






虽然标题如此,实际的内容比较发散,均是日常需求踩坑“杰作”
背景简述
需求
我们组想监控线上项目的大数据表的数量。这些数据表分散在不同的应用上。
方案一
接到需求,脑袋一拍,就有了第一版方案:
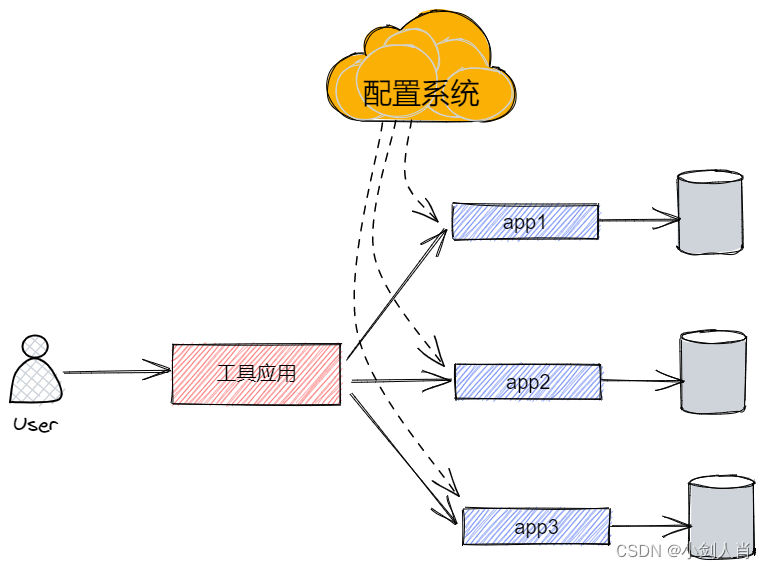
工具应用直接 http 调用需要监控的线上应用数据表,线上应用根据配置系统配置的需要监控的表,依次 count 一遍数据表就行。
这个方案很普通,看起来也没有什么问题(ps:大佬可能看出毛病来了)。不过这里我再提供一些信息。
- 我们的线上数据表有些是进行分表了的。因此一个线上应用需要监控的可能有接近 300 张表。而且每张表的数据量不是很小(很小也没有必要监控起来了),一次 count 操作大概 0.4s。
- 线上应用连接 mysql 集群默认连接数是 1,最大连接数是 20。
上面两个信息告诉我们,工具应用访问 app,或者 app 访问数据库,这两者都是一个耗时长的操作。耗时长怎么办,并发处理(ps:事实上,我的初版方案没有一点并发的痕迹,工具应用依次访问 app,app 依次 count 数据表,菜死…),或者把工具应用对 app 的 http 请求当作一个耗时作业,先提交请求,再不断轮询请求结果(ps:这也可以理解为手动异步处理)。
好了,我们就往并发的思路上走。工具应用并发调用线上 app,线上 app 并发访问数据库。不过这里还是存在一个问题,app 对 mysql 集群的最大连接数是 20,全部打满,一次请求也需要(300/20)* 0.4=6s这个时间对于 http 还是太长了,而且 app 还得响应线上流量,全部打满存在风险。
方案二
解决方案也简单,将工具应用的请求粒度缩小一点:
![![[Pasted image 20230208224348.png]]](https://img-blog.csdnimg.cn/d0638db189b448dd8ed88800bbe39ca7.png)
在工具项目中获取需要监控的数据表信息,每次访问 app 只 count 一张表,http 请求耗时就降下来了。而且访问 app 是访问它的集群,这也利用了集群的优势,会将请求负载均衡到每一台机器,访问 mysql 集群的连接数上限也扩大到 20*app集群机器数。这种“短平快”的请求也符合分布式系统的特点。
好了,我们总结一下背景。现在我的处理方式是在工具应用中并发访问线上每一个数据表,数据表量级大概在 600 左右。
踩坑之旅
问题浮现
有了上面的背景铺垫,我大致写一下这个方案的伪代码:
List<ListenableFuture<Response>> futures = new ArrayList<>();
for(配置的数据表){
futures.add(asyncHttpClient.post(url,params));
}
for(Future future : futures){
future.get(timeout)
}
逻辑很简单,但是,它报错了–java.io.IOException: Too many connections per host 200
排查原因
idea 全局搜索关键字就发现这个和项目中的配置有关: asyncHttpClient.setMaximumConnectionsPerHost(200),简单理解就是单台机器最多的 http 连接是 200。
到这里,我感觉是很奇怪的,设置一个最大连接数很正常,就相当于线程池的最大线程数量,但是怎么可以到达连接数限制就把剩下任务给拒绝了呢,这不相当于一个没有任务队列的线程池吗?我不太相信,就开始看源码。
最后看到了 com.ning.http.client.providers.netty.channel.ChannelManager #preemptChannel () 函数
public void preemptChannel(Object partitionKey) throws IOException {
if (!channelPool.isOpen())
throw poolAlreadyClosed;
if (!tryAcquireGlobal())
throw tooManyConnections;
// 这个函数是信号量的tryAcquire操作
if (!tryAcquirePerHost(partitionKey)) {
if (maxTotalConnectionsEnabled)
freeChannels.release();
throw tooManyConnectionsPerHost; // 这是我项目中抛出的异常
}
}
这个信号量的值就是配置的最大连接数量,也确实没有看到任务缓存队列,超过此限制的会抛异常。那么,为什么需要设置这么一个值呢?
Netty 线程模型
通过上面源码的类名也能知道,这个框架的底层是采用 netty 来做底层网络数据传输的。netty 是一个异步事件驱动的网络应用程序框架。
这里简单介绍一下异步事件驱动模型。借用 O’Reilly 大神关于事件驱动模型解释图
![![[Pasted image 20230214154947.png]]](https://img-blog.csdnimg.cn/a2379ccc0977428c907b944d7f18dfef.png)
主要包括了 4 个组件:
-
事件队列(event queue):接收事件,存储待处理事件
-
事件分发器(event mediator):将不同类型的事件分发给不同的事件处理器
-
事件通道(event channel):分发器和处理器的联系桥梁
-
事件处理器(event processor):处理特定事件的业务逻辑
而 netty 也有个类似的模型:
![![[Pasted image 20230214160233.png]]](https://img-blog.csdnimg.cn/f469a6588c3d44569e1d50e64066e9be.png)
-
thread/pool:使用单线程或者线程池管理 selector
-
selector:事件分发器
-
channel:事件通道,在这个 case 中,只有一种类型的 channel
-
socket:网络连接,setMaximumConnectionsPerHost 就是设置了 socket 的数量。
socket 的数量限制
socket 本质上是一个文件描述符。由【本地 IP,本地 Port,远程 IP,远程 Port】四元组限制一个唯一的 socket(有些地方会看到 UDP/TCP 协议类型作为第五个区分标识)。
对于 client 来说,每次建立连接需要系统选取一个空闲的本地端口,并且这个本地端口是独占的,这导致,一个 client 最多同时有 65536 个 socket 。
对于 server 来说,监听的本地端口是独占的,当时建立连接的本地端口可以共用,使得一个 server 理论上最多有 远程 IP(2 的 32 次方)* 远程端口(2 的 16 次方)。不过,因为 socket 本质是一个文件描述符,需要占用一定的内存,它的数量受到内存限制。不过好的机器基本能做到 10 万 socket
总结
根据上面的分析,可以看出,setMaximumConnectionsPerHost 的值可以适当调大一些,这不过是增加了 socket 数量,不过也不能太大,毕竟还有内存消耗。在进程间端口资源做好隔离的情况下,这也不会影响其他进程的。
参考链接
socket 问题:(43条消息) Windows Socket 最大连接数_hunhun1122的博客-CSDN博客
netty 模型:一文理解Netty模型架构 - 掘金 (juejin.cn)















 1060
1060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









