







第二章
云计算目标
- 海量数据存储
- 快速处理
- 百万廉价计算机协同工作
2.1 Google文件系统GFS
文件分布式系统,采用廉价的商用机器构建,对硬件设施要求不高。
系统架构

GFS将整个系统节点分为三类角色:
- Client(客户端):Client是GFS提供给应用程序的访问接口,以库文件的形式提供。
- Master(主服务器):Master是GFS的管理节点,负责整个文件系统管理。
- Chunk Server(数据块服务器):Chunk Server负责具体的存储工作,以块存储数据,每一个块都有一个索引。
GFS的实现机制:
- Client访问Master从而获取交互的Chunk Server信息,然后访问Chunk Server,完成数据存取
- 控制流与数据流分离。
- Client与Chunk Server之间直接传输数据流,同时由于文件被分成多个Chunk进行分布式存储,Client可以同时访问多个Chunk Server,从而使得整个系统的I/O高度并行,系统整体性能得到提高。
特定:
- 采用中心服务器模式:
- 可以方便的增加与去除Chunk Server
- Master掌握系统内所有Chunk Server的情况,方便进行负载均衡
- 不存在元数据的一致性问题
- Master从医成为系统性能的瓶颈
- 不缓存数据:
- 必要性:客户端大部分是流式顺序读写,不存在大量重复;Chunk Server上数据以文件形式存储,本地的文件系统自然会将其缓存
- 可行性:维护存储与缓存的方法难以实现
- 在用户态下的实现
- 提高通用性
- 功能更为丰富
- 调试方便
- 只提供专业的接口
- 降低实现难度
容错机制
Master容错:Mater中保存了GFS文件系统的三种元数据:
- 命名空间,文件系统的目录结构
- Chunk与文件名的映射表
- Chunk副本的位置信息,每一个Chunk默认有三分副本
当Master发生故障时,在磁盘数据保存完好的情况下,可以迅速恢复以上元数据
为了防止Master彻底死机的情况,GFS还提供了Master远程的实时备份
Chunk Server容错:
- 采用副本的方式来实现Chunk Server容错。每一个Chunk有多个存储副本。
- 每一个Chunk只有全部写入成功才视为成功写入。
- 相关的副本如果丢失或不可恢复,Master自动将副本复制到其他Chunk Server
- 一个文件被划分为多个块,每一个快都有一个32bit的校验和。
系统管理技术
- 大规模集群安装
- 故障检测技术
- 动态节点加入
- 节能
2.2 MapReduce分布式数据处理
背景:在大规模数据集运行过成功传统式分布式程序设计相比,MapReduce封装了并行处理、容错处理、本地化计算、均衡负载等细节。把对大数据的大规模操作,风阀给一个主节点管理下的各分节点共同完成。 Map(映射),Reduce(规约)。
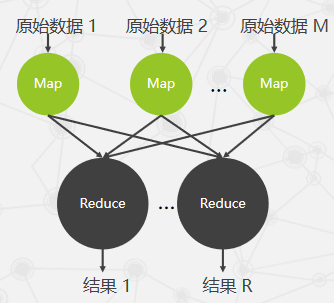
Map函数:对一部分原始数据进行指定的操作,每个Map操作都针对不同的原始数据,因此Map与Map之间是相互独立的,使得他们可以充分并行化。
Reduce操作:对每一个Map所产生的一部分中间结果合并操作,每个Reduce所处理的Map中间结果是互不交叉的,所有Reduce产生的最终结果经过简单连接就形成了完整的结果集。

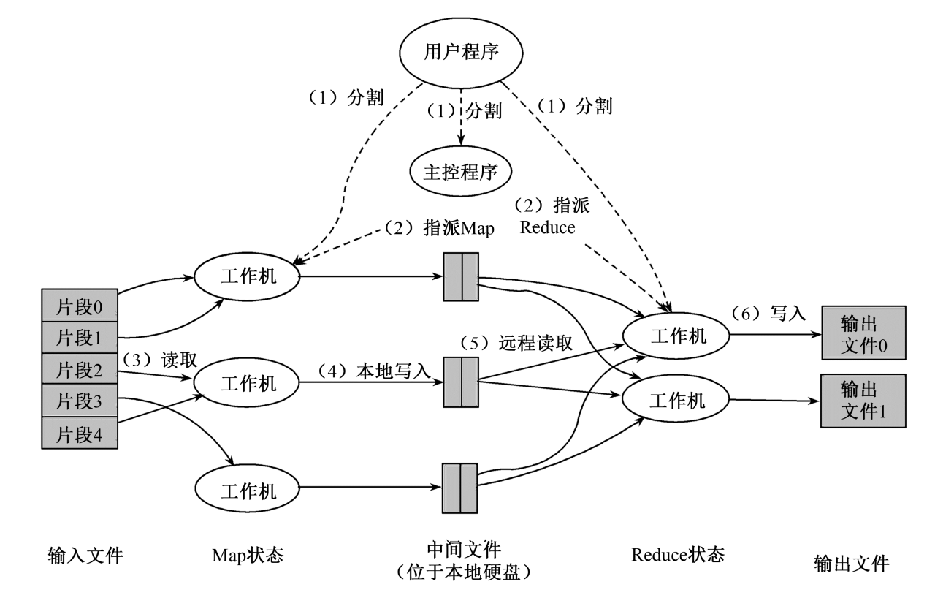
实现机制
















 9703
9703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









