







本文以Java19预览特性虚拟线程为引子,介绍了协程的概念,实现方案,同时本地测试了Java异步回调和协程的性能对比
1.虚拟线程是什么
历史发展
很多抽象概念的诞生都是为了解决某些问题的。我们可以从历史发展背景中更清晰的理解这个抽象概念的作用。
进程:一开始的操作系统是单任务的,也就是一次只能将一个程序加载入内存执行。后面电脑功能多了,我们要求同时刻能运行多个任务,就有了并发的概念。从程序员的角度看就是可以同时执行多个逻辑流,内部无论是多cpu并行,还是单cpu时间分片都没问题。我们就将这抽象的逻辑流视为一个进程。搭配上虚拟内存的概念,可以做到不同进程之间互不干扰。
线程:计算机主要利用的资源有两个,cpu计算,I/O等待。当进程在等待IO准备好的时候,cpu是不怎么工作的,为了充分利用cpu,操作系统就将cpu给其他进程使用。这样做本来是没有什么问题,但是进程切换的成本太高了,需要反复进入内核,还需要切换页表,刷新TLB等等。为了提高速度,后面就抽象出了线程的概念,多个线程共享进程的内存空间,就不需要刷页表和TLB了,只需要刷新一遍寄存器。
协程(用户态线程/虚拟线程):互联网发展太快了,对系统高并发,吞吐量的要求越来越高,我们连线程切换都觉得太慢了,要是不需要内核用户态切换就好了。于是就有了用户态线程,也就是协程的概念。它不需要进入内核,不需要操作系统来管理,它的阻塞和唤醒都是在用户态下完成的
由此可以看出,协程能够进一步提高系统并发度和吞吐量。
Java线程模型
我们目前使用广泛的Java线程是和系统内核线程一一对应。
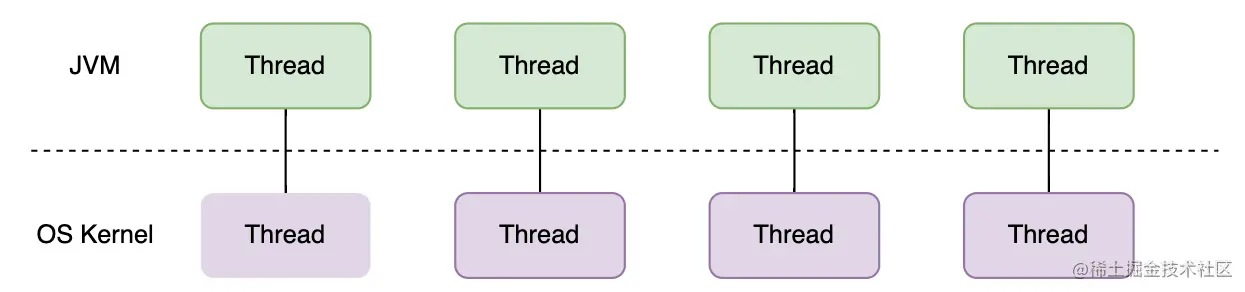
而Java19提出来的虚拟线程,与系统内核线程是1:n的关系。不过在中间有一个平台线程的概念,平台线程和之前的Java线程是一样的,仍然和内核线程一一对应。多个虚拟线程会在一个平台线程上运行。
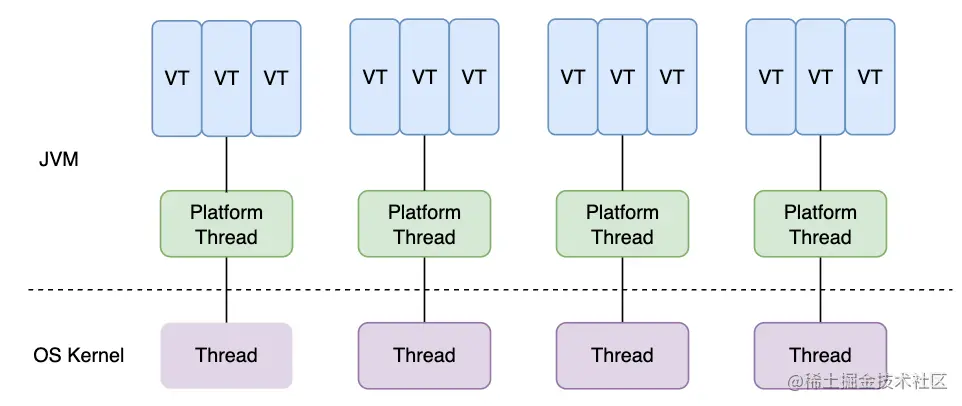
Java虚拟线程调度模式
平台线程和内核线程一一对应,受OS的调度。而虚拟线程本质是用户态线程,需要程序自身处理调度问题。
如果看过go的GMP调度模式,理解它的调度方式也会更容易。
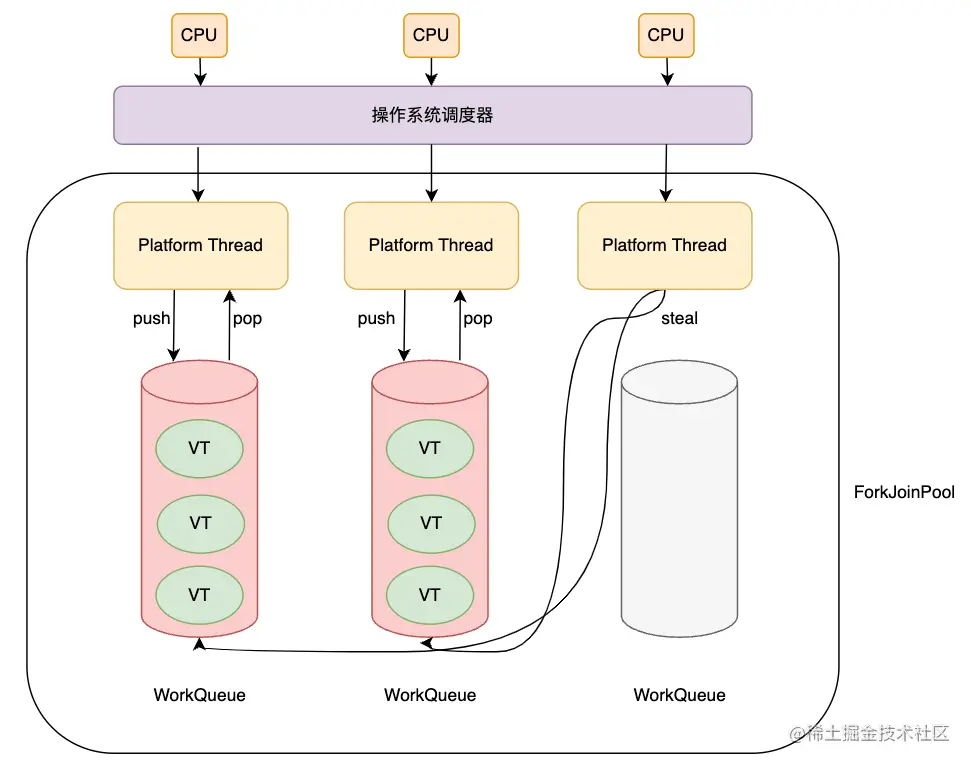
每个平台线程有自己的任务队列,调度策略采取最直接的FIFO模式,先进入队列的虚拟线程先执行,执行过程遇到阻塞操作,再执行下一个虚拟线程。同时为了避免资源利用不一致问题,实现了任务窃取模式,当一个平台线程的队列空了,可以去其他线程的队列中获取任务。
2.虚拟线程基本使用
虚拟线程的使用方式和原有线程差不多,没有什么切换成本,只不过多了一些api。
新增API
Thread.ofVirtual()和Thread.ofPlatform()是创建虚拟和平台线程的新API:
Runnable runnable = () -> System.out.println(Thread.currentThread().threadId());
Thread thread = Thread.ofVirtual().name("testVT").unstarted(runnable);
Thread testPT = Thread.ofPlatform().name("testPT").unstarted(runnable);
// 这些线程未启动,需要手动启动
testVT.start();
testPT.start();
使用Thread.startVirtualThread(Runnable)快速创建虚拟线程并启动:
Runnable runnable = () -> System.out.println(Thread.currentThread().threadId());
Thread thread = Thread.startVirtualThread(runnable);
Executors.newVirtualThreadPerTaskExecutor()创建一个 ExecutorService,该 ExecutorService 为每个任务创建一个新的虚拟线程:
static ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();
Future<String> baiduFuture = executorService.submit(() -> HttpUtil.get(baidu_url));
3.协程原理
Java的虚拟线程本质上就是协程,目前已经有很多语言支持了协程,go,c#,c++,python都有了自己的协程解决方案,可以看出协程确实是编程语言的趋势。以笔者的认知,认为实现协程最难的协程的调度,在合适的时间阻塞和唤醒协程。
协程实现方式——有栈VS无栈
有栈协程:每个协程都有自己的调用栈,类似于线程的调用栈。典型代表有Golang 中的 goroutine、Lua 中的协程、Java的虚拟线程
无栈协程:协程没有自己的调用栈,挂起点的状态通过状态机或闭包等语法来实现。典型代表有ES6的 await/async、Python 的 Generator、C++20 中的 cooroutine
:::info
有栈协程
有栈协程的一般实现是:在内存中给每个协程开辟一个栈内存,当协程挂起时会将它的运行时上下文(即栈空间)从系统栈中保存至其所分配的栈内存中,当协程恢复时会将其运行时上下文从栈内存中恢复至系统栈中。
有栈协程的栈空间一般都是在堆空间开辟的,运行时上下文切换时还是有一定的开销的。不过它的好处就是可以在函数执行的任意位置挂起协程
:::
无栈协程
与有栈协程相反,无栈协程不会为各个协程开辟相应的调用栈。无栈协程通常是 基于状态机或闭包 来实现。
基于状态机的解决方案一般是通过状态机,记录上次协程挂起时的位置,并基于此决定协程恢复时开始执行的位置。这个状态必须存储在栈以外的地方,从而避免状态与栈一同销毁。
以下面的函数为例,可以通过类似如下的方式实现挂起和恢复。从这种实现方式的角度来看,协程与函数无异,只不过前者会记录上次终端的位置,从而可以实现恢复执行的能力。当然,在实际过程中,恢复后的执行流可能会用到中断前的状态,因此无栈协程会将保存完整的状态,这些状态会被存储到堆上。
static int state = 0;
public void run(){
switch (state) {
case 0: goto LABEL0;
case 1: goto LABEL1;
case 2: goto LABEL2;
}
LABEL0:
逻辑1
LABEL1:
逻辑2
LABEL2:
逻辑3
}
上述只是一个简单的例子,具体场景中,无栈协程的控制流会依靠对协程本身编译生成的状态机的状态流来实现,变量保存也会通过闭包语法来实现。
相比于有栈协程,无栈协程不需要修改调用栈,也无需额外的内存来保存调用栈,因此它的开销会更小。但是,相比于保存运行时上下文这种实现方式,无栈协程的实现还是存在比较多的限制,最大缺点就是,它无法实现在任意函数调用层级的位置进行挂起。
4.协程性能
异步回调VS协程
在协程出现之前,Java开发者如果想要提高系统吞吐量基本是使用Future进行异步编排,其本质是一个callback函数。
:::info
异步回调:一个web请求过来,遇到阻塞的情况,比如网络调用,则注册一个回调方法(其实还包括了一些上下文数据对象)给IO调度器,当前线程就被释放了,去干别的事情了。等数据准备好,调度器会将结果传递给回调方法然后执行,自始至终都是那一个执行栈(执行线程)。但这种写法的问题就是很容易遇到callback 地狱,这种异步非阻塞api配合回调函数的写法有点反人类。程序员还是习惯同步的写法。
:::
协程方案:协程方案的思路是写代码还是按顺序写,但是遇到io等需要原阻塞等待的系统调用时候,将当前执行栈暂停,保存上下文,让出当前执行栈(执行线程,从语法上看就是yield出去,yield这个词可以看成让出当前线程的控制权),执行其它代码,等io事件完成,然后再找个线程恢复之前的上下文,继续执行。写代码时候,像同步单线程一样写,但是执行上由程序员控制线程切换,可以承受大量io情况下实现并发。
这两种方案区别在ES中体现特别明显,异步回调就类似Promise对象,通过.then和.catch来工作。而协程方案就像await/async,不会出现回调地狱。
最后,再对比一下这两种方案的性能
高吞吐量方案对比
限于笔者的知识水平,能考虑到的实际应用场景只有一次请求中需要调用多个其他接口,而且多个接口之间没有先后关系,这样就可以利用异步回调或者协程的方式提高响应速度,从而提高吞吐量。
说明:这个例子存在问题,使用的是springMVC框架,虽然发送了5000个请求来测试,但是所有用户请求都被tomcat的线程池拦住了,原则上一次只有一个请求进入到测试代码上。
另外,这种测试是存在问题的,Java现有的异步回调其实已经可以最大程度上利用硬件的性能,使用协程只是代码写起来更方便。但还是把案例保留,因为这案例至少能说明使用虚拟线程池比传统的线程池会更好一点
对比案例:通过两种方式获取百度,qq,网易官网的数据
异步回调方式:
static ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() + 2);
@Override
public String testCallback() {
CompletableFuture<String> baiduFuture = CompletableFuture.supplyAsync(() -> HttpUtil.get(baidu_url),executor);
CompletableFuture<String> qqFuture = CompletableFuture.supplyAsync(() -> HttpUtil.get(qq_url),executor);
CompletableFuture<String> wyFuture = CompletableFuture.supplyAsync(() -> HttpUtil.get(wy_url),executor);
try {
CompletableFuture.allOf(baiduFuture, qqFuture, wyFuture).get();
return baiduFuture.get()+qqFuture.get()+wyFuture.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return "fail";
}
虚拟线程方式:
static ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();
@Override
public String testVirtualThread() {
Future<String> baiduFuture = executorService.submit(() -> HttpUtil.get(baidu_url));
Future<String> qqFuture = executorService.submit(() -> HttpUtil.get(qq_url));
Future<String> wyFuture = executorService.submit(() -> HttpUtil.get(wy_url));
try {
return baiduFuture.get()+qqFuture.get()+wyFuture.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return "fail";
}
限于笔者测试资源,做了从100并发到5000并发的压力测试:
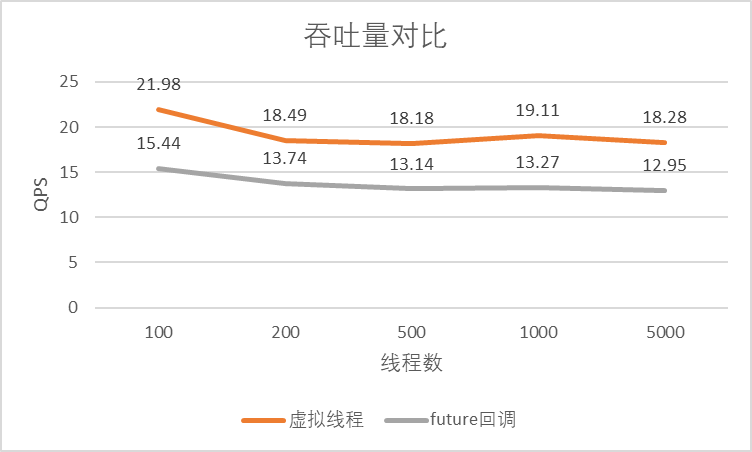
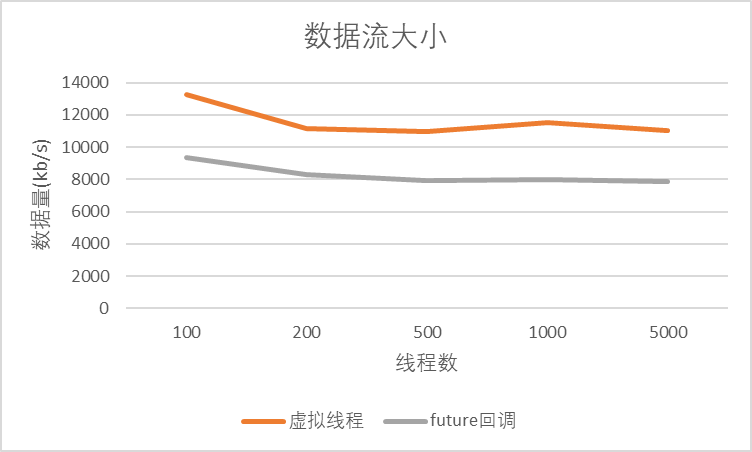
根据实验结果可以看出,Java的虚拟线程确实比使用future回调的方式吞吐量更大,对于IO密集型应用是比较合适的。
使用建议
- 原有线程池可以直接替换为虚拟线程池,创建虚拟线程池的方式可以直接使用
Executors.newVirtualThreadPerTaskExecutor() - 在一定场景下可以取消线程池机制,也不需要使用虚拟线程池,虚拟线程创建代价相比于平台线程是很低的。不过在一些连接场景,比如http连接,数据库连接,还是很有必要使用池化技术
- synchronized 改为 ReentrantLock,这是因为Java的虚拟线程运行在synchronized上无法进行阻塞和唤醒
声明
笔者技术理解有限,请辩证的看待,如发现了问题,可以一起交流下。
参考链接
https://juejin.cn/post/7145693327583608868
http://chuquan.me/2021/05/05/getting-to-know-coroutine/















 6072
6072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









