






项目中需要做到所发文章、评价进行敏感词过滤,用最原始的字符串循环过滤很显然效率不太行,然后查找资料看到DFA算法(有限状态机),感觉可以用来实现敏感词过滤。
原理:基于状态转移来检索敏感词,只需要扫描一次待检测文本,就能对所有敏感词进行检测,所以效率比会高一点。
假设我们有以下5个敏感词需要检测:傻逼、傻子、傻大个、坏蛋、坏人。那么我们可以先把敏感词中有相同前缀的词组合成一个树形结构,不同前缀的词分属不同树形分支,以上述5个敏感词为例,可以初始化成如下2棵树:
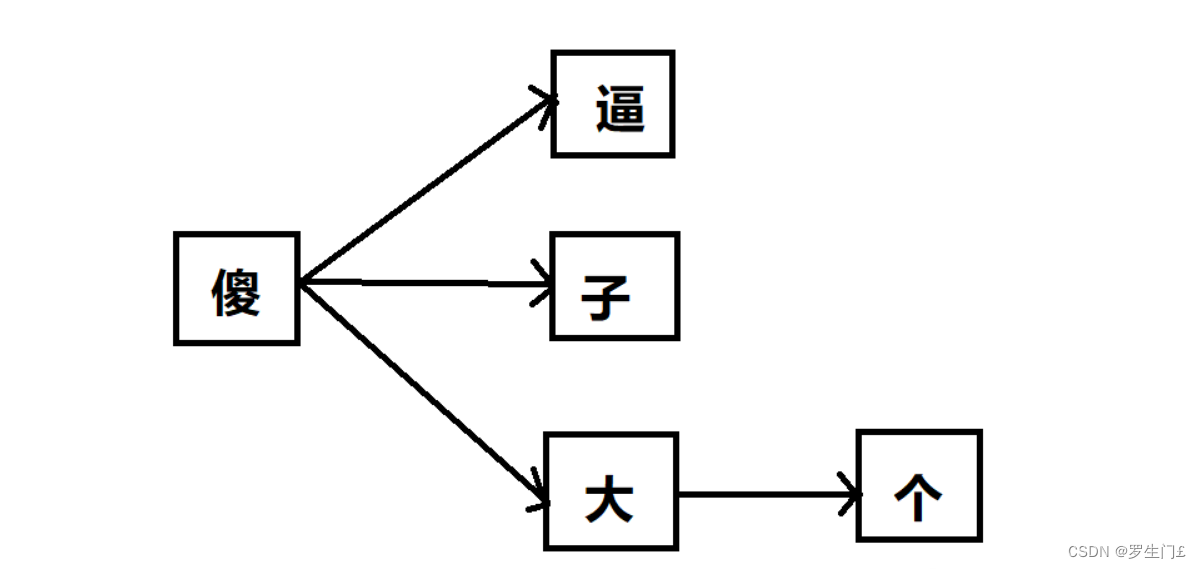
把敏感词组成成树形结构最大的好处就是可以减少检索次数,我们只需要遍历一次待检测文本,然后在敏感词库中检索出有没有该字符对应的子树就行了,如果没有相应的子树,说明当前检测的字符不在敏感词库中,则直接跳过继续检测下一个字符;如果有相应的子树,则接着检查下一个字符是不是前一个字符对应的子树的子节点,这样迭代下去,就能找出待检测文本中是否包含敏感词了。
文本“你是不是傻逼”为例,我们依次检测每个字符,因为前4个字符都不在敏感词库里,找不到相应的子树,所以直接跳过。当检测到“傻”字时,发现敏感词库中有相应的子树,我们把他记为tree-1,接着再搜索下一个字符“逼”是不是子树tree-1的子节点,发现恰好是,接下来再判断“逼”这个字符是不是叶子节点,如果是,则说明匹配到了一个敏感词了,在这里“逼”这个字符刚好是tree-1的叶子节点,所以成功检索到了敏感词:“傻逼”。大家发现了没有,在我们的搜索过程中,我们只需要扫描一次被检测文本就行了,而且对于被检测文本中不存在的敏感词,如这个例子中的“坏蛋”和“坏人”,我们完全不会扫描到,因此相比方案一效率大大提升了。
在Java中,我们可以用HashMap来存储上述的树形结构,还是以上述敏感词为例,我们把每个敏感词字符串拆散成字符,再存储到HashMap中,可以这样存:
{
"傻": {
"逼": {
"isEnd": "Y"
},
"子": {
"isEnd": "Y"
},
"大": {
"个": {
"isEnd": "Y"
}
}
}
}
首先将每个词的第一个字符作为key,value则是另一个HashMap,value对应的HashMap的key为第二个字符,如果还有第三个字符,则存储到以第二个字符为key的value中,当然这个value还是一个HashMap,以此类推下去,直到最后一个字符,当然最后一个字符对应的value也是HashMap,只不过这个HashMap只需要存储一个结束标志就行了,像上述的例子中,我们就存了一个{“isEnd”,“Y”}的HashMap,来表示这个value对应的key是敏感词的最后一个字符。同理,“坏人”和“坏蛋”这2个敏感词也是按这样的方式存储起来。
最后,附上代码实现
最终项目中,将敏感词存到数据库中,然后在初始化的时候放到Redis中,这样也不用每次查询数据库了。
package org.Angle.util;
import org.Angle.Main;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.*;
/**
* 敏感词检测,敏感词数据放在资源目录下
*
* String text="这是一篇测试的文章de1,标题是,努儿力成就幸福人生(傻子),内容是:今天是周日,阳光明媚,**去郊游。碰到";
* System.out.println(getSensitiveWords(text, Check.MatchType.MAX_MATCH));
*
* @author:
* @date: 2023年09月15日 9:47
*/
public class Check {
// 初始化
public static Map<Object, Object> sensitiveWordsMap;
public static final String END_FLAG = "end";
//初始化敏感词数据
public static void initSensitiveWordsMap() {
Set<String> sensitiveWords = new HashSet<>();
String filePath = Main.class.getClassLoader().getResource("SensitiveWords.txt").getPath();
// 先读取文件
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = reader.readLine()) != null) {
sensitiveWords.add(line);
}
System.out.println(sensitiveWords);
} catch (Exception e) {
e.printStackTrace();
}
if (sensitiveWords == null || sensitiveWords.isEmpty()) {
throw new IllegalArgumentException("Senditive words must not be empty!");
}
sensitiveWordsMap = new HashMap<>(sensitiveWords.size());
String currentWord;
Map<Object, Object> currentMap;
Map<Object, Object> subMap;
Iterator<String> iterator = sensitiveWords.iterator();
while (iterator.hasNext()) {
currentWord = iterator.next();
if (currentWord == null || currentWord.trim().length() < 1) { //敏感词长度必须大于等于2
continue;
}
currentMap = sensitiveWordsMap;
for (int i = 0; i < currentWord.length(); i++) {
char c = currentWord.charAt(i);
subMap = (Map<Object, Object>) currentMap.get(c);
if (subMap == null) {
subMap = new HashMap<>();
currentMap.put(c, subMap);
currentMap = subMap;
} else {
currentMap = subMap;
}
if (i == currentWord.length() - 1) {
//如果是最后一个字符,则put一个结束标志,这里只需要保存key就行了,value为null可以节省空间。
//如果不是最后一个字符,则不需要存这个结束标志,同样也是为了节省空间。
currentMap.put(END_FLAG, null);
}
}
}
}
// -------------------
public static enum MatchType {
MIN_MATCH("最小匹配规则"), MAX_MATCH("最大匹配规则");
String desc;
MatchType(String desc) {
this.desc = desc;
}
}
public static Set<String> getSensitiveWords(String text, MatchType matchType) {
// 调用初始化文件
initSensitiveWordsMap();
if (text == null || text.trim().length() == 0) {
throw new IllegalArgumentException("The input text must not be empty.");
}
Set<String> sensitiveWords = new HashSet<>();
for (int i = 0; i < text.length(); i++) {
int sensitiveWordLength = getSensitiveWordLength(text, i, matchType);
if (sensitiveWordLength > 0) {
String sensitiveWord = text.substring(i, i + sensitiveWordLength);
sensitiveWords.add(sensitiveWord);
if (matchType == MatchType.MIN_MATCH) {
break;
}
i = i + sensitiveWordLength - 1;
}
}
return sensitiveWords;
}
public static int getSensitiveWordLength(String text, int startIndex, MatchType matchType) {
if (text == null || text.trim().length() == 0) {
throw new IllegalArgumentException("The input text must not be empty.");
}
char currentChar;
Map<Object, Object> currentMap = sensitiveWordsMap;
int wordLength = 0;
boolean endFlag = false;
for (int i = startIndex; i < text.length(); i++) {
currentChar = text.charAt(i);
Map<Object, Object> subMap = (Map<Object, Object>) currentMap.get(currentChar);
if (subMap == null) {
break;
} else {
wordLength++;
if (subMap.containsKey(END_FLAG)) {
endFlag = true;
if (matchType == MatchType.MIN_MATCH) {
break;
} else {
currentMap = subMap;
}
} else {
currentMap = subMap;
}
}
}
if (!endFlag) {
wordLength = 0;
}
return wordLength;
}
}
树结构yyds















 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









