoup和JS进行相辅相成的学习(复习)。
安装方式:pip install beautifulsoup4
另外也可以附加使用ipython这个终端模块帮助我们进行学习,
安装方式:pip install ipython
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,"解析器名称")
#也可以缺省第二个参数,但会产生警告,不过python解释器会自动帮你添加
#目前最好的解析器lxml
在bs4这个模块中导入BeautifulSoup这个类,用这个类初始化一个带有解析器的对象,BeautifulSoup解析网页需要指定一个可用的解析器,以下是几种主要的解析器:
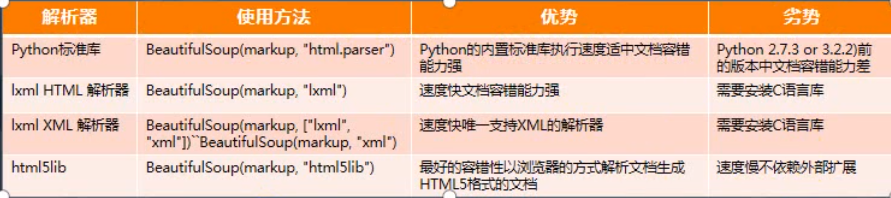
由于这个解析的过程在大规模的爬取中是会影响到整个爬虫系统的速度的,所以推荐使用的是lxml,速度会快很多,而lxml需要单独安装:pip install lxml
然后在你的脚本中实例化一个对象
soup = BeautifulSoup(html_doc,'lxml') #指定解析器
需要注意的是:如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的,所以要指定某一个解析器。
BeautifulSoup的四种节点对象
Tag
tag对象可以说是BeautifulSoup中最为重要的对象,通过BeautifulSoup来提取数据基本都围绕着这个对象进行操作。
tag的两个属性一个方法:name属性,Attributes属性,get_text()方法
from bs4 import BeautifulSoup
html_doc='''
<!DOCTYPE html>
<ht 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5789
5789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









